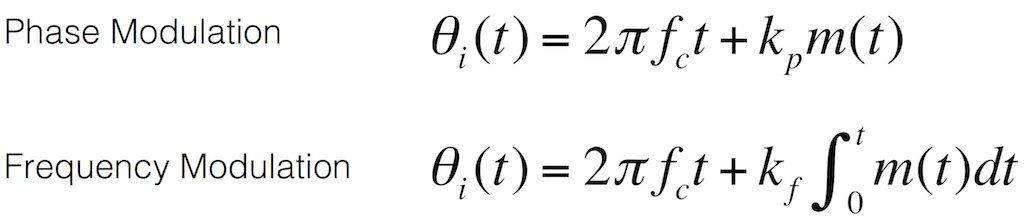In the previous post we looked at the effect of an incoming analogue signal that is sampled at the wrong times. In that description, I implied that the playback of the samples would happen at exactly the correct times. So, the jitter was entirely at the ADC (analogue-to-digital converter) and nowhere else.
In this posting, we’ll look at a very similar issue – jitter in the DAC (digital-to-analogue converter).
Jitter in the Digital to Analogue conversion
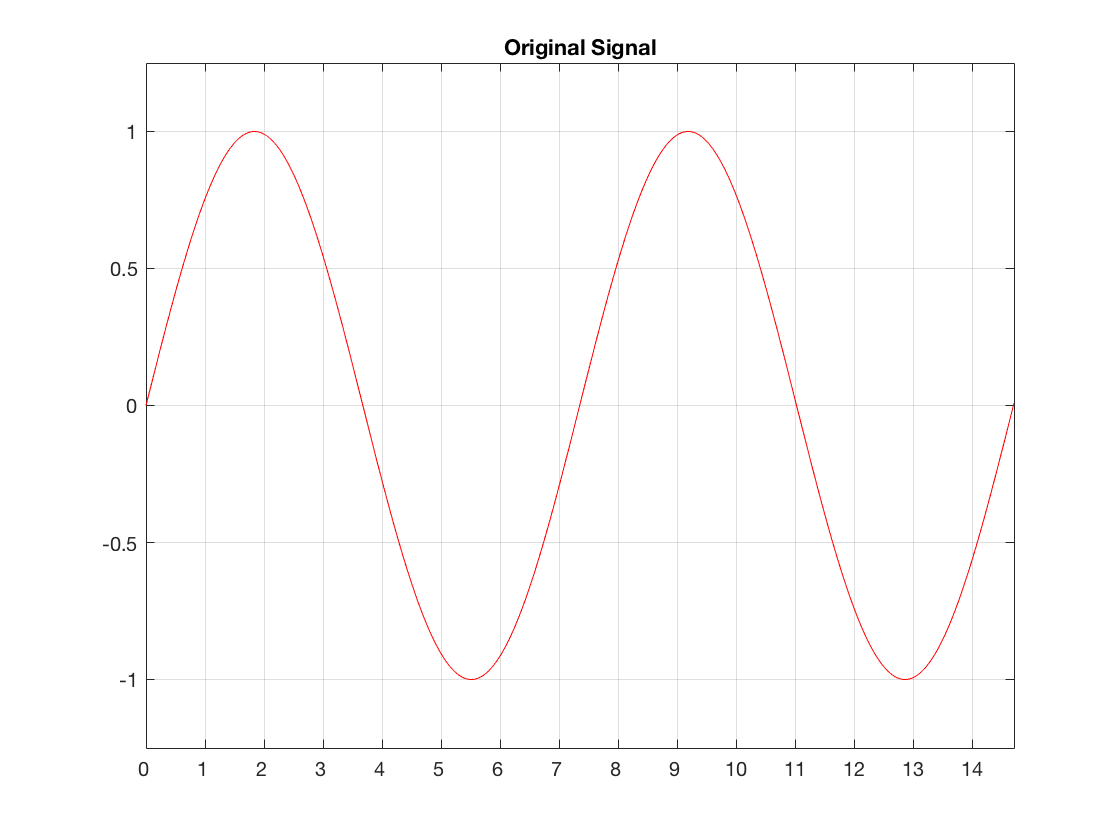
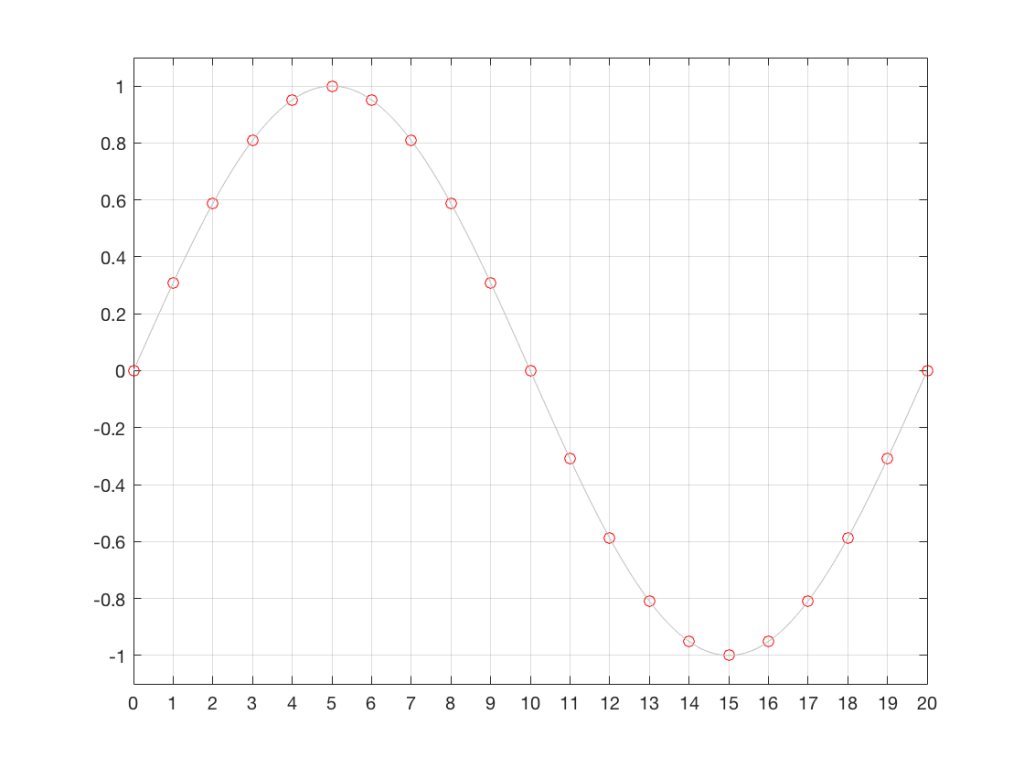
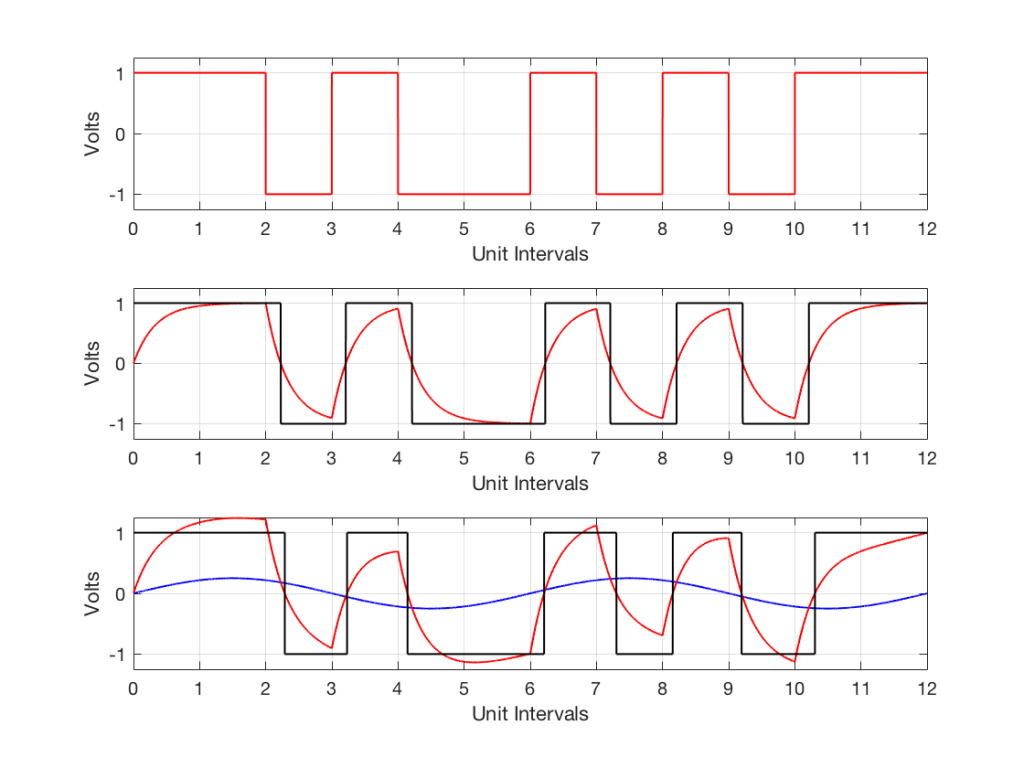
Let’s assume that we have a signal (in our case, a sinusoidal waveform, since that’s easy to plot) that was sampled by an ADC with no jitter. So, our original signal looks like Figure 1.
Fig 1. The original waveform. The x-axis shows time, divided into the sample times when we’re doing the measurements of the signal.
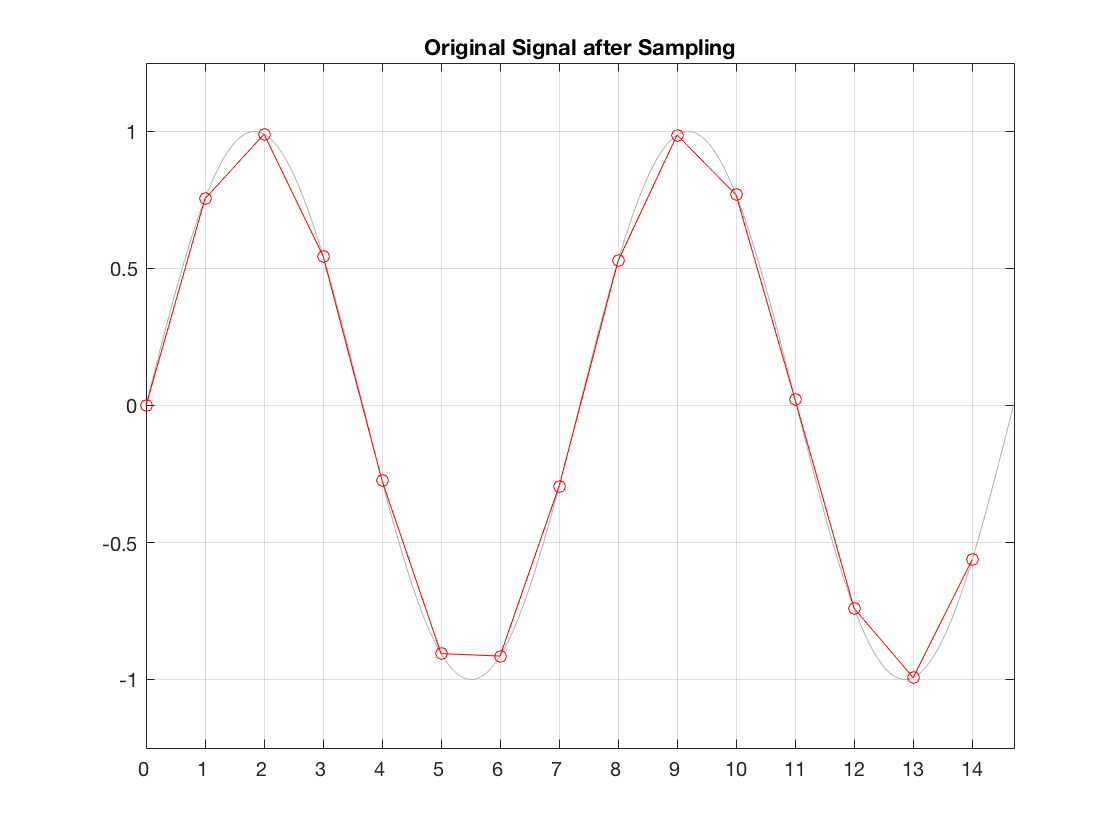
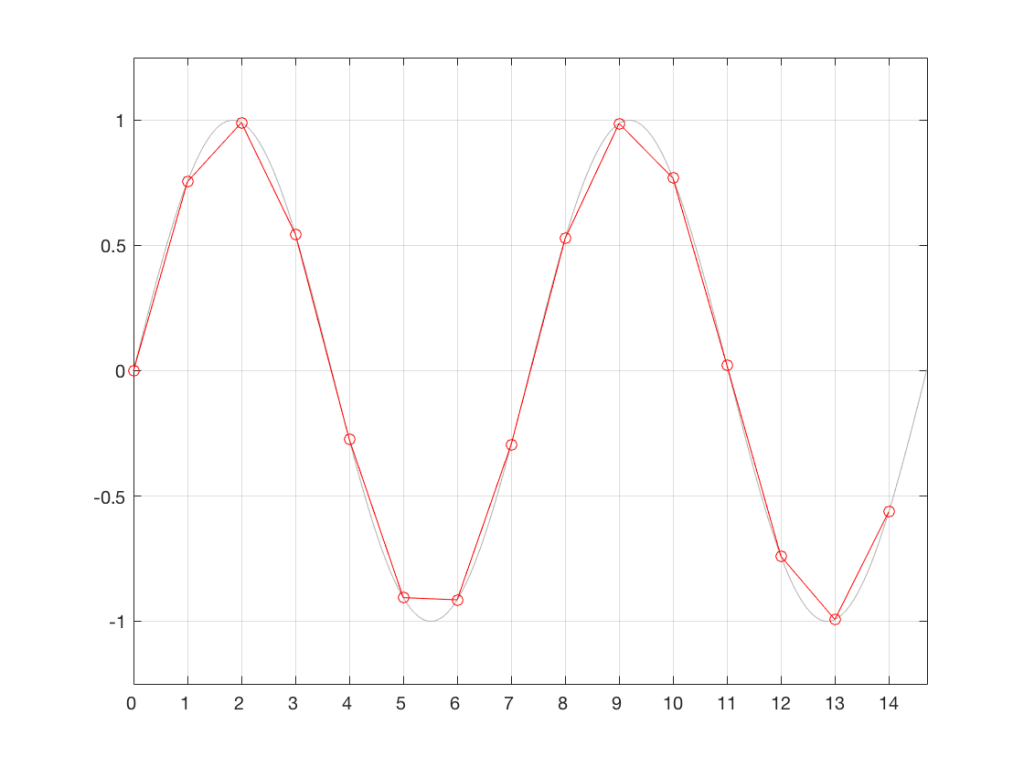
That signal is sampled by the ADC at exactly the correct times, since it has no jitter. The result of this is shown below in Figure 2.
Fig 2. The original waveform (in gray) and the samples that are measured by the ADC.
When the time comes to play this signal, we send those samples to the DAC in the correct order and hope that it converts each of them to an analogue voltage at exactly the correct times. If the sampling rate of the system is 96 kHz, then we hope that the DAC converts a sample ever 1/96000th of a second, at exactly the right time each time.
