Category: audio
Closeup on vinyl
DFT’s Part 2: It’s a little complex…
Links to:
DFT’s Part 1: Some introductory basics
Whole Numbers and Integers
Once upon a time you learned how to count. You were probably taught to count your fingers… 1, 2, 3, 4 and so on. Although no one told you so at the time, you were being taught a set of numbers called whole numbers.
Sometime after that, you were probably taught that there’s one number that gets tacked on before the ones you already knew – the number 0.
A little later, sometime after you learned about money and the fact that we don’t have enough, you were taught negative numbers… -1, -2, -3 and so on. These are the numbers that are less than 0.
That collection of numbers is called integers – all “countable” numbers that are negative, zero and positive. So the collection is typically written
… -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5 …
Rational Numbers
Eventually, after you learned about counting and numbers, you were taught how to divide (the mathematical word for “sharing equally”). When someone said “20 divided by 5 equals 4” then they meant “if you have 20 sticks, then you could put those sticks in 4 piles with 5 sticks in each pile.” Eventually, you learned that the division of one number by another can be written as a fraction like 3/1 or 20/5 or 5/4 or 1/3.
If you do that division the old-fashioned way, you get numbers like this:
3 ∕ 1 = 3.000000000 etc…
20 ∕ 5 = 4.00000000 etc…
5 ∕ 4 = 1.200000000 etc…
1 ∕ 3 = 0.333333333 etc…
The thing that I’m trying to point out here is that eventually, these numbers start repeating sometime after the decimal point. These numbers are called rational numbers.
Irrational Numbers
What happens if you have a number that doesn’t start repeating, no matter how many numbers you have? Take a number like the square root of 2 for example. This is a number that, when you multiply it by itself, results in the number 2. This number is approximately 1.4142. But, if we multiply 1.4142 by 1.4142, we get 1.99996164 – so 1.4142 isn’t exactly the square root of 2. In fact, if we started calculating the exact square root of 2, we’d result in a number that keeps going forever after the decimal place and never repeats. Numbers like this (π is another one…) that never repeat after the decimal are called irrational numbers
Real Numbers
All of these number types – rational numbers (which includes integers) and irrational numbers fall under the general heading of real numbers. The fact that these are called “real” implies immediately that there is a classification of numbers that are “unreal” – but we’ll get to that later…
Imaginary Numbers
Let’s think about the idea of a square root. The square root of a number is another number which, when multiplied by itself is the first number. For example, 3 is the square root of 9 because 3*3 = 9. Let’s consider this a little further: a positive number muliplied by itself is a positive number (for example, 4*4 = 16… 4 is positive and 16 is also positive). A negative number multiplied by itself is also positive (i.e. –4*-4 = 16).
Now, in the first case, the square root of 16 is 4 because 4*4 = 16. (Some people would be really picky and they’ll tell you that 16 has two roots: 4 and -4. Those people are slightly geeky, but technically correct.) There’s just one small snag – what if you were asked for the square root of a negative number? There is no such thing as a number which, when multiplied by itself results in a negative number. So asking for the square root of -16 doesn’t make sense. In fact, if you try to do this on your calculator, it’ll probably tell you that it gets an error instead of producing an answer.
For a long time, mathematicians just called the square root of a negative number “imaginary” since it didn’t exist – like an imaginary friend that you had when you were 2… However, mathematicians as a general rule don’t like loose ends – they aren’t the type of people who leave things lying around… and having something as simple as the square root of a negative number lying around unanswered got on their nerves.
Then, in 1797, a Norwegian surveyor named Casper Wessel presented a paper to the Royal Academy of Denmark that described a new idea of his. He started by taking a number line that contains all the real numbers like this:

He then pointed out that multiplying a number by -1 was the same as rotating by an angle of 180º, like this:
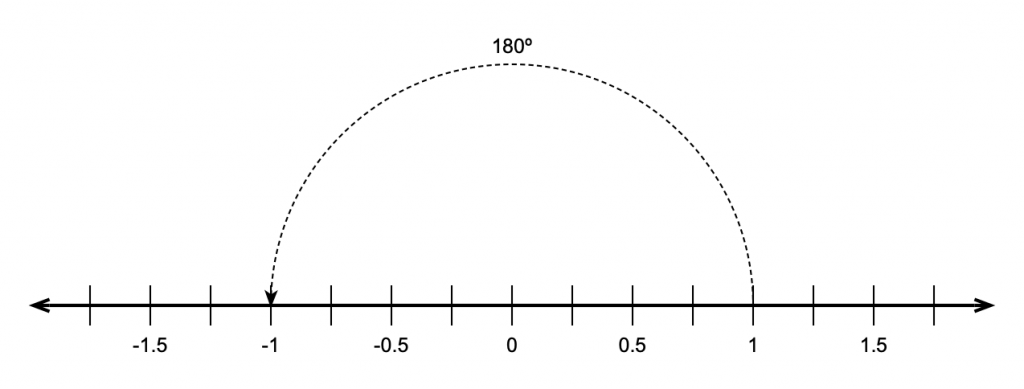
He then reasoned that, if this were true, then the square root of -1 must be the same as rotating by 90º.
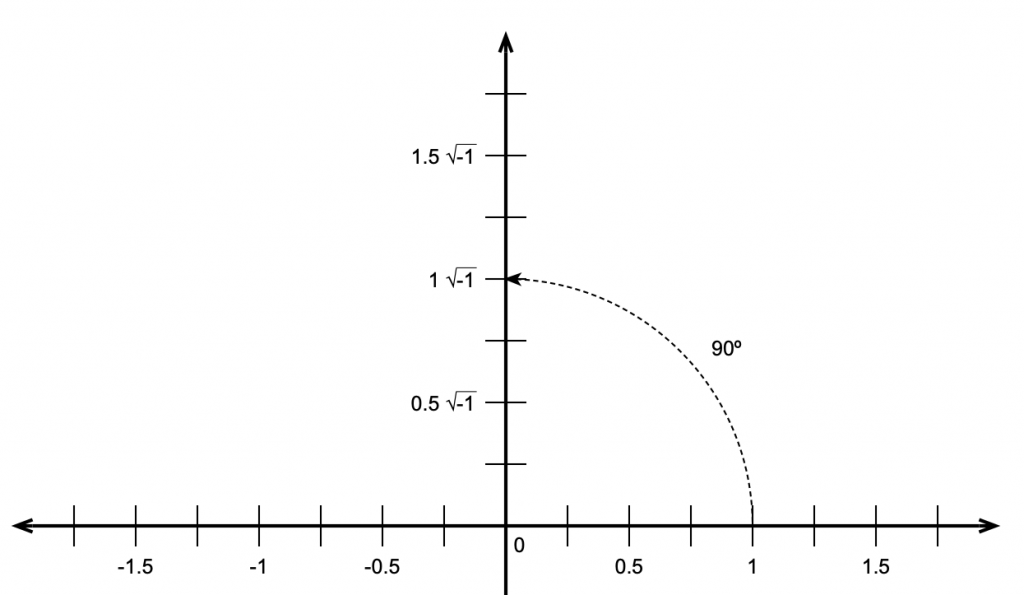
