So far, we have looked at minimum phase and linear phase examples of one basic kind of filter, but everything I’ve shown you are just examples. There are other filters (I could be showing you shelving filters instead of peaking filters – which would be a through-put plus a low- or high-pass instead of a bandpass) and other implementations (for example, there are other ways to make a linear phase filter).
We won’t go through these other versions because we’re not here to learn how to make filters, we’re here to learn why, when someone asks you “which is better, minimum-phase or linear phase?” or “aren’t you worried about the unnatural effects of pre-ringing?” you can answer “it depends” (which is almost always the correct answer for any question related to audio).
At this point you should know that
- a filter that changes the frequency response also changes the time response. This is unavoidable.
- some filters will also ‘pre-ring’ ahead of the sound
- a filter may or may not have an effect on the phase of the signal
- If you’re designing (or choosing) a filter, nothing comes for free. (For example, if you want linear phase, the price is latency. There are other prices attached to other design decisions.)
The question that we have not yet addressed is “so what?”
This is the point in the discussion where things are going to get a little fuzzy… Hang on!
You probably read somewhere that human hearing extends from 20 Hz to 20 kHz, therefore anything outside that range is not audible. This is not true. You might have read a little farther where they added an extra detail saying something about your age: the older you are, the lower that top number gets. That might be true.
You can also read that the quietest sound you can hear has a sound pressure level of 20 µPa, which is equivalent to 0 dB SPL, and that the loudest sound you can “hear” (over the sound of your screams of pain) is about 120 dB SPL or so. You might have also read a little farther where they added an extra detail that points out that this is only at 1 kHz. But this is probably also not true.
There are many reasons why all of those numbers are basically meaningless – but the main one is that they’re numbers based on averages. Imagine if an optometrist only carried one strength of glasses, which happened to be the average of the prescriptions required by all of his or her patients. We’d all be tripping over out own feet, and getting blinding headaches caused by wearing the wrong glasses.
Actually, a similar point was once proven by the American Air Force. They wanted to design the perfect airplane cockpit, so they measured all their pilots, averaged all the numbers, and built a seat for the result. Of course, the result was that the seat fit no one, since there was no single person that matched the average.
There are other examples that prove that averages are useless information. For example, I have more than the average number of legs. Also, since one in every three mammals on the earth is a bat, if I have meeting with two other people, one of us must be Batman…
Of course, the message is that we’re all different. For example. I don’t taste things very well. I don’t understand people who talk about the various elements in the taste of wine. All I know is that it’s drinkable, or it’s good for putting on fish & chips. When I eat food, I tend to put on pepper and chill so that I can at least taste something…
Hearing is the same: so all of the stuff I’m about to say is based on averages, which may or may not apply to you. You might be more or less sensitive than the average. Don’t email me to argue about the numbers I’m using here. You’re different. I know… We all are…
Psychoacoustic Masking
Let’s go to an AC/DC concert together. Halfway through You Shook Me (All Night Long), I’ll whisper a secret code word into your left ear. Then, you whisper it back to me.
This exercise will not work. You won’t hear me, which is strange because the changes in air pressure that I’m making by whispering are exactly the same as when AC/DC is not playing – and normally, you’d be able to hear that. Also, your eardrum is wiggling in exactly the same way as a result of that whispering – it also happens to be wiggling to the AC/DC more. So, why can’t you hear me?
The answer lies in your brain. It decides that I’m not as important as AC/DC, so the signal is thrown out as being irrelevant, and so the sound my my whispering is ‘psychoacoustically masked’ by AC/DC. Notice the ‘psycho-‘ part of that, which is the indication that the acoustic masking is happening in your brain, not as a result of a mechanical or physical issue.
This probably doesn’t come as a surprise – at some point in your life, you’ve probably been somewhere where you’ve asked someone to speak up because you can’t hear them over the noise. You’ve been the victim of the limitations of your own brain.
Temporal Masking
What might come as a surprise is that this effect also works when the loud sound (AC/DC) and the quiet sound (me whispering) don’t happen simultaneously.
For example, let’s say that you are getting your photo taken by someone with a flash camera. You’re looking right at the camera, and the flash goes off. For a short while after that, you can’t see anything but the leftover spot in the middle of your vision. If, right after the flash, someone were to hold up some number of fingers and ask “how many fingers?”, you’d have to guess. (This is only an analogous example; the spot in your eyes is not happening in your brain, but the effect is similar.)