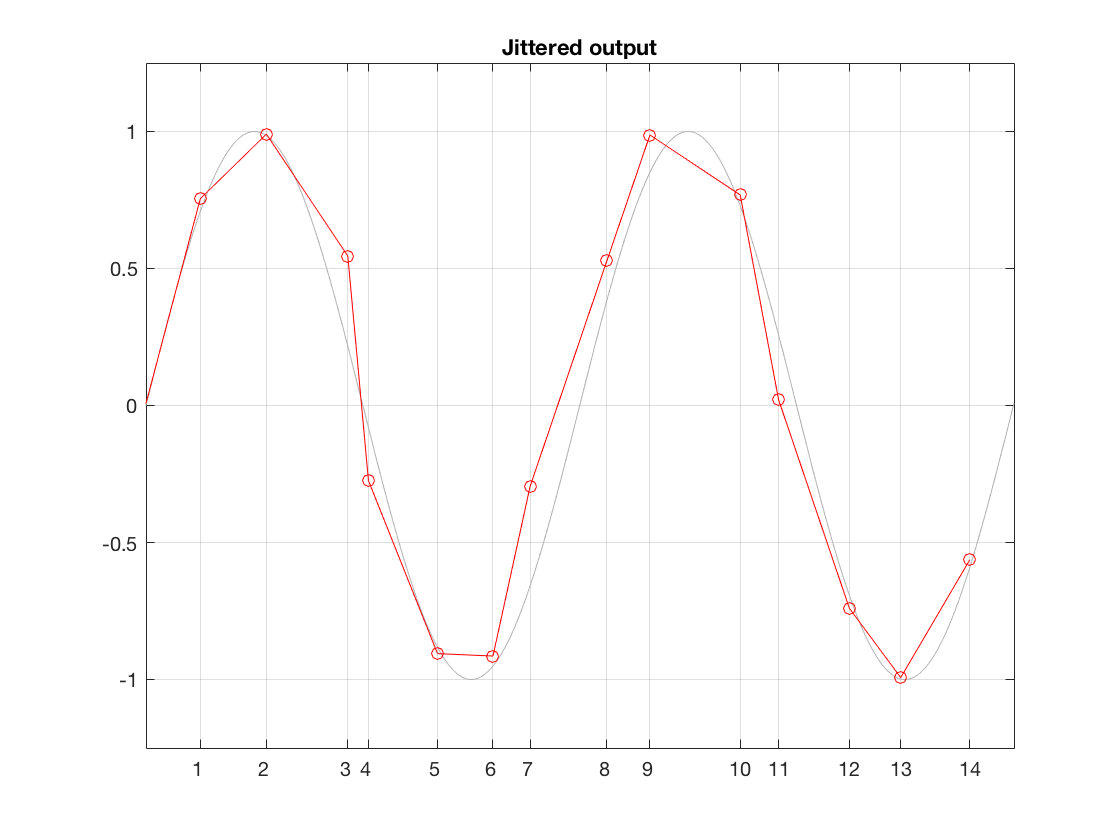
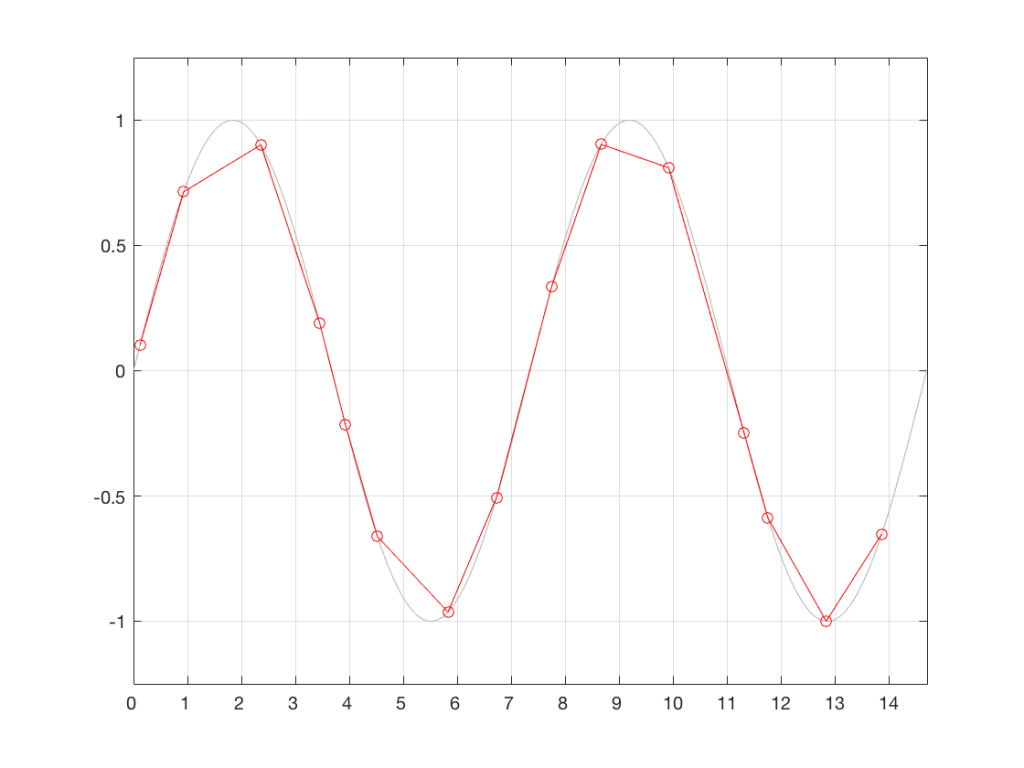
That time that the DAC spits out the sample is dictated by a clock somewhere in the system. It might by an internal clock, or it might come from an external device, depending on your system and how it’s being used. However, if that clock is inaccurate for some reason, or if there is some kind of noise infecting the connection between the clock and the DAC, then the DAC can be triggered to convert a sample at the incorrect time. This is sampling jitter in the digital to analogue conversion process. I’ve tried to illustrate this in Figure 3.
Fig 3. An illustration of jitter at the digital to analogue conversion process. Notice that the times between consecutive samples is not consistent.
It may not be immediately obvious, but the sample values in Figure 3 are identical to those in Figure 2. What I’ve done is to move them in time, so that you’re getting exactly the right level output at the wrong time each time. Of course, I have heavily exaggerated this plot to make it obvious that the times between consecutive samples are not equal. Some are much shorter than the sampling period (e.g. between samples 3 and 4) and some are much longer (e.g between samples 9 and 10).
Just like the case of ADC jitter, we can analyse this simply as an amplitude error. In other words, as a result of the timing errors, the red circles are not sitting directly on the original gray signal. And, just like we saw in the case of the ADC jitter, the amount of amplitude error is proportional to the slope of the signal.
Addendum: It’s important to remember that the descriptions and the plots that I’m showing here are to help show what jitter is – and those plots are high. I’m not showing what the final result will be. The actual jitter in a system is much, much lower than anything I’ve shown here. Also, I’ve completely omitted the effects of the anti-aliasing filter and the reconstruction filter – just to keep things simple.
Ignoring a most of the details, converting an analogue audio signal into a digital one is much like filming a movie. The signal (a continuous change in voltage) is measured (or sampled) at a regular rate (the sampling rate), and those measurements are stored for future use. This is called Analogue-to-Digital Conversion.
In the future, you take those samples, and you convert them back to voltages at the same sampling rate (in the same way that you play a film at the same frame rate that you used to record it). This is called Digital-to-Analogue Conversion.
However, we’re not here to talk about conversion – we’re here to talk about jitter in the conversion process.
As we’ve already seen, jitter (and wander) is an error in the timing of a clock event. So, let’s look at this effect as part of the sampling process. To start: jitter in the analogue to digital conversion.
Jitter in the Analogue to Digital conversion
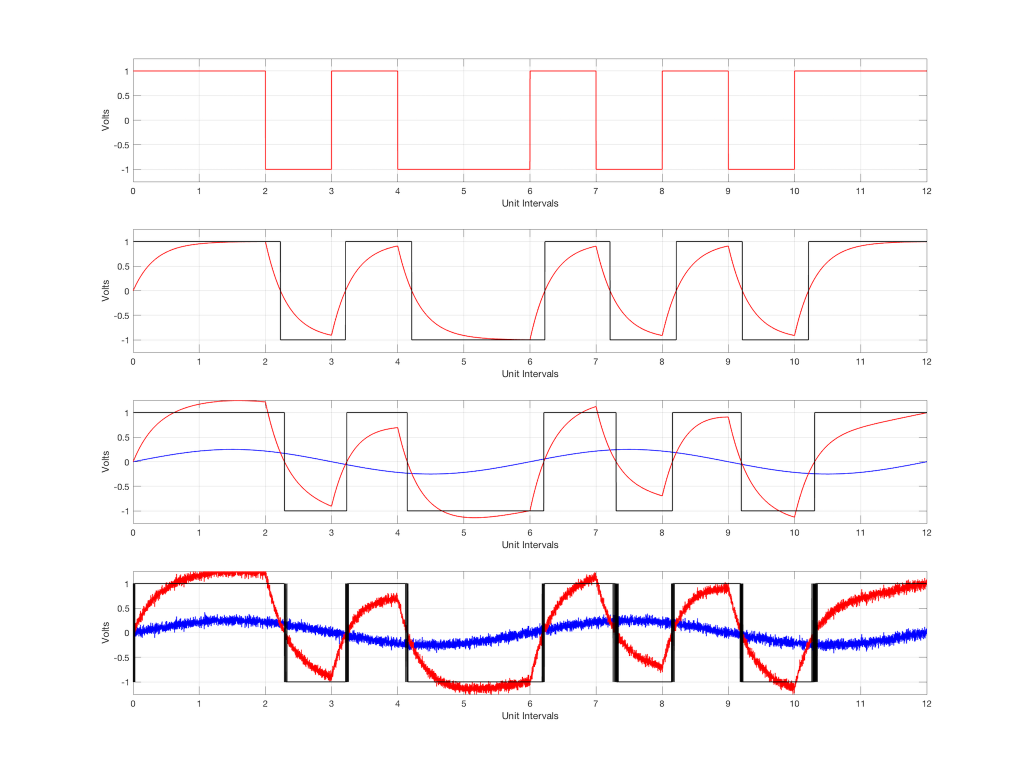
Let’s say that we want to convert an analogue sinusoidal wave into a PCM digital version.
Note that I’m going to skip a bunch of steps in the following explanation – concentrating only on the parts that are important for our discussion of jitter.
We start with a wave that has theoretically infinite resolution in amplitude and time, and we divide time into discrete moments, represented by the numbered vertical lines in the plot below.
Fig 1. An analogue sinusoidal wave, about to be sampled in the first step to conversion into an LPCM audio signal.
Every time the clock “ticks” (in other words, on each of those vertical lines), we measure the voltage of the signal. These discrete measurements are represented in Figure 2 as the circles, sitting on the original waveform (in gray).
Fig 2. The intantaneous amplitude of the original waveform (in gray) is measured at each discrete moment in time.
Part of this system relies on the accuracy of the clock that’s used to tell the sampling system when to do the measurements. In a perfect world, a system with a sampling rate of 44.1 kHz would make a measurement of the incoming analogue wave exactly every 1/44100th of a second. The time between samples would never vary.
This, of course, is impossible. The clock that ticks at the sampling rate will have some error in time – albeit a very, very small error.
Let’s heavily exaggerate this error so that we can see the resulting effect. Figure 3 shows the same original analogue sinusoidal waveform, sampled (measured) at incorrect times. In other words, sometimes the measurement (represented by the red circles) is made slightly too early (to the left of the gray vertical line – as is the case for Sample #9), sometimes, it’s made too late (to the right of the line – as in Sample #2).
Fig 3. The same analogue sinusoidal waveform, sampled at the wrong times. This error in timing is different each time.
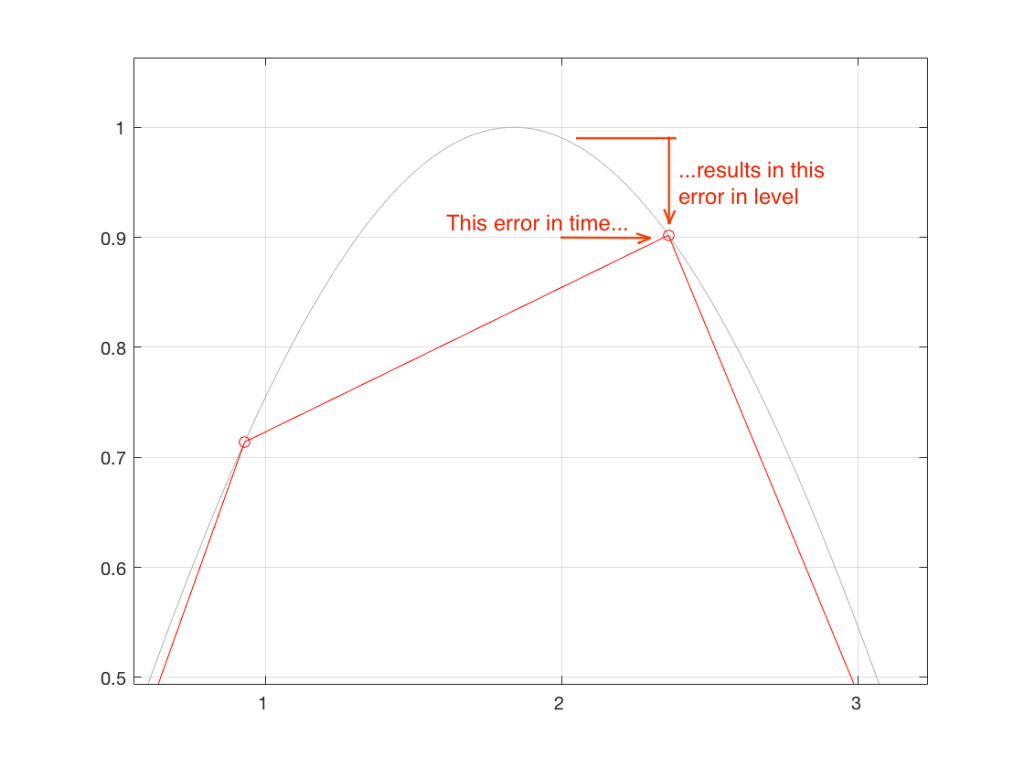
For example, look at the sample that should occur at clock tick #2. I’ve zoomed in to the plot so that this can be seen more clearly in Figure 4.
Fig 4. A portion of the plot in Figure 3, zoomed in for clarity’s sake.
Notice that, because the measurement was made at the wrong time (in the case of sample #2, somewhat late), the result is an error in the measurement of the waveform’s amplitude. So, an error in time produces an error in level.
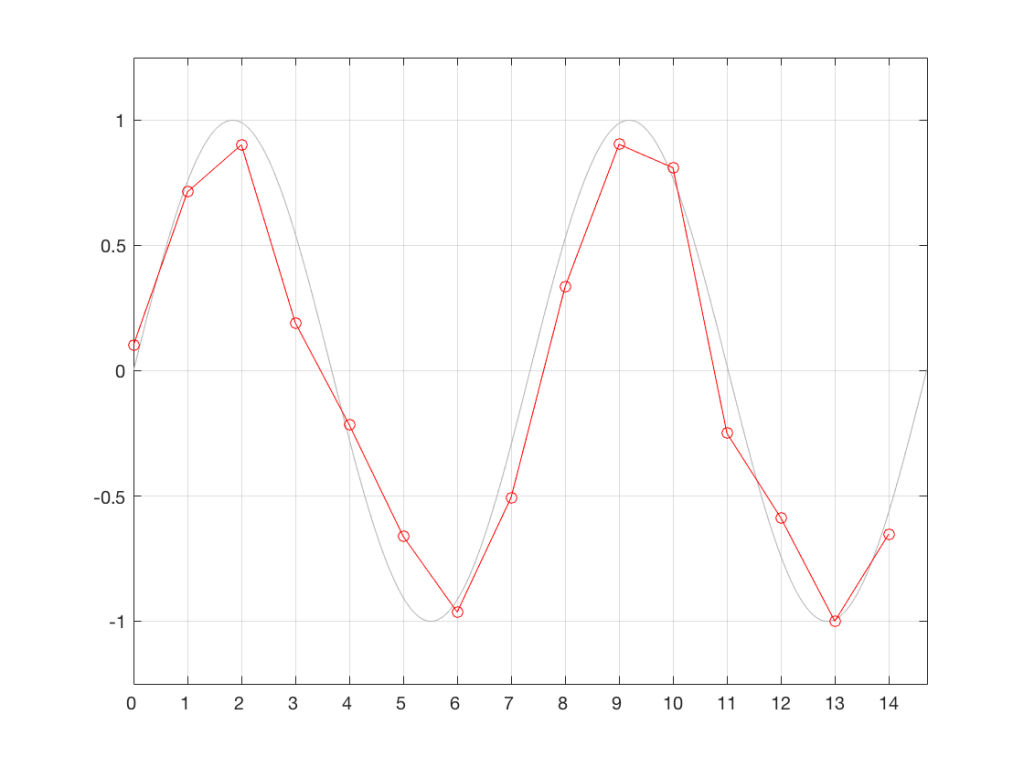
Let’s assume that the measurements we made in Figure 3 are stored and then replayed at exactly the correct times – what will the result be? This is shown in Figure 5. As you can see there, by comparing the measurements we made in Figure 3 to the original waveform, we have resulted in a distortion of the waveform.
Fig 5. The samples, measured at the incorrect times (as shown in Figure 4) re-aligned as though they were played back at the correct times.
The time-based errors in the measurements in Figure 3 result (in this example) in a system that contains amplitude-based errors at the output. This results in some kind of distortion of the signal, as can be seen here.
As you can see in Figure 5, the result is a signal that is not a sine wave. Even after this digital signal has been low-pass filtered by the reconstruction filter in the Digital-to-Analogue Converter (the DAC), it will not be a clean sine wave. But let’s think about exactly what can go wrong here, more carefully.
For starters, an error that is ONLY caused by timing errors in the sampling process cannot produce levels that are outside the amplitude range of the original signal. In other words, if our original signal was 1 V Peak and symmetrical, then the sampled waveform will not exceed this. This is because the samples are all real measurements of the signal – merely performed at the incorrect times.
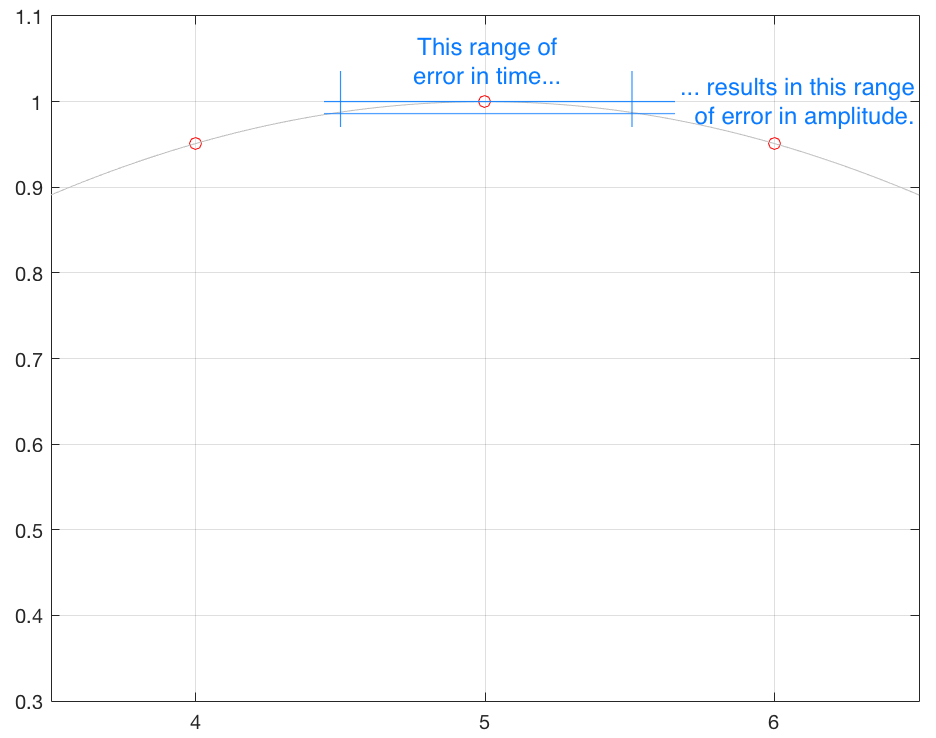
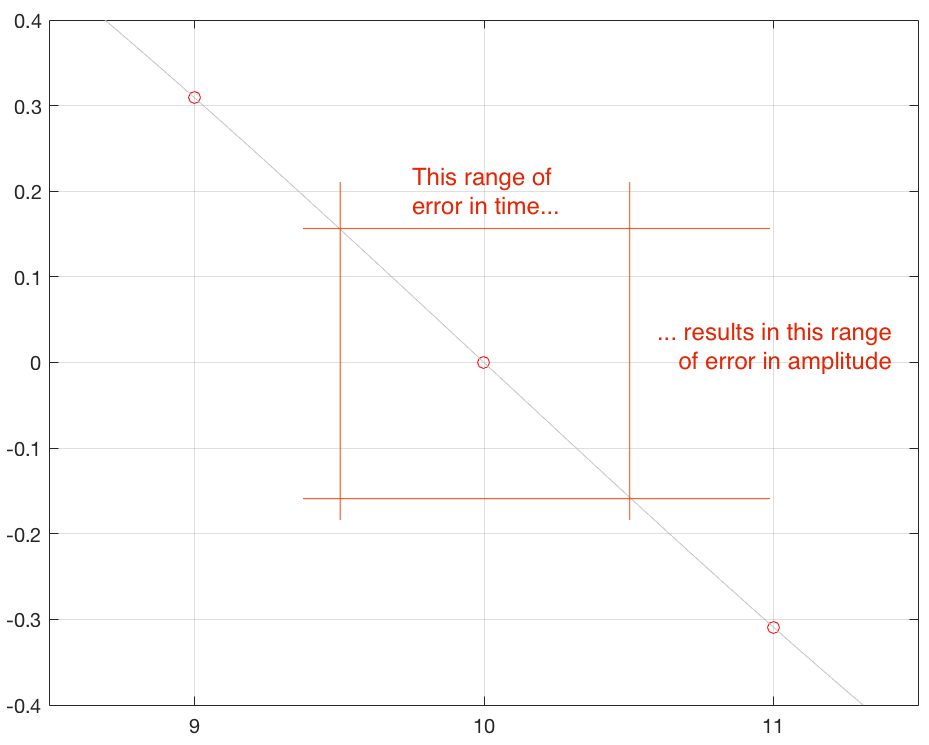
Secondly, if the amount of jitter is kept constant, then the amount of amplitude error will modulate (or vary) with the slope of the signal. This is illustrated in Figure 6, below.
Fig 6a. A sinusoidal waveform that has been sampled.
Fig 6b. The range of the amplitude error if the range of jitter is ±0.5 sample is small when the slope of the signal is low.
Fig 6c. The range of the amplitude error if the range of jitter is ±0.5 sample is much higher when the slope of the signal is high.
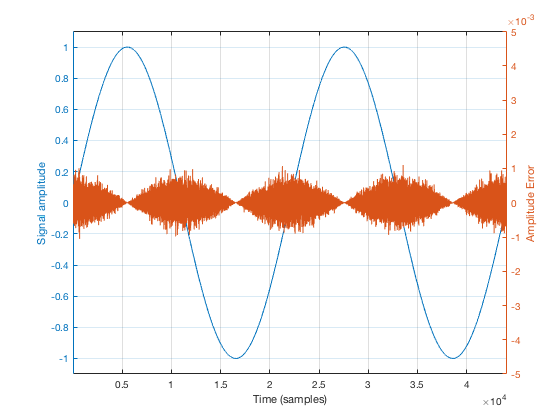
Another way to consider this is that, given a constant amount of jitter, the amplitude error (and therefore the distortion that is generated) modulates with the signal, is proportional to the slope of the signal. Since the maximum slope of the signal increases with amplitude and with frequency, then jitter artefacts will also increase as a result of an increase in the signal level or its frequency.
Fig 6. The blue curve is a sine wave to which I have applied excessive amounts of jitter with a Gaussian distribution. The red curve is the sample-by-sample error (the original signal subtracted from the jittered signal) plotted on a magnified scale. As can be seen, the level of the instantaneous error is proportional to the slope of the signal. So, the end result is that the noise generated by the jitter is modulated by the signal. (If you look carefully at the blue curve, you can see the result of the jitter – it’s vertically narrower when the slope is low – at the tops and bottoms of the curve.)
Thirdly, (and this one may be obvious): in an LPCM system, there are no jitter artefacts if there is no signal. If the input signal is constantly 0, then it doesn’t matter when you measure it… (Note that I said “in an LPCM system” in that sentence – if it’s a Delta-Sigma (1-bit) converter, then this is not true.)
There is more thing to consider – although, given the level of jitter in real-life systems these days, this one is more of a thought experiment than anything else. Take a look back at Figure 3 – specifically, the samples that should have been taken at times 11 and 12. In a 44.1 kHz system, those two samples would have been samples 1/44100th of a second apart. However, as you can see there, the time between those two samples is less than 1/44100th of a second. If the sampling period is reduced, then the sampling rate must be higher than 44.1 kHz. This means that, ignoring everything else, the Nyquist frequency of the system is momentarily raised, allowing content above the intended Nyquist into the captured signal… However, as I said, this is merely an interesting thing to think about. Find something else to feed your free-floating anxiety that keeps you up at night – this issue is not worth a wink’s worth of lost sleep…
One extra thing to note here: If you look at Figure 3, you see a signal that has artefacts caused by jitter. Simply stated, this means that there are errors in the recorded signal. The way I’ve plotted this in Figure 3, those can be considered to be amplitude errors when played through a system without jitter. In other words, if you have a signal with jitter artefacts, you cannot remove them by using a system that has no jitter. the best you can do is to not add more jitter…
Addendum: This description of jitter artefacts as an amplitude distortion is only one way to look at the problem – using what is called the “Time-Domain Model”. Instead, you could use the “Frequency-Domain Model”, which I will not discuss here. If you’d like to dive into this further, Julian Dunn’s paper called “Jitter Theory” – Technical Note TN-23 from Audio Precision is the best place to start. This is a chapter in his book called “Measurement Techniques for Digital Audio”, published by Audio Precision. See this link for more info.
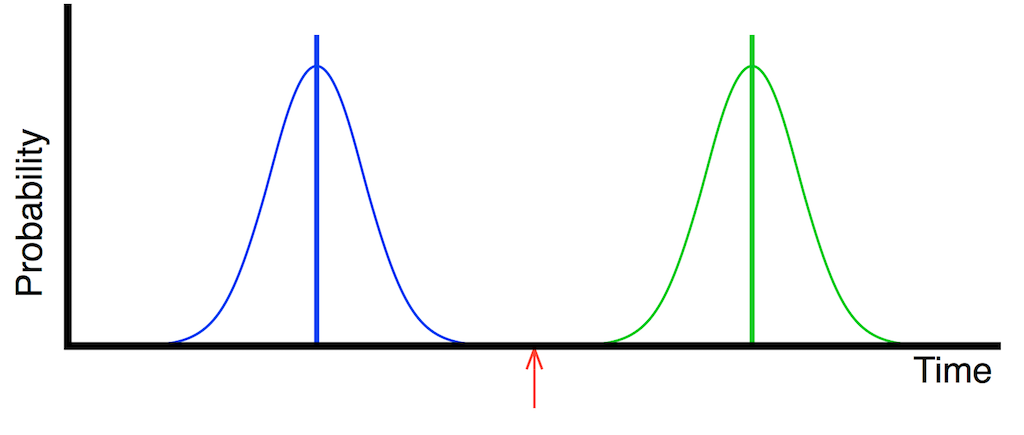
Back in a previous posting, we looked at this plot:
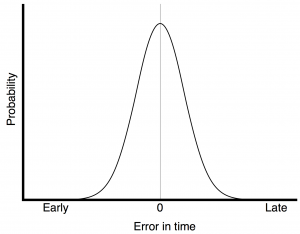
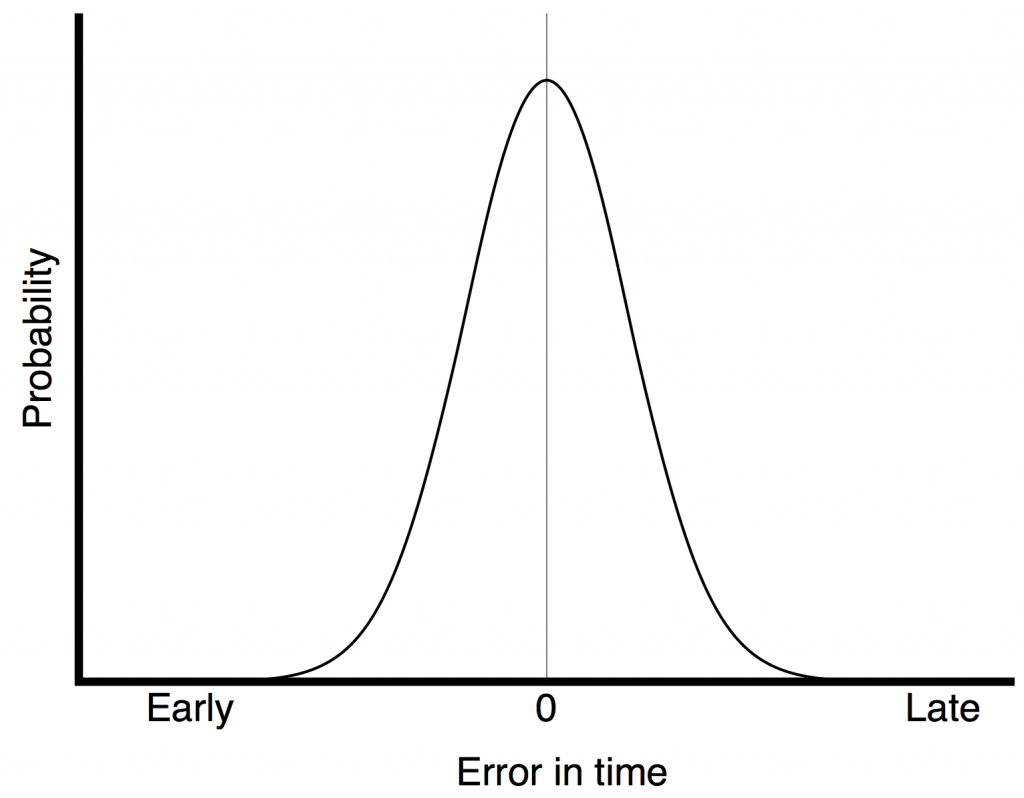
Fig 1. If you have random jitter, then the probability of it having an error in the timing of the clock event has Gaussian distribution. It’s most likely that the event will happen at the correct time – and there is a decreasing probability that the timing error will be increasingly wrong.