Similarly, if I were to fire a gun (not at you… don’t worry), and quickly whisper a word immediately afterwards, you wouldn’t hear the whisper. The gunshot and the whisper didn’t happen simultaneously, but there is temporal masking that causes you to not hear the quieter sound for a little which after the loud sound has happened.
Even weirder, there is an effect called pre-masking. If I were REALLY quick and VERY well-timed, I could whisper the word right BEFORE the gunshot and you also wouldn’t hear it. The loud sound (the gun shot) not only masks quiet sounds that come after it, but also sounds that come before it.
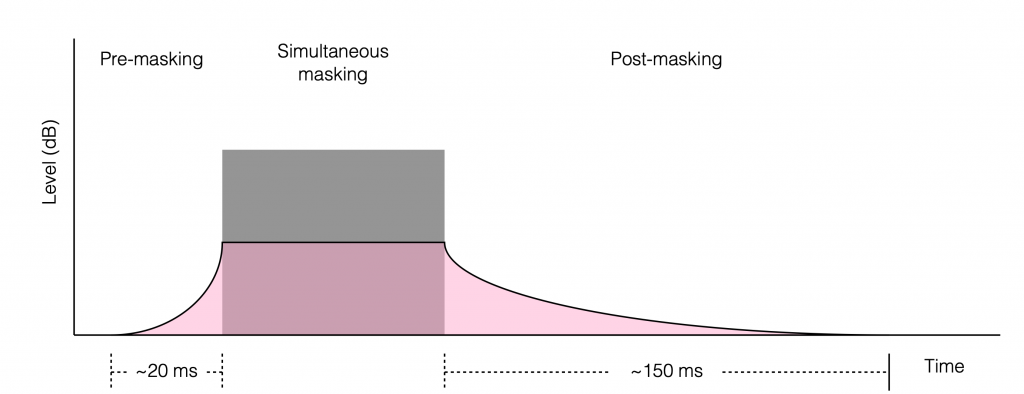
So, if I were to play a loud noise (a gunshot, a blast of pink noise, a portion of an AC/DC song) and play a quiet sound before, during, or afterwards, and ask what the quiet sound was (to test if you heard it) your behaviour will match something like the plot in Figure 1. The gray block represents the loud sound. Anything in the pink shape is “stuff you can’t hear”. If the quiet sound occurs much earlier or much later than the loud sound, then it will have to be really quiet for you to not hear it. The closer in time the quiet sound occurs to the loud sound, the louder it has to be for you to hear it.
Of course, this is very general plot, so don’t use it for arguments while you’re drinking beer with your friends. For example, one element that I have not mentioned is frequency content. If the loud sound is the low frequency effects of a recording of distant thunder, and the quiet sound is a kitten mewing, then these two sounds are too far apart in frequency to have any influence on each other, and the graph is just plain wrong.
Signal Envelope
Unless you, like me, spend a lot of time listening to sinusoidal tones, you’ll notice that everything you listen to varies in level over time. This happens on different time scales. The sound pressure level (SPL) in the car while you’re driving to work or at the daycare picking up the kids is much louder than the SPL in your bedroom while you’re dealing with the free-floating existential anxiety that comes to visit at 2:00 in the morning. This is the ‘slow’ time scale. On the ‘fast’ end of the time scale, you have the extreme, and short SPL cause by closing a car door, or the very short, but not very loud sound of a high heel impacting a hardwood or tiled floor. Speech is somewhere in between these two. There are short, spikes caused by “t-” and “k-” sounds, and long-ish portions produced by vowels.
Note that we’re not really talking about how loud or how quiet things are. We’re talking about the change in level from quieter to louder and back again.
If we plot that change over time, we have a view of the signal’s envelope. For example, a single note on a piano has a fast attack (from quieter to louder) and a slow decay (from louder to quieter). A car horn honked in an open area (not a city intersection, where there are buildings to reflect the sound) has almost identical attack and decay envelopes.