The plot in Figure 1 shows the probability of a timing error when you have random jitter. The highest probability is that the clock event will happen at the correct time, with no error. As the error increases (either earlier or later) the probability of that happening decreases – with a Gaussian distribution.
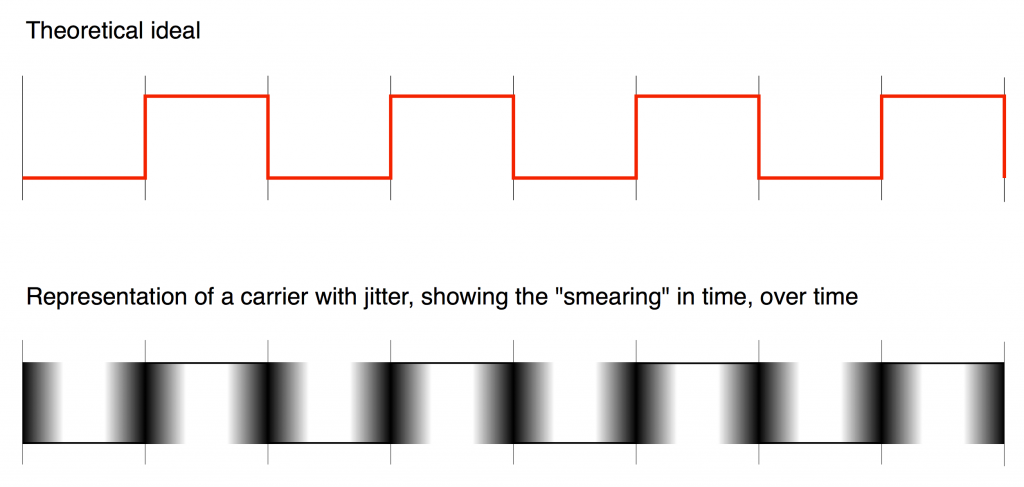
As we already saw, this means that (if the system had an infinite bandwidth, but random jitter) the incoming signal would look something like the bottom plot in Figure 2 when it should look like the top plot in the same Figure.
Fig 2. A simple representation of the time smearing caused by random jitter
However, Figure 1 doesn’t really give us enough information. It tells us something about the timing error of a single event – but we need to know more.
Sidebar: Encoding, Transmitting, and Decoding a bi-phase mark
Let’s say that you wanted to transmit the sequence of bits 01011000 through a system that used the bi-phase mark protocol (like S-PDIF, for example). Let’s walk through this, step by step, using the following 7 diagrams.
Fig 3. The original 8 bits that you want to transmit through the system.
Fig 4. The bits encoded for the bi-phase mark. Remember that a 1 is encoded as a high/low voltage combination or a low/high. A 0 is encoded as a low/low or a high/high. This is sent over the wire by the transmitter and is (in theory) received at the receiver. So, the receiver gets this pulse wave and nothing else…
Fig 5. The receiver picks a threshold (the black horizontal line) somewhere between the high and the low voltages and looks to see when the voltage signal crosses it. Every time it does, the receiver marks a clock event (the ticks along the “Time” axis along the bottom.
Fig 6. Since this has been happening for a while, the receiver is able to interpolate and put some extra clock events in (the green lines) – guessing that these are probably in the correct places.
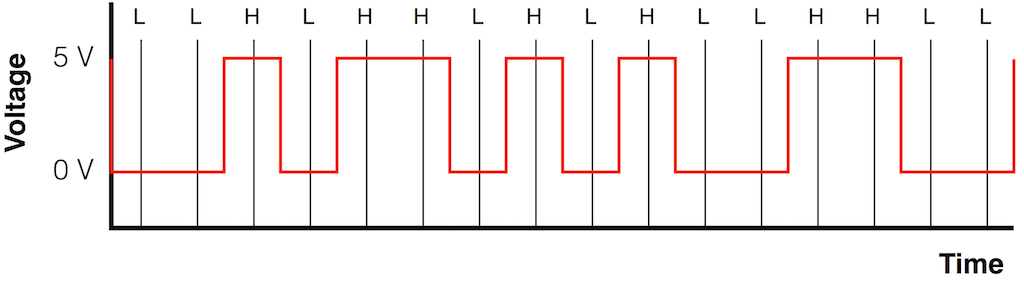
Fig 7. The receiver then makes a clock that “ticks” between the detected clock events. These are represented in this figure as the vertical black lines between the dotted ones. It will use these moments in time to check to see whether the voltage is high or low at that moment.
Fig 8. The receiver detects whether the voltage is high (H) or low (L) at the new clock “ticks” that it has made in Fig 7.
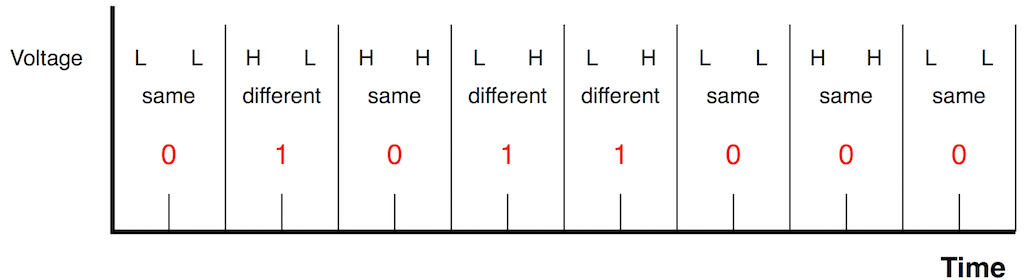
Fig 9. It then pairs the low’s and high’s into groups of 2 (we will not discuss how it knows when to start – that’s another discussion). If it sees the same values in a pair (two “high” or two “low” values) then this is a 0. If it sees two different values in the pair, then it’s a 1.
At this point, the receiver has two pieces of information:
the binary string of values – 01011000
a series of clock “ticks” that matches double the bit rate of the incoming signal
How do we get a data error?
The probability plot in Figure 1 shows the distribution of timing errors for a single clock event. What it does not show is how that relates to the consecutive events. Let’s look at that.
Let’s say that you have two consecutive clock events, represented in Figure 10, below, as the vertical Blue and Green lines. If you have jitter, then there is some probability that those events will be either early or late. If the jitter is random jitter, then the distribution of those probabilities are Gaussian and might look something like the pretty “bell curves” in Figure 10.
Basically, this means that the clock event that should happen at the time of the vertical blue line might happen anywhere in time that is covered by the blue bell curve. This is similarly true for the clock event marked with the green lines.
Fig 10. Two consecutive clock events, showing a probability (with a Gaussian distribution) of the event being either early or late.
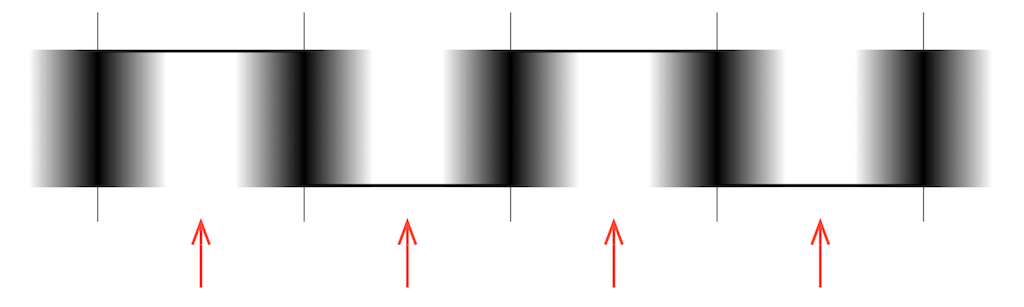
If we were to represent this as the actual pulse wave, it would look something like Figure 11, below.
Fig 11. An artist’s representation of the pulse wave with the transitions smearing in time, as shown in Figure 10.
You will see some red arrows in both Figure 10 and Figure 11. These indicate the time between detected clock events, which the receiver decides is the “safe” time to detect whether the voltage of the carrier signal is “high” or “low”. As you can probably see in both of these plots, the signal at the moments indicated by the red arrows is obviously high or low – you won’t make a mistake if you look at the carrier signal at those times.
However, what if the noise level is higher, and therefore the jitter is worse?
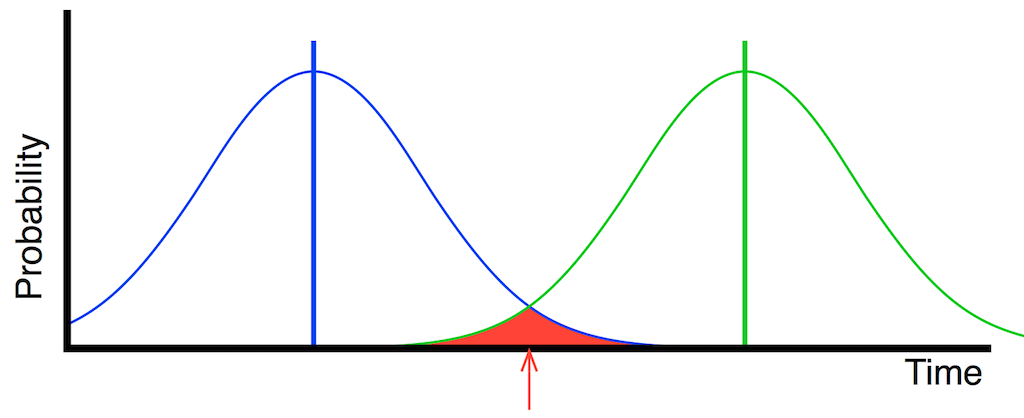
In this case, the actual clock events don’t move in time – but their probability curves widen – meaning that the error can be earlier or later than it was before. This is shown in Figure 12, below.
Fig 12. Two consecutive clock events, showing a probability (with a Gaussian distribution) of the event being either early or late. Note, however, that the error in this case can be larger than that shown in Figure 10.
If you look directly above the red arrow in Figure 12, you will see that both the blue line and the green line are there… This means that there is some probability that the first clock event (the blue one) could come AFTER the second (the green one). That time reversal could happen any time in the range covered by the red area in the plot.
An artist’s representation of this in time is shown in Figure 13, below. Notice that there is no “safe” place to detect whether the carrier signal’s voltage is high or low.
Fig 13. An artist’s representation of the pulse wave with the transitions smearing in time, as shown in Figure 12.
If this happens, then the sequence that should be interpreted as 1-0 becomes 0-1 or vice versa. Remember that this is happening at the carrier signal’s cell rate – not the audio bit rate (which is one-half of the cell rate because there are two cells per bit) – so this will result in an error – but let’s take a look at what kind of error…
The table below shows a sequence of 3 binary values on the left. The next column shows the sequence of High and Low values that would represent that sequence, with two values in red – which we assume are reversed. The third column shows the resulting sequence. The right-most column shows the resulting binary sequence that would be decoded, including the error. If the binary sequence is different from the original, I display the result in red.
You will notice that some errors in the encoded signal do not result in an error in the decoded sequence. (HH and LL are reversed to be HH and LL.)
You will also notice that I’ve marked some results as “Invalid”. This happens in a case where the cells from two adjacent bits are the same. In this case, the decoder will recognise that an error has occurred.
[table]
Original, Encoded, Including error, Decoded
000, HH LL HH, HH LL HH, 000
,HH LL HH, HL HL HH, 110
, HH LL HH, HH LL HH, 000
,HH LL HH, HH LH LH, 011
, HH LL HH, HH LL HH, 000
001, HH LL HL, HH LL HL, 001
, HH LL HL, HL HL HL, 111
, HH LL HL, HH LL HL, 001
, HH LL HL, HH LH LL, 010
, HH LL HL, HH LL LH, Invalid
010, HH LH LL, HH LH LL, 010
, HH LH LL, HL HH LL, 100
, HH LH LL, HH HL LL, Invalid
, HH LH LL, HH LL HH, 000
, HH LH LL, HH LH LL, 010
100, HL HH LL, LH HH LL, Invalid
, HL HH LL, HH LH LL, 010
, HL HH LL, HL HH LL, 100
, HL HH LL, HL HL HL, 111
, HL HH LL, HL HH LL, 100
011, HH LH LH, HH LH LH, 011
, HH LH LH, HL HH LH, 101
, HH LH LH, HH HL LH, Invalid
, HH LH LH, HH LL HH, 000
, HH LH LH, HH LH HL, Invalid
110, HL HL HH, LH HL HH, Invalid
, HL HL HH, HH LL HH, 000
, HLHL HH, HL LH HH, Invalid
, HL HL HH, HL HH LH, 101
, HL HL HH, HL HL HH, 110
111, HL HL HL, LH HL HL, Invalid
, HL HL HL, HH LL HL, 001
, HL HL HL, HL LH HL, Invalid
, HL HL HL, HL HH LL, 100
, HL HL HL, HL HL LH, Invalid
[/table]
How often might we get an error?
As you can see in the table above, for the 5 possible errors in the encoded stream, the binary sequence can have either 2, 3, or 4 errors (or invalid cases), depending on the sequence of the original signal.
If we take a carrier wave that has random jitter, then its distribution is Gaussian. If it’s truly Gaussian, then the worst-case peak-to-peak error that’s possible is infinity. Of course, if you measure the peak-to-peak error of the times of clock events in a carrier wave (a range of time), it will not be infinity – it will be a finite value.
We can also measure the RMS error of the times of clock events in a carrier wave, which will be a smaller range of time than the peak-to-peak value.
We can then calculate the ratio of the peak-to-peak value to the RMS value. (This is similar to calculating the crest factor – but we use the peak-to-peak value instead of the peak value.) This will give you and indication of the width of the “bell curve”. The closer the peak-to-peak value is to the RMS value (the lower the ratio) the wider the curve and the more likely it is that we will get bit errors.
The value of the peak-to-peak error divided by the RMS error can be used to calculate the probability of getting a data error, as follows:
[table]
Peak-to-Peak error / RMS error, Bit Error Rate
12.7, 1 x 10-9
13.4, 1 x 10-10
14.1, 1 x 10-11
14.7, 1 x 10-12
15.3, 1 x 10-13
[/table]
The Bit Error Rate is a prediction of how many errors per bit we’ll get in the carrier signal. (It is important to remember that this table shows a probability – not a guarantee. Also, remember that it shows the probability of Data Errors in the carrier stream – not the audio signal.)
So, for example, if we have an audio signal with a sampling rate of 192 kHz, then we have 192,000 kHz * 32 bits per audio sample * 2 channels * 2 cells per bit = 24,576,000 cells per second in the S-PDIF signal. If we have a BER (Bit Error Rate) of 1 x 10-9 (for example) then we will get (on average) a cell reversal approximately every 41 seconds (because, at a cell rate of 24,576,000 cells per second, it will take about 41 seconds to get to 109 cells). Examples of other results (for 192 kHz and 44.1 kHz) are shown in the tables below.
[table]
Bit Error Rate, Time per error (192 kHz)
1 x 10-9, 41 seconds
1 x 10-10, 6.78 minutes
1 x 10-11, 67.8 minutes
1 x 10-12, 11.3 hours
1 x 10-13, 4.7 days
[/table]
[table]
Bit Error Rate, Time per error (44.1 kHz)
1 x 10-9, 2.95 minutes
1 x 10-10, 29.53 minutes
1 x 10-11, 4.92 hours
1 x 10-12, 2.05 days
1 x 10-13, 20.5 days
[/table]
You may have raised an eyebrow with the equation above – when I assumed that there are 32 bits per sample. I have done this because, even when you have a 16-bit audio signal, that information is packed into a 32-bit long “word” inside an S-PDIF signal. This is leaving out some details, but it’s true enough for the purposes of this discussion.
Finally, it is VERY important to remember that many digital audio transmission systems include error correction. So, just because you get a data error in the carrier stream does not mean that you will get a bit error in the audio signal.
So far, we’ve looked at what jitter is, and two ways of classifying it (The first way was by looking at whether it’s phase or amplitude jitter. The second way was to find out whether it is random or deterministic.) In this posting, we’ll talk about a different way of classifying jitter and wander – by the system that it’s affecting. Knowing this helps us in diagnosing where the jitter occurs in a system, since different systems exhibit different behaviours as a result of jitter.
We can put two major headings on the systems affected by jitter in your system:
data jitter
sampling jitter
If you have data jitter, then the timing errors in the carrier signal caused by the modulator cause the receiver device to make errors when it detects whether the carrier is a “high” or a “low” voltage.
If you have sampling jitter, then you’re measuring or playing the audio signal’s instantaneous level at the wrong time.
These two types of jitter will have different effects if they occur – so let’s look at them in the next two separate postings to keep things neat and tidy.
In the previous posting, we looked at Random Jitter – timing errors that are not predicable (because they’re random). As we saw in the chart in this posting, if you have jitter (you do) and it’s not random, then it’s Deterministic or Correlated. This means that the modulating signal is not random – which means that we can predict how it will behave on a moment-by-moment basis.
Deterministic jitter can be broken down into two classifications:
Jitter that is correlated with the data. This can be the carrier, or possibly even the audio signal itself
Jitter that is correlated with some other signal
In the second case, where the jitter is correlated with another signal, then its characteristics are usuallyperiodic and usually sinusoidal (which could also include more than one sinusoidal frequency – meaning a multi-tone), although this is entirely dependent on the source of the modulating signal.
Data-Dependent Jitter
Data-dependent jitter occurs when the temporal modulation of the carrier wave is somehow correlated to the carrier itself, or the audio signal that it contains. In fact, we’ve already seen an example of this in the first posting in this series – but we’ll go through it again, just in the interest of pedantry.
We can break data-dependent jitter down into three categories, and we’ll look at each of these:
Intersymbol Interference
Duty Cycle Distortion
Echo Jitter
Intersymbol Interference
As we saw in the first posting in this series, a theoretical digital transmission system (say, a wire) has an infinite bandwidth, and therefore, if you put a perfect square wave into it, you’ll get a perfect square wave out of it.
Sadly, the difference between theory and practice is that, in theory, there is no difference between their and practice, whereas in practice, there is. In this case, our wire does not have an infinite bandwidth, and so the square wave is not square when it reaches the receiver.
As we saw in the first posting, an S-PDIF signal uses a bi-phase mark, which is the same as saying it’s a frequency-modulated square wave where a “1” is represented by a square wave with double the frequency of a “0”. So, for example, Figure 1 shows one possible representation of the sequence 01011000. (The other possible representation would be the same as this, but upside down, because the first “0” started as a high voltage value.
Fig 1. A binary sequence represented using a bi-phase mark, as in the case of an S-PDIF transmission.
If that square wave were sent through a wire that rolled off the high frequencies, then the result on the other side might look something like Figure 2.
Fig 2. The original “square wave” on the top, and the output of the same wave, sent through a low-pass filter
If we use a detection algorithm that is looking for the moment in time when the incoming signal crosses what we expect to be the half-way point between the high and low voltages, then we get the following
Fig 3: The time between when the transition actually happened (the grey vertical lines) and the time it is detected to have happened (the right sides of the blue “H’s”) changes from transition to transition.
As you can see in Figure 3, the time the transition is detected is late (which is okay) and it varies with respect of the correct time (which is not okay). That variation is the jitter that is caused by the relationship between the pattern in the bi-phase mark, the fundamental frequency of the “square wave” of the carrier (which is related to the sampling rate and the word length, possibly), and the cutoff frequency of the low-pass filter.
Duty Cycle Distortion
Typically, a digital signal is transmitted using some kind of pulse wave (which is the correct term for what I’ve been calling a “square wave”. It’s a square-ish wave (in that it bangs back and forth between two discrete voltages) but it’s not a square wave because the frequency is not constant. This is true if it’s a non-return-to-zero strategy (where a 1 is represented by a high voltage and a 0 is represented by a low voltage, as shown in Figure 4) or a bi-phase mark (as shown in Figure 1).
Figure 4. A non-return-to-zero method of transmitting a binary digital signal.
In either of these two cases (NRZ or bi-phase mark), the system modulates the amount of time the pulse wave is a high voltage or a low voltage. This modulation is called the duty cycle of the pulse wave. You’ll sometime see a “duty cycle” control on a square wave generator which lets you adjust whether the pulse wave is a square wave (a 50% duty cycle – meaning that it’s high 50% of the time and low 50% of the time) or something else (for example, a 10% duty cycle means that it’s high 10% of the time, and low 90% of the time)
If your transmission system is a little inaccurate, then it could have an error in controlling the duty cycle of the pulse wave. Basically, this means that it makes the transitions at the wrong times for some reason, thus creating a jittered signal before it’s even transmitted.
Echo Jitter
We’re all familiar with an echo. You stand far enough away from a wall, you clap your hands, and you can hear the reflection of the sound you made, bouncing back from the wall. If the wall is far enough away, then the echo is a second, separate sound from the original. If the wall is close, you still get an echo (in fact, it’s even louder) but it’s coming at you so soon after the original, direct sound, that you can’t perceive it as a separate thing.
What many people don’t know is that, if you stand in a long corridor or a tunnel with an open end, you will also hear an echo, bouncing off the open end of the tunnel. It’s not intuitive that this is true, since it looks like there’s nothing there to bounce off of, but it happens. A sound wave is reflected off of any change in the acoustic properties of the medium it’s travelling through. So, if you’re in a tunnel, it’s “hard” for the sound wave to move (because there aren’t many places to go) and when it gets to the end and meets a big, open space, it “sees” this as a change and bounces back into the tunnel.
Basically, the same thing happens to an electrical signal. It gets sent out of a device, runs down a wire (at nearly the speed of light) and “hits” the input of the receiver. If that input has a different electrical impedance than the output of the transmitter and the wire (on other words, if it’s suddenly harder or easier to push current through it – sort of….) then the electrical signal will (partly) be reflected and will “bounce” back down the wire towards the transmitter.
This will happen again when the signal bounces off the other end of the wire (connected to the transmitter) and that signal will head back down the wire, back towards the receiver again.
How much this happens is dependent on the impedance characteristics of the transmitter’s output, the receiver’s input, and the wire itself. We will not get into this. We will merely say that “it can happen”.
IF it happens, then the signal that is arriving at the receiver is added to the signal that has already reflected off the receiver and the transmitter. (Of course, that combined signal will then be reflected back towards the transmitter, but let’s pretend that doesn’t happen.)
The sum of those two signals is the signal that the receiver tries to decode into a carrier signal. However, the reflected “echo” is a kind of noise that infects the correct signal. This, in turn, can cause timing errors in the detection system of the receiver’s input.
Periodic Jitter
Let’s take a CD player’s S-PDIF output and connect it to the S-PDIF input of a DAC. We’ll use an old RCA cable that we had lying around that has been used in the past – not only as an audio interconnection, but also to tie a tomato plant to a trellis. It’s also been run over a couple of times, under the wheels of an office chair. So, what was once a shield made of nice, tightly braided strands of copper is now full of gaps for electromagnetic waves to bleed in.
We press play on the CD, and the audio signal, riding on the S-PDIF carrier wave is sent through our cable to the DAC. However, the signal that reaches the DAC is not only the S-PDIF carrier wave, it also contains a sine wave that is radiating from a nearby electrical cable that is powering the fridge…
Fig 5. An example of a bi-phase mark, transmitted through a system with a low-pass filter and a sinusoidal jitter from an external source.
Take a look at Figure 5. The top plot, in red, is the “perfect” carrier wave, sent out by the transmitter.
If that wave is sent through a system that rolls off the high end, the result will look like the red curve in the middle plot. This will be trigger clock events in the receiver, shown as the black curve in the middle plot. There, you may be able to see the intersymbol interference jitter (although it’s small, and difficult to see in that plot).
The blue curve in the bottom plot shows the sinusoidal modulator coming into the system from an external source. That’s added to our low-pass filtered signal, resulting in the red curve in the bottom plot (see how it appears to “ride” the blue curve up and down). The black curve is the end result, triggered by the instances when the red line crosses the mid-point (in this plot, 0 V). You should be able to see there that when the sinusoid is positive, the trigger event is late (relative to what it would have been – the black curve in the middle plot). When the sinusoid is negative, the trigger event is early.
Putting some of it together…
If we take a system that is suffering from
Intersymbol Interference (Deterministic)
Periodic Jitter (Deterministic)
Random Jitter
Then the result looks something like Figure 6.
Fig 6.
The top plot shows the original bi-phase mark that we intend to transmit.
The second plot shows the low-pass filtered carrier wave (in red) and the triggered events that result (in black).
The third plot shows the periodic, sinusoidal source (in blue), the resulting carrier wave (in red) and the triggered events that result (in black).
The bottom plot adds random noise to the sinusoid (in blue), therefore adding noise to the carrier wave (in red) and resulting in indecision on the transition time. This is because, when the noisy carrier wave crosses the threshold, it goes back and forth across it multiple times per “transition”. So, the black wave is actually banging back and forth between the “high” and “low” values a bunch of times, each time the carrier crosses the threshold. If you are going to build a digital audio receiver that is reasonably robust, you will need to figure out how to deal with this smarter than the way I’ve shown it here.
Addendum: S-PDIF data vs cable lengths
One of the factors to worry about when you’re thinking about Echo Jitter is the “wavelength” of one “cell”. A cell is the shortest duration of a pulse in the wave (which is half of the duration of a bit – the “high” or the “low” value when transmitting a value of 1 in the bi-phase mark).
This is similar to a real echo in real life. If you clap your hands and hear a distinct echo, then the reflecting surface is very far away. If the echo is not a separate sound – if it appears to occur simultaneously with the direct sound, then the wall is close.
Similarly, if your electrical cable is long enough, then a previous value (a high or a low voltage) may be opposite to the current value sometimes – which may have an effect on the signal at the input of the receiver.
This raises the question: how long is “long”? This can be calculated by finding the wavelength of one cell in the electrical cable when it’s being transmitted.
The speed of an electrical signal in a good conductor is approximately 299,792,458 m/s.
The number of cells per second in an S-PDIF transmission can be calculated as follows:
sampling rate * number of audio channels * 32 bits/frame * 2 cells/bit
This means that the number of cells per second are as follows:
Fs
Cells per Second
44.1 kHz
5,644,800
48 kHz
6,144,000
88.2 kHz
11,289,600
96 kHz
12,288,000
176.4 kHz
22,579,200
192 kHz
24,576,000
If we divide the speed of a wave on a wire by the number of cells per second, then we get the length of one cell on the wire, which turns out to be the following:
Fs
Cell length
44.1 kHz
53.1 m
48 kHz
48.8 m
88.2 kHz
26.6 m
96 kHz
24.4 m
176.4 kHz
13.3 m
192 kHz
12.2 m
So, even if you’re running S-PDIF at 192 kHz AND if you are getting an echo on the wire (which means that someone hasn’t done a very good job at implementing the correct impedances of the S-PDIF output and input): if your interconnect cable is 30 cm long then you don’t need to worry about this very much (because 30 cm is quite small relative to the 12.2 m cell length on the wire…)
Dig out your old cassette copy of “Love Will Keep us Together”, performed by Captain and Tenille (although the original version was released by Neil Sedaka (one of the songwriters) in France) and press PLAY on your oldest cassette deck. You’ll hear the song (now it’s stuck in your head, isn’t it?) as well the hiss from the cassette. That hiss comes (mostly) from the random-ness of the magnetic tape itself, and is just a signal that is added to Captain and Tenille.
Random jitter is similar to the tape hiss. You have a signal (the audio signal that has been encoded as a digital stream of 1’s and 0’s, sent through a device or over a wire as a sequence of alternating voltages) and some random noise is added to it for some reason… (Maybe it’s thermal noise in the resistors, or cosmic radiation left over from the Big Bang bleeding through the shielding of your S-PDIF cable, or something else… )
That random noise results in the device (the audio gear or the chip inside it) wrongly interpreting what time it is, which may or may not affect your audio signal (we’ll talk about that later in the series).
The difference between the cassette example and jitter is that the noise that is modulating the “signal” is not really added to it (at least, it’s not added to the audio signal…). What we’re really talking about is that the jitter is modulating the signal that carries your audio signal – not the audio signal itself. This is an important distinction, so if that last sentence is a little fuzzy, read it again until it makes sense.
Good, I assume that if you’re gotten to this sentence, then you know the difference between the audio signal (the sound of Captain and Tenille singing “Love Will Keep us Together”) and the Carrier signal that is delivering the data that contains that audio signal.
This means that we can talk about the Carrier (for example, the S-PDIF stream of bits that carries the digitally-encoded audio signal) and the Modulator (the signal that changes the timing of that carrier coming in, and thus resulting in jitter).
If you need an analogy at this point: Your house (the carrier) is not your stuff (the signal). Your house contains your stuff. If something happens to the house, that same thing may or may not happen to the stuff inside it. If you’re in an earthquake (the modulator), the house and its contents will experience roughly the same thing. If it’s raining and windy (two different modulators), the house and its contents will not.
Armed with this distinction, we can say that random jitter can be separated into two distinct classifications:
Timing errors of the clock events relative to their ideal positions
Timing errors of the clock periods relative to their ideal lengths in time
These are very different – although they look very similar.
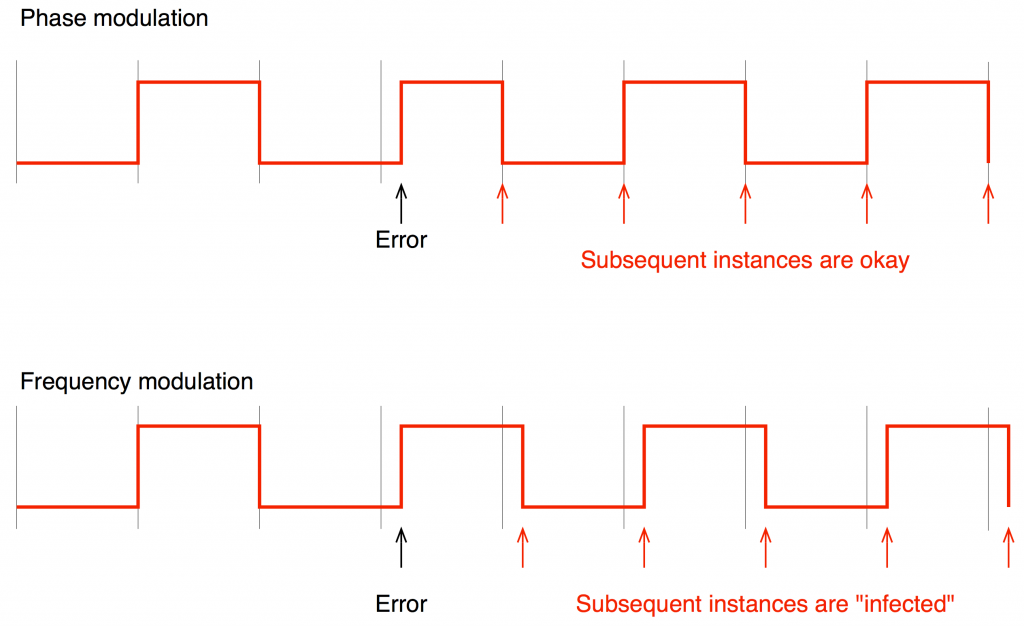
The first is an absolute measure of the error in the clock event – when did that single event happen relative to when it should have happened? Each event can be measured individually relative to perfection – whatever that is. This is called a Phase Modulation of the carrier. It has a Gaussian characteristic (which I’ll explain below…) and has no “memory” (which is explained first).