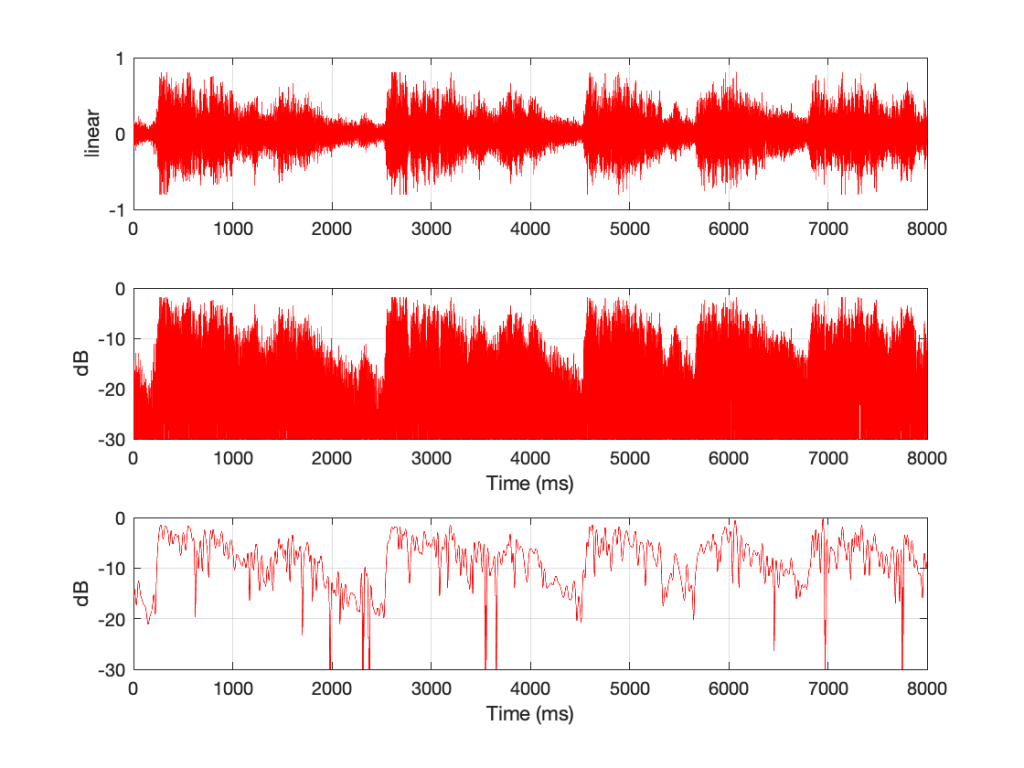
Figure 1 shows an 8-second slice of a recording of the Alleluia Chorus from Handel’s “Messiah”, chosen because it’s easy for me to load that into Matlab using the “load handel” command, and I’m very lazy.
The top plot shows the signal in the way we’re used to looking at sound files. The x-axis is time, in ms. The Y-axis shows the linear value of each of the samples. Oddly, this is the way we normally look at sound files, but it represents how we hear sound very poorly, because we don’t hear amplitude linearly.
So, in the middle plot, I’ve taken the same data and, sample-by-sample, plotted each value on a decibel scale (using the equation DisplayOutput = 20*log10(abs(signal)). The absolute value is there because calculating the log of a negative number gives you strange results)
The third plot is the one we’re really interested in. That’s created by connecting the peaks in the middle plot, which results in a running plot of the signal’s level over time. This is its envelope. As you can see in that particular musical example, the attacks (the changes from quieter to louder) are steeper (and therefore faster) than the decays. This is not surprising. It’s hard to get an orchestra and choir to all stop instantaneously…
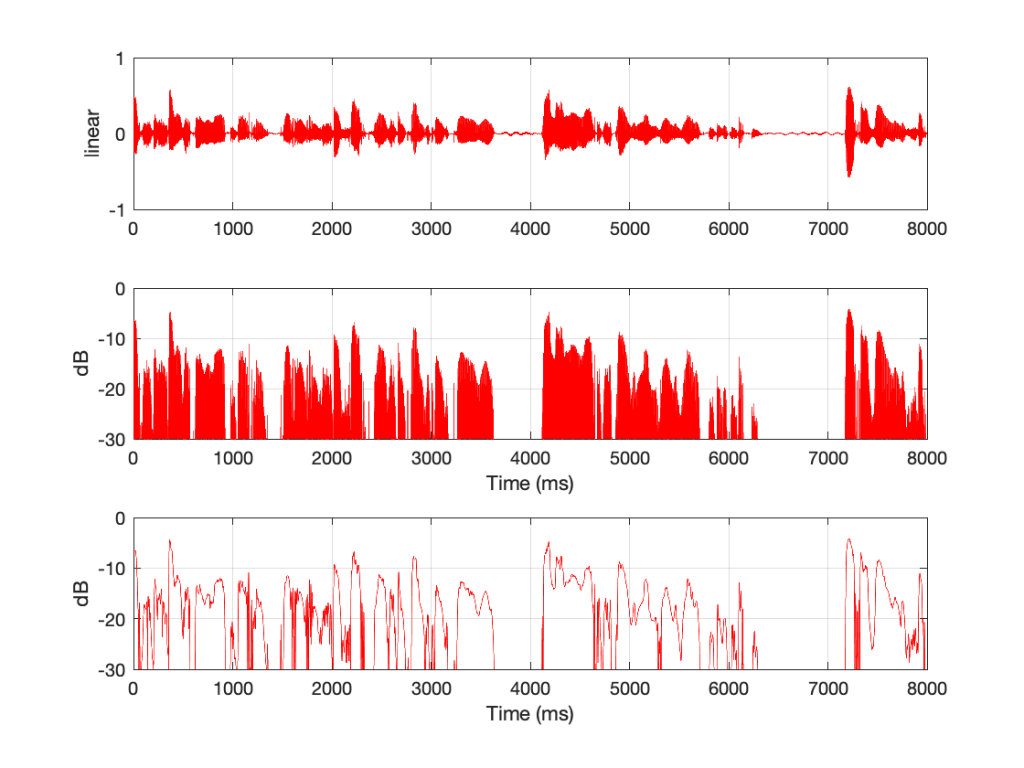
Figure 2 shows the same three ways of plotting an audio signal, but in this case, the signal is female speech recorded in an anechoic chamber. Notice that, partly because it’s only one sound source and partly because there is no reverberation in the signal, the decays are almost as fast as the attacks. However, this is a very strange recording. Most people don’t listen to anything in an anechoic chamber, and we don’t typically go to the middle of a football field or a frozen lake to have a conversation.
Back to the “so what?”
Let’s assemble the three collections of information that we’ve been throwing around.
Firstly, focusing on filter response:
- We know that filters can ring.
- We also know that some filters can pre-ring.
- We also know that, unless the Q is really high, that ringing decays pretty quickly.
- Finally, we know that, if the frequency that’s ringing in the filter is not present in the signal, it won’t ring because there’s nothing there to ring. (Similarly if you turn up the low bass while listening to a solo piccolo recording, you won’t hear a difference because there’s no bass to boost.)
Secondly, we looked at our own response to quiet and loud signals in time
- A loud sound will simultaneously mask a quiet sound that occurs at the same time (fancy-talk for “drown it out so I can’t hear it)
- The loud sound will also post-mask a quiet sound that occurs after within a short time window (on the order of 100 – 200 ms)