The second of these isn’t a measure of the events relative to perfection – it’s a measure of the amount of time that happened between consecutive events. This is called a Frequency Modulation of the carrier. It also has a Gaussian characteristic (which I’ll explain below…) but it does have a “memory” (which is explained using Figure 1).
Fig 1. The top plot shows a simplified example of phase modulation of the carrier. Note that there is an error in the time of one of the events, but all subsequent events are correct. The bottom plot shows a simplified example of frequency modulation of the carrier. In this case, the width of the pulses is modulated – so an error has a “downstream” effect. All events after the error are affected by it – so the system is said to have a “memory”.
Gaussian Distribution
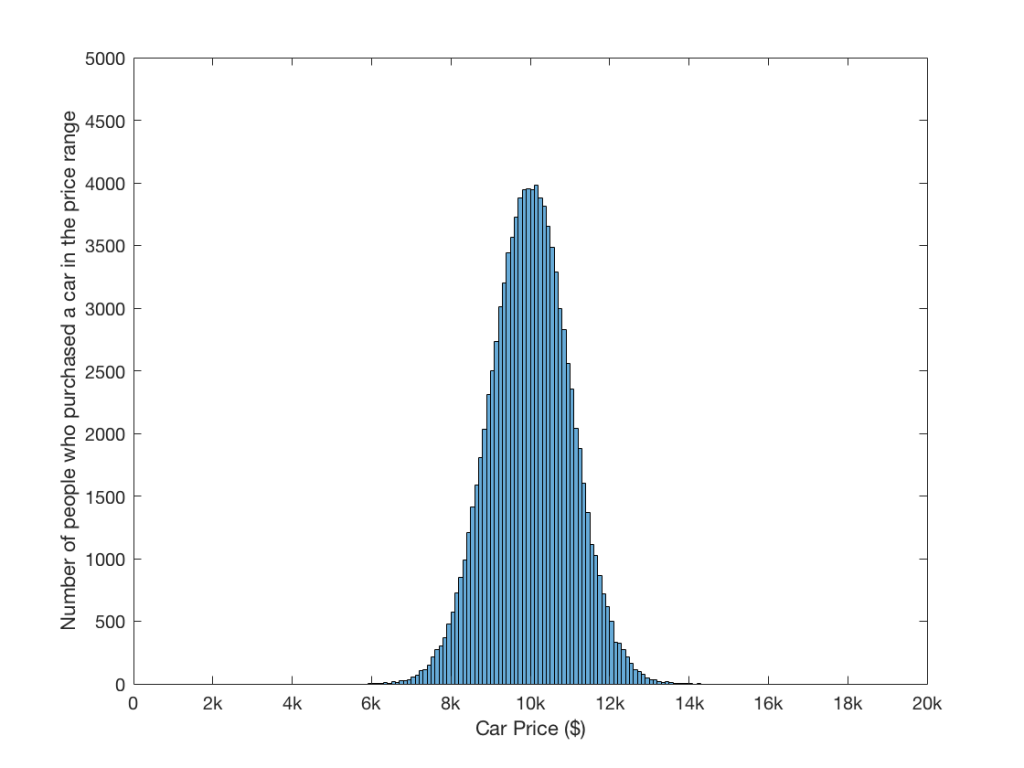
If you stood on a street in New York City and asked the first 100,000 people you saw how much they spent on buying their last car, you would get a very wide range of answers. A very few people who say that they spent a LOT of money. A very few people would say that they spent nothing because they don’t own a car. Most people would give you around the same number, give or take. If we took all of those answers, grouped them into ranges of $100, and plotted the results (therefore showing how many people bought a car that cost $0 – $100, $101 – $200, $201 – $300, and so on… you’d get something like the graph shown in Figure 2.
Fig 2: The results of an imaginary survey of 100,000 New Yorkers when asked how much they spent on their last car purchase.
As you can see in the plot in Figure 2, most people spent about $10,000 on their last car. Some some spent more, some spent less… But the further you get from $10,000, the fewer people are “in the club”.
Of course, I made up those numbers – but the important thing is not the actual data – it’s the shape it makes. That “bell curve” is called a “normal distribution” or a “Gaussian distribution” of numbers. If you graph things that occur in nature – everyone’s age in the whole world, the brightness of stars, math grades in Canadian grade 6 students’ final exams, heights of all plants – you’ll see this shape often.
Okay, I lied a little… If you take the ages of everyone in the world, or the heights of all plants, you won’t really get a true Gaussian distribution. This is because, if the values (the ages or the heights) really had a Gaussian distribution, then it would be possible for them to be infinite. Admittedly, the probability of the value being infinite is infinitely small – but that’s a small detail… In addition, the distribution would have to be symmetrical, and since it should be possible to have a value ∞, that would mean that it should also be possible to have a value of -∞ as well…
Let’s get back to Random Jitter… If the jitter is truly random, and we measure the errors in the time events, we will see a Gaussian distribution, centred at 0 seconds. In other words, the error has the highest probability of being 0 (and therefore no error) and the bigger the error (either too early or too late) the smaller the probability of that happening. Weirdly, since the distribution is Gaussian (or at least, we assume that it is) then the worst-case error is -∞ or ∞ – in other words, the event might never happen for some reason – no matter how long you wait…
Fig 3. The probability of an error in the detected timing of an event in the carrier signal, showing a Gaussian distribution. As you can see there, the event is most likely to happen “on time”, but there is a small probability that it will either be very, very early, or very, very late…
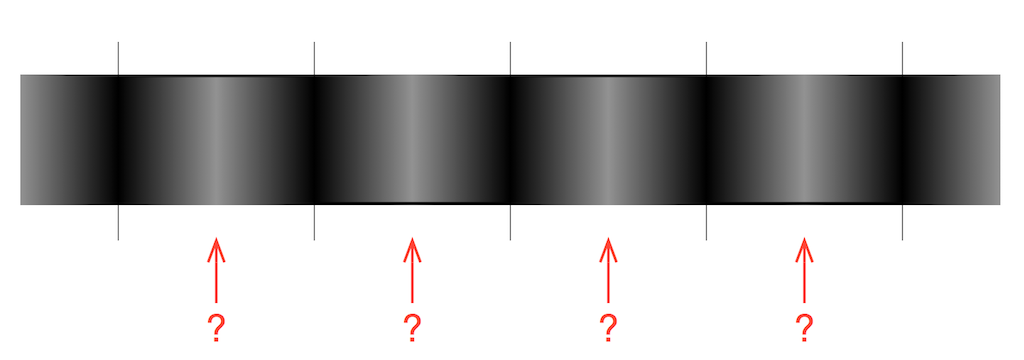
This means that, if you plot a jittered carrier wave on a display, and take a long-exposure photograph of it, you’ll see how the timing events move in time as a “blur” in the photo. A simple artist’s conception (yes, I phrased that correctly…) of this is shown in Figure 4.
Fig 4. The bottom graphic shows a simple representation of the time smearing of a carrier wave if you were to do a long-exposure photograph of it. Notice that the timing events are usually in the right place – but they might be early or late. Any one of these blurred vertical lines shows the same thing as the probability plot in Figure 3.
Addendum: A little bit of math…
This is just a little extra information for geeks and aspiring geeks. If this gives you a headache, ignore it. It will not help you.
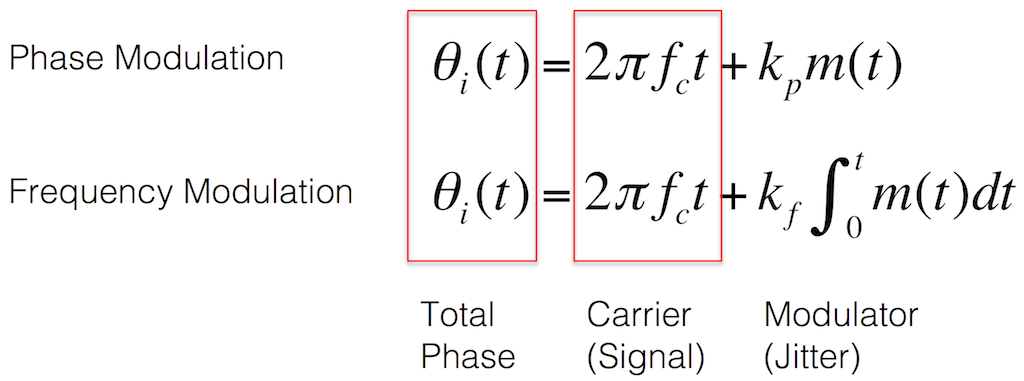
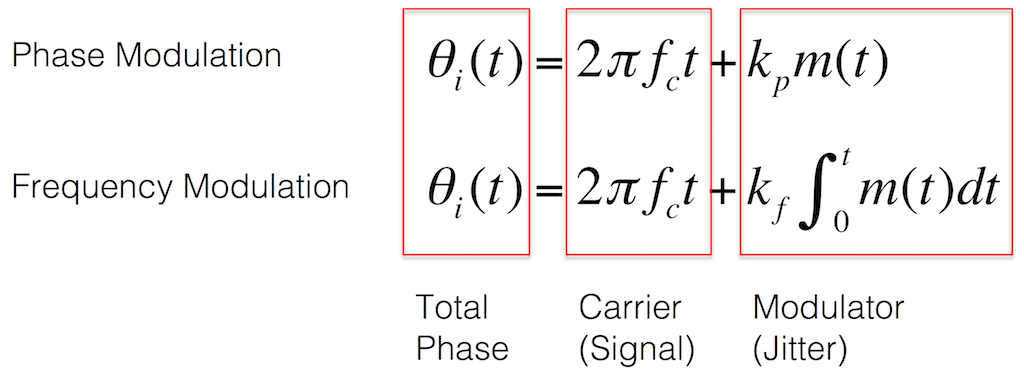
Equation 1: The math that expresses a phase-modulated signal vs a frequency-modulated one
Equation 2: The signal that we’re worried about can be expressed as a total phase resulting from the sum of two phases – that of the original signal and the jitter.
Equation 3: The “carrier” is the signal itself. It’s the same, regardless of how it’s being modulated.
Equation 4: The jitter is the “modulator” since it is varying (or modulating) the signal in time. Note that the difference between phase- and frequency-modulation appears here in the math. If the jitter is caused by a frequency modulation of the signal, then there is an integral involved – which is the mathematical reason for the “memory” in the system.
This posting is a simple one… It’s a setup for the next bunch of postings in this series.
In the last posting, we saw that jitter can be separated into two categories, looking at whether the root of the problem is in the time or the amplitude domain.
A different way to categorise jitter is to start by looking at whether the variation in the timing error is random or deterministic.
If the timing error is random, then there is no way of predicting what the error on the next clock “tick” will be. In this case, the error is caused by some kind of random noise (I know – that’s redundant) somewhere in the system.
However, if it’s deterministic, then the timing error will be correlated with some measurable, interfering signal that is not just random.
An Analogy for Obfuscation
One way to think of this is to imagine the sound coming from a poorly-made piece of audio gear.
You’ll hear the signal
you’ll hear some distortion artefacts that are somehow related to the signal
you’ll hear some “hiss”
and you’ll also hear some “hummmm”.
The signal is what you want to hear.
The other three are things-you-don’t-want-to-hear: stuff that would traditionally be included as TDH+N or “total harmonic distortion plus noise”.
The distortion artefacts are things that are unwanted, but somehow related to the signal – so they are not periodic, but they’re deterministic.
The “hiss” is independent noise – a random signal that is added to (but also unrelated to) your signal.
The hum is not random – it’s periodic (meaning that it repeats itself) – and therefore it’s also deterministic.
If you have a digital audio system, it will have jitter (remember – this might not be anything to worry about… sometimes it just doesn’t matter…). The total jitter that it has is the sum result of all of the different types of jitter that contribute to the total. So, in the chart in Figure 1, you can sort of think of each of the black lines as representing “plus signs”. (Only “sort of”, since it depends on exactly what you’re measuring, and for how long…)
My plan is that I’ll address each of these blocks individually in the coming postings in the series.
In the previous posting, I talked a little about what jitter and wander are, and one of the many things that can cause it. The short summary of that posting is:
Jitter and wander are the terms given to a varying error in the clock that determines when an audio sample should (or did) occur.
Note the emphasis on the word “varying”. If the clock is consistently late by a fixed amount of time, then you don’t have jitter or wander. The clock has to be speeding up and slowing down.
One of the ways you can categorise jitter is by separating the problem into two dimensions – phase (or time) and amplitude.
Let’s say that
you have a “square wave” that carries your encoded digital audio signal coming into your device, AND
you are creating a clock “tick” based on the time of the transition between the high and low voltages AND
you are detecting this transition by looking at what time the voltage value crossed the threshold, which is half-way between your high and low voltages
IF there is a variation ONLY in the time that the voltage crossed the threshold – not in the high and low voltage values themselves, then you have what is called phase jitter. This is probably easier to understand if you look at Figure 1, below.
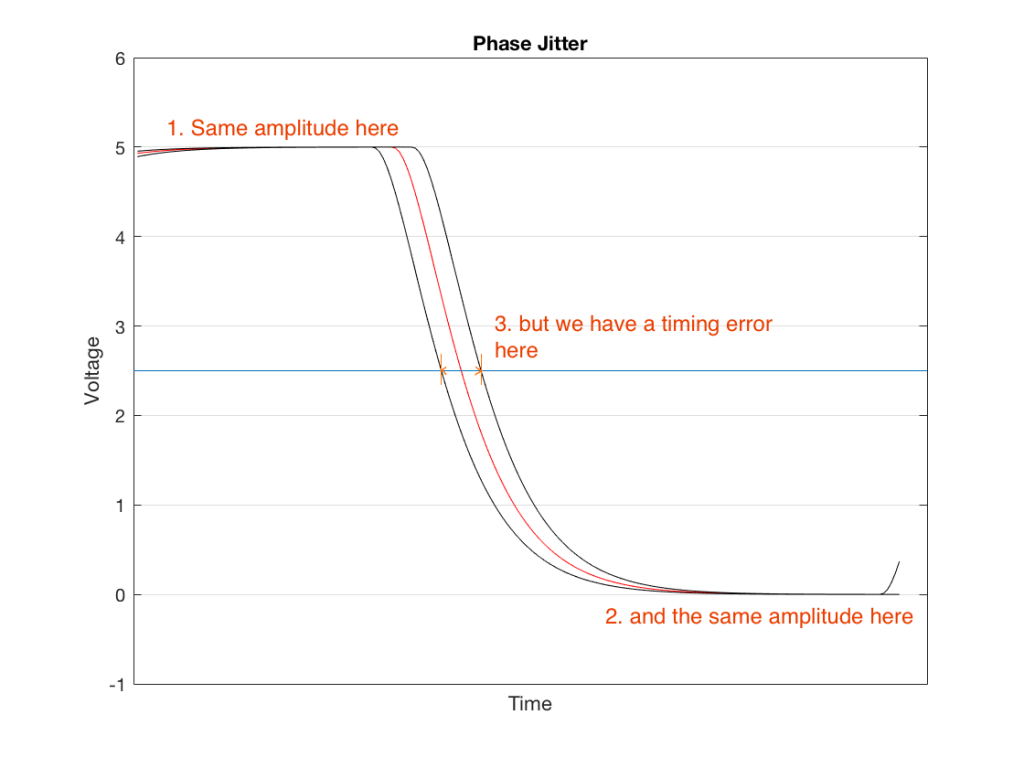
Fig 1. Phase jitter is a “sliding” of the signal in time. The red curve shows when the signal should have crossed the threshold. The black lines show two different errors – one early and one late.
There are three curves in Figure 1. The red curve is the “good” one – it shows the voltage changing from high to low (in this case, 5 V and 0 V), at exactly the right time.
The black curve to the left of this shows an example of a transition that happens too early for some unknown reason. Although that black line also changes from 5 V to 0 V, it does it too early, giving us a timing error when we look at the moment it crosses the threshold (the line at 2.5 V).
The black curve to the right shows an example of a transition that happens too late for some unknown reason. Although that black line also changes from 5 V to 0 V, it does it too late, giving us a timing error when we look at the moment it crosses the threshold (the line at 2.5 V).
As I said above, jitter and wander are the result of a variation in the time that we cross that threshold. So, we will talk about peak-to-peak jitter measurements – a measurement of the amount of time between the earliest detected transition to the latest one. This allows us to not worry so much about measuring a single transition’s error relative to when it should have happened (which would be difficult to do). It’s much easier to just look at the incoming signal over time, and measure the difference in time between the earliest and the latest – the total “width” of the error in time.
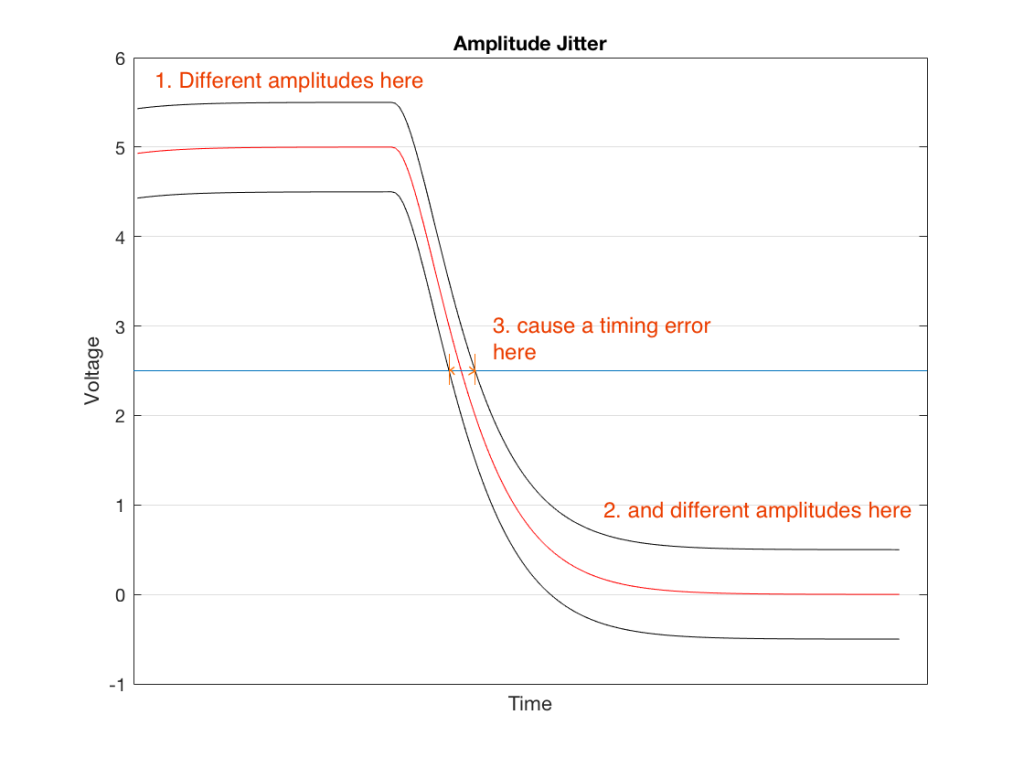
The second classification of jitter is sort of a “side effect” of a different problem. If we take the square wave and we change its amplitude – so we have an error in its voltage level – then a by-product of this is a change in the time the transition crosses the threshold. This is called amplitude jitter and is shown in Figure 2.
Fig 2. Amplitude jitter is an error in the timing caused by an error in the amplitude. The red curve shows when the signal should have crossed the threshold. The black lines show two different errors – one early (because the amplitude was too low) and one late (because the amplitude was too high).
Notice here that the reason the error occurs in time is that we have an error in level. The value of the threshold (the horizontal line at 2.5 V) is based on the assumption that our high and low voltages are 5 V and 0 V. If we have an amplitude error (say, in the case of the upper curve in this plot, 5.5 V and 0.5 V) then the threshold (still at 2.5 V) is too low – so the time the voltage crosses that line will be late.
So, if you have a modulation (a change) in the amplitude (the voltage level) of the signal, then you will also get a modulation in the timing information, resulting in jitter and wander.
Again, this error in time is probably most easily measured as a peak-to-peak jitter value.
Wrapping up
If you’re a system developer or if you’re trying to improve your system, you need to know whether you have phase jitter or amplitude jitter in order to start tracking down the root cause of it so that you can fix it. (If your car doesn’t start and you want to fix it, it’s good to find out whether you are out of fuel or if you have a dead battery… These are two different problems…)
However, if you’re just interested in evaluating the performance of a system, one thing you can do is simply to ask “how much jitter do I have?” (If your car doesn’t start, you’re not going to get to work on time… Whether it’s your battery or your fuel is irrelevant.) You measure this, and then you can make a decision about whether you need to worry about it – whether it will have an effect on your audio quality (which is a question that not determined so much by the amount of jitter that you have, but where it is in your system, and how the “downstream” devices can deal with it).
When many people (including me…) explain how digital audio “works”, they often use the analogy of film. Film doesn’t capture any movement – it’s a series of still photographs that are taken at a given rate (24 frames (or photos) per second, for example). If if the frame rate is fast enough, then you think that things are moving on the screen. However, if you were a fly (whose brain runs faster than yours – which is why you rarely catch one…), you would not see movement, you’d see a slow slide show.
In order for the film to look natural (at least for slowly-moving objects), then you have to play it back at the same frame rate that was used to do the recording in the first place. So, if your movie camera ran at 24 fps (frames per second) then your projector should also run at 24 fps…
Digital audio isn’t exactly the same as film… Yes, when you make a digital recording, you grab “snapshots” (called samples) of the signal level at a regular rate (called the sampling rate). However, there is at least one significant difference with film. In film, if something happened between frames (say, a lightning flash) then there will be no photo of it – and therefore, as far as the movie is concerned, it never happened. In digital audio, the signal is low pass filtered before it’s sampled, so a signal that happens between samples is “smeared” in time and so its effect appears in a number of samples around the event. (That effect will not be part of this discussion…)
Back to the film – the theory is that your projector runs at the same frame rate as your movie camera – if not, people appear to be moving in slow motion or bouncing around too quickly. However, what happens when the frame rate varies a just little? For example, what if, on average, the camera ran at exactly 24 fps, but the projector is somewhat imprecise – so if the amount of time between successive frames varied from 1/25th to 1/23rd of a second randomly… Chances are that you will not notice this unless the variation is extreme.
However, if the camera was the one with the slightly-varying frame rate, then you would not (for example) be able to use the film to accurately measure the speeds of passing cars because the time between photos would not be 1/24th of a second – it would be approximately 1/24th of a second with some error… The larger the error in the time between photos, the bigger the error in our measurement of how far the car travelled in 1/24th of a second.
If you have a turntable, you know that it is supposed to rotate at exactly 33 and 1/3 revolutions per second. However, it doesn’t. It slowly speeds up and slows down a little, resulting in a measurable effect called “wow”. It also varies in speed quickly, resulting in a similar measurable effect called “flutter”. This is the same as our slightly varying frame rate in the film projector or camera – it’s a varying distortion in time, either on the playback or the recording itself.
Digital audio has exactly the same problem. In theory, the sampling rate is constant, meaning that the time between successive samples is always the same. A compact disc is played with a sampling rate of 44100 Samples per Second (or 44.1 kHz), so, in theory, each sample comes 1/44100th of a second after the previous one. However, in practice, this amount of time varies slightly over time. If it changes slowly, then we call the error “wander” and if it changes quickly, we call it “jitter”.
“Wander” is digital audio’s version of “wow” and “jitter” is digital “flutter”.
Transmitting digital audio
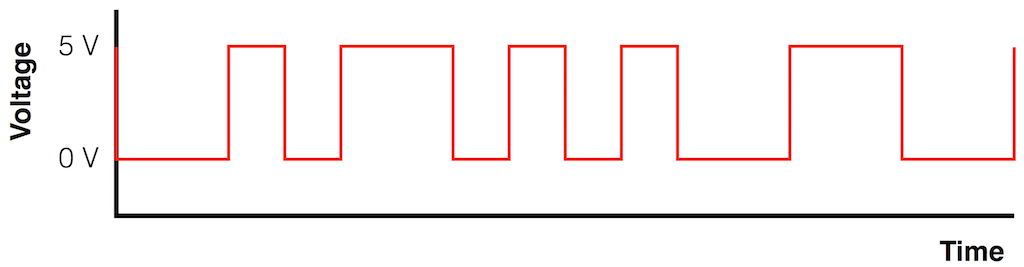
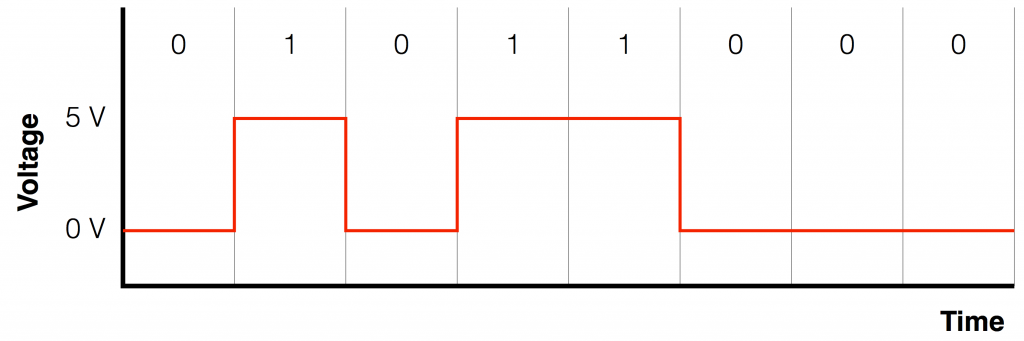
Without getting into any details at all, we can say that “digital audio” means that you have a representation of the audio signal using a stream of “1’s” and “0’s”. Let’s say that you wanted to transmit those 1’s and 0’s from one device to another device using an electrical connection. One way to do this is to use a system called “non-return-to-zero”. You pick two voltages, one high and one low (typically 0 V), and you make the voltage high if the value is a 1 and low if it’s a 0. An example of this is shown in the Figure below.
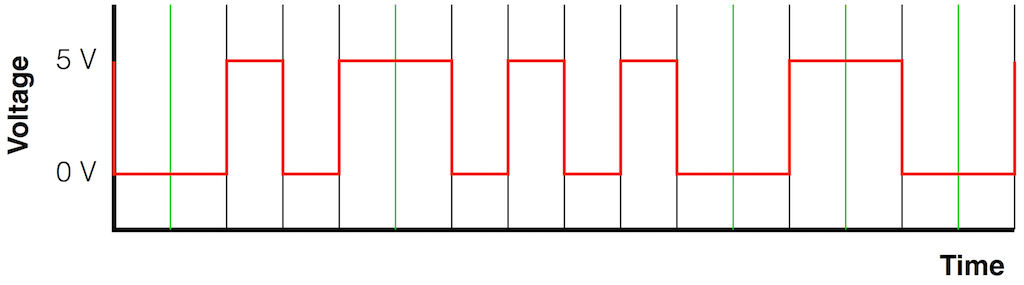
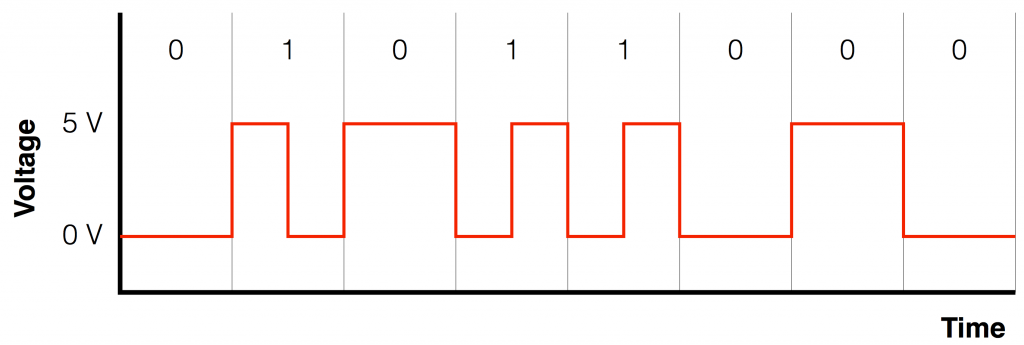
Fig 1: A binary stream (01011000) transmitted as two voltages using a “non-return-to-zero” protocol. For this example, I used 0 V and 5 V for the “low” and “high” values – the actual voltages are irrelevant.
This protocol is easy to understand and easy to implement, but it has a drawback – the receiving device needs to know when to measure the incoming electrical signal, otherwise it might measure the wrong value. If the incoming signal was just alternating between 0 and 1 all the time (01010101010101010) then the receiver could figure out the timing – the “clock” from the signal itself by looking at the transitions between the low and high voltages. However, if you get a long string of 1’s or 0’s in a row, then the voltage stays high or low, and there are no transitions to give you a hint as to when the values are coming in…
So, we need to make a simple system that not only contains the information, but can be used to deliver the timing information. So, we need to invent a protocol that indicates something different when the signal is a 1 than when it’s a 0 – but also has a voltage transition at every “bit” – every value. One way to do this is to say that, whenever the signal is a 1, we make an extra voltage transition. This strategy is called a “bi-phase mark”, an example of which is shown below in Figure 2.
Fig 2: The same signal, transmitted as a bi-phase mark.
Notice in Figure 2 that there is a voltage transition (either from low to high or from high to low) between each value (0 or 1), so the receiver can use this to known when to measure the voltage (a characteristic that is known as “self-clocking” because the clock information is built into the signal itself). A 0 can either be a low voltage or a high voltage – as long as it doesn’t change. A 1 is represented as a quick “high-low” or a “low-high”.
This is basically the way S-PDIF and AES/EBU work. Their voltage values are slightly different than the ones shown in Figure 2 – and there are many more small details to worry about – but the basic concept of a bi-phase mark is used in both transmission systems.