- The loud sound will also pre-mask a quiet sound that occurs before it within a short time window (on the order of 10 – 20 ms)
Finally, we looked at signal envelopes – the change in level of an audio signal over time
- Sounds never start instantaneously. In order to do so, they would have to have an infinite frequency range measured at the receiver (e.g. your eardrum, which is most certainly band-limited as well). Even very fast attacks take milliseconds to ramp up.
- Sounds in real life have longer decay times
- I know, I know, you can name sounds that have very fast attacks (e.g. the pluck of a harpsichord plectrum on a high string, or a single xylophone bar struck in an anechoic environment) and very fast decays (ummm…. good luck finding something that decays more than 100 dB in less than 100 ms…)
The question is: if you have a filter that rings or pre-rings, and you apply it to a sound,
- Is that ringing the thing that defines the envelope of the resulting sound? In other words, does the signal’s attack and/or decay envelope change significantly as a result of the time response of the filter?
- Is that change in the envelope outside the limits of your ability to detect it due to pre-masking and post-masking?
There is no single answer to this question. If the audio signal is someone hitting a rim shot, and the filter is a peak filter with 12 dB of gain at 500 Hz with a Q of 100, then you’ll hear it ringing. In fact, it will sound like a rim shot with a sine wave generator. If the audio signal is a single bowed note on a ‘cello, and the filter is a dip filter with -3 dB of gain at 100 Hz with a Q of 0.707, then you won’t.
However, (for example) you CANNOT automatically jump to a conclusion that “pre-ringing sounds unnatural” because that starts with the assumption that you can hear it, and therefore it sounds “like” anything.
Whether or not you can hear the effects of a filter applied to an audio signal is dependent not only on the very specific characteristics of the filter, but its interaction with the signal. Change the filter OR change the signal, and the result will change.
This means that you CANNOT say things like “linear phase filters are better (or worse) than minimum phase filters” or “the pre-ringing of a linear phase filter sounds unnatural” because both of those statements start with the (possibly incorrect) assumption that you can hear the effect of the filter.
Now, don’t mis-interpret what I’ve said to mean “you can’t hear a filter ringing” – I didn’t say that. What I said was “just because a filter can be measured to be ringing doesn’t necessarily mean that you can hear it with a given audio signal”.