Detecting the clock
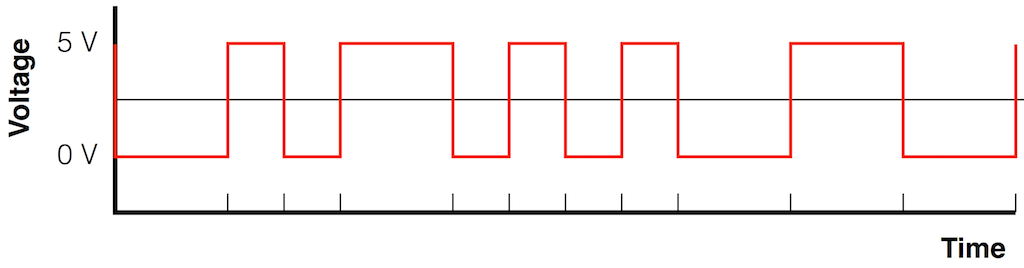
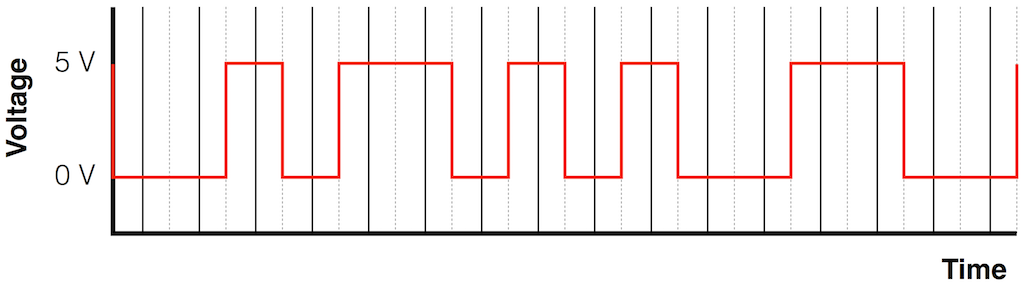
Let’s say that you’re given the task of detecting the clock in the signal shown in Figure 2, above. The simplest way to do this is to draw a line that is half-way between the low and the high voltages and detect when the voltage crosses that line, as shown in Figure 3.
Fig 3: The blue arrows show when the voltage signal crosses the middle line – indicating events that might be used to generate a clock.
The nice thing about this method is that you don’t need to know what the actual voltages are – you just pick a voltage that’s between the high and low values, call that your threshold – and if the signal crosses the threshold (in either direction) you call that an event.
Real-world square waves
So far so good. We have a digital audio signal, we can encode it as an electrical signal, we can transmit that signal over a wire to a device that can derive the clock (and therefore ultimately, the sampling rate) from the signal itself…
One small comment here: although the audio signal that we’re transmitting has been encoded as a digital representation (1’s and 0’s) the electrical signal that we’re using to transmit it is analogue. It’s just a change in voltage over time. In essence, the signal shown in Figure 2 is an analogue square wave with a frequency that is modulating between two values.
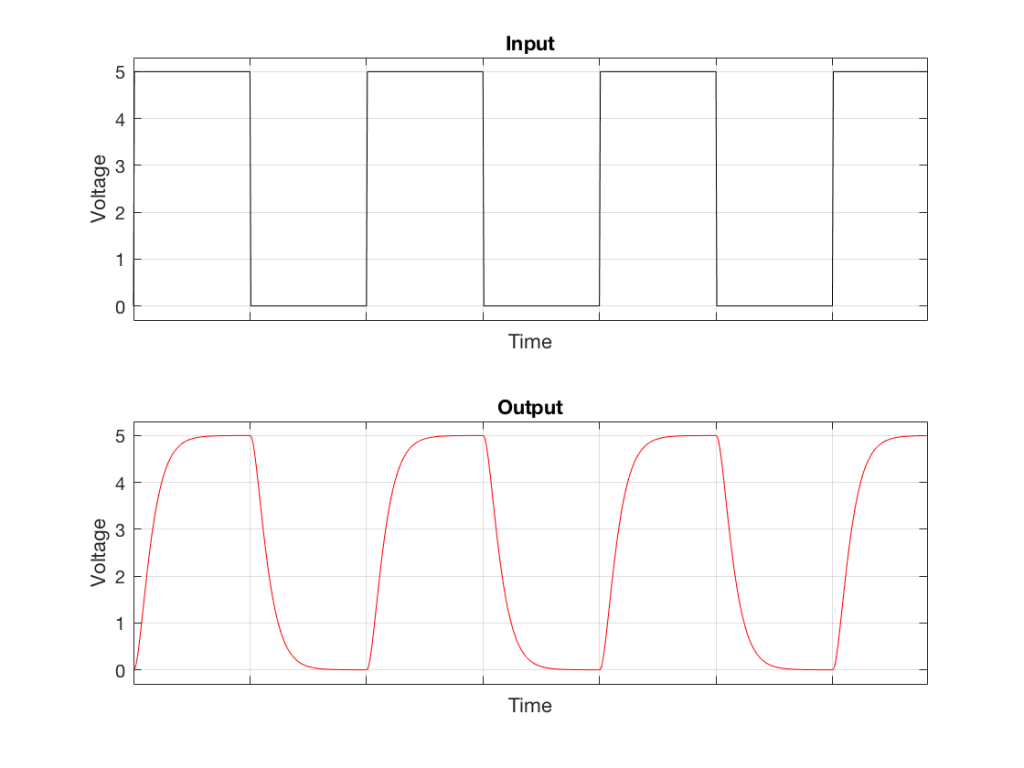
Now let’s start getting real. In order to create a square wave, you need to be able to transition from one voltage to another voltage instantaneously (this is very fast). This means that, in order to be truly square, the vertical lines in all of the above figures must be really vertical, and the corners must be 90º. In order for both of these things to be true, the circuitry that is creating the voltage signal must have an infinite bandwidth. In other words, it must have the ability to deliver a signal that extends from 0 Hz (or DC) up to ∞ Hz. If it doesn’t, then the square wave won’t really be square.
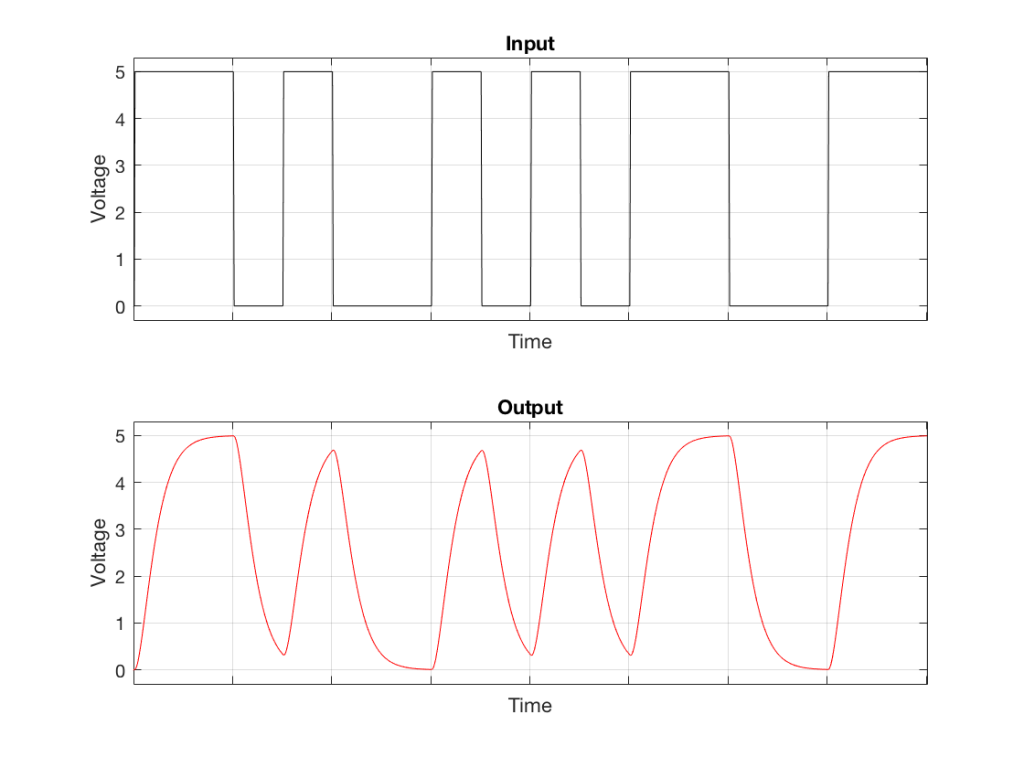
What happens if we try to transmit a square wave through a system that doesn’t extend all the way to ∞ Hz (in other words, “what happens if we filter the high frequencies out of a square wave? What does it look like?”) Figure 4, below shows an example of what we can expect in this case.
Fig 4. The top plot is a square wave. The bottom plot is the result of sending that square wave through a low-pass filter (therefore reducing the high-frequency content). Notice that the 90º angles have been increased a little – and that the vertical transitions are no longer vertical.
Note that Figure 4 is just an example… The exact shape of the output (the red curve) will be dependent on the relationship between the fundamental frequency of the square wave and the cutoff frequency of the low-pass filter – or, more accurately, the frequency response of the system.
What time is it there?
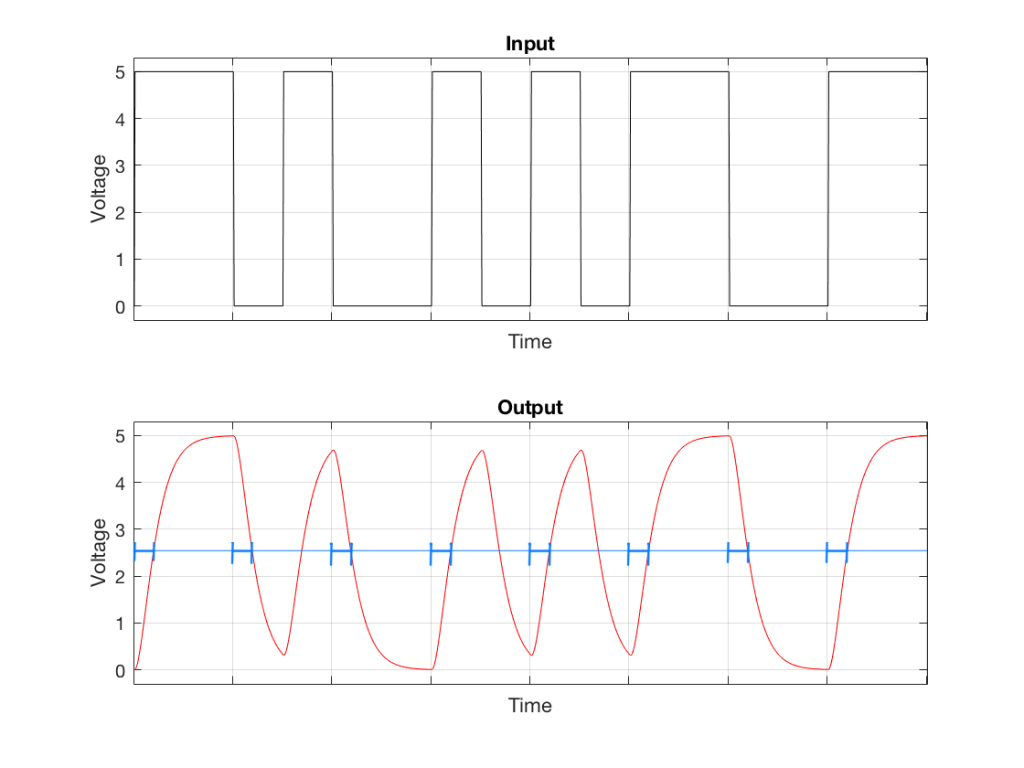
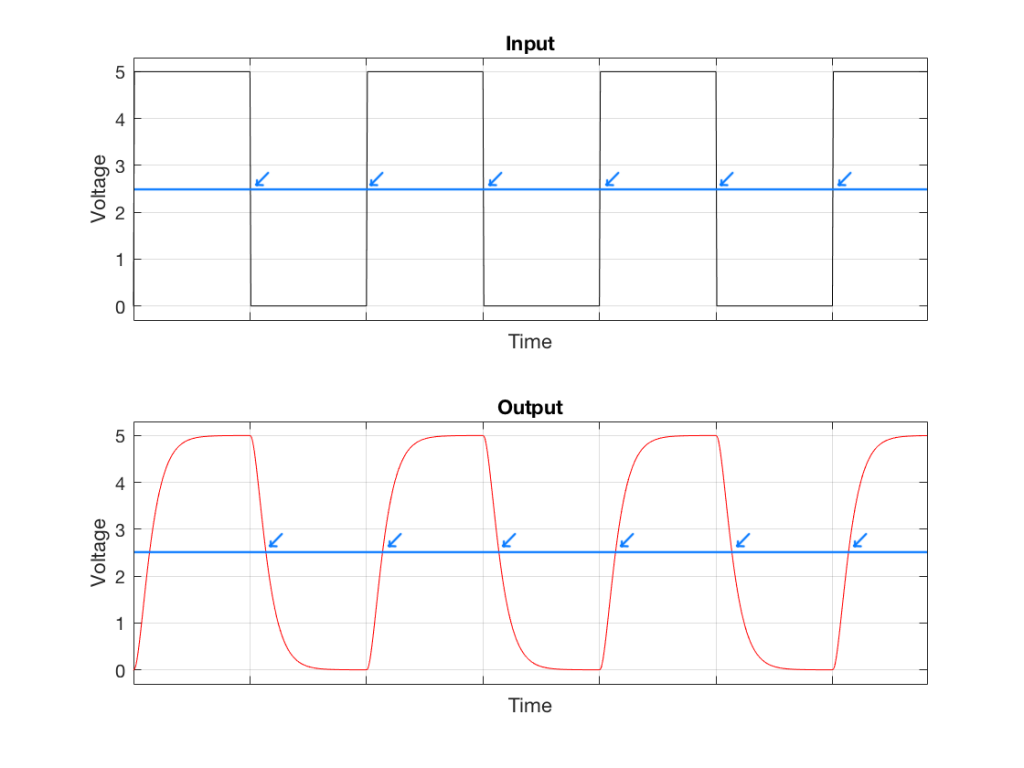
Look carefully at the two curves in Figure 4. The tick marks on the “Time” axes show the time that the voltage should transition from low to high or vice versa. If we were to use our simple method for detecting voltage transitions (shown in Figure 3) then it would be wrong…
Fig 5: The simple method of detecting the transition time results in an error when the square wave isn’t square. Notice that the blue arrows in the lower plot are all late compared to the time when the transition started.
As you can see in Figure 5, the system that detects the transition time is always late when the square wave is low-pass filtered. In this particular case, it’s always late by the same amount, so we aren’t too worried about it – but this won’t always be true…
For example, what happens when the signal that we’re low-pass filtering is a bi-phase mark (which means that it’s a square wave with a modulated fundamental frequency) instead of a simple square wave with a fixed frequency?
Fig 6. The top plot shows the same signal plotted in Figure 2 – a bi-phase representation of the binary value 01011000. The bottom plot shows a low-pass filtered version of that signal.
As you can see in Figure 6, the low pass filter has a somewhat strange effect on the modulated square wave. Now, when the binary value is a “1”, and the square wave frequency is high, there isn’t enough time for the voltage to swing all the way to the new value before it has to turn around and go back the other way. Because it never quite gets to where it’s going (vertically) then there is a change in when it crosses our threshold of detection (horizontally), as is shown below.
Fig 7: The time that the red plot crosses our threshold is always late – but it’s late by a different amount each time, depending on the signal itself… (In other words, some of those blue H’s are wider than others…)
The conclusion (for now)
IF we were to make a digital audio transmission system AND
IF that system used a biphase mark as its protocol AND
IF transmission was significantly band-limited AND
IF we were only using this simple method to derive the clock from the signal itself
THEN the clock for our receiving device would be incorrect. It would not just be late, but it would vary over time – sometimes a little later than other times… And therefore, we have a system with wander and/or jitter.
It’s important for me to note that the example I’ve given here about how that jitter might come to be in the first place is just one version of reality. There are lots of types of jitter and lots of root causes of it – some of which I’ll explain in this series of postings.
In addition, there are times when you need to worry about it, and times when you don’t – no matter how bad it is. And then, there are the sneaky times when you think that you don’t need to worry about it, but you really do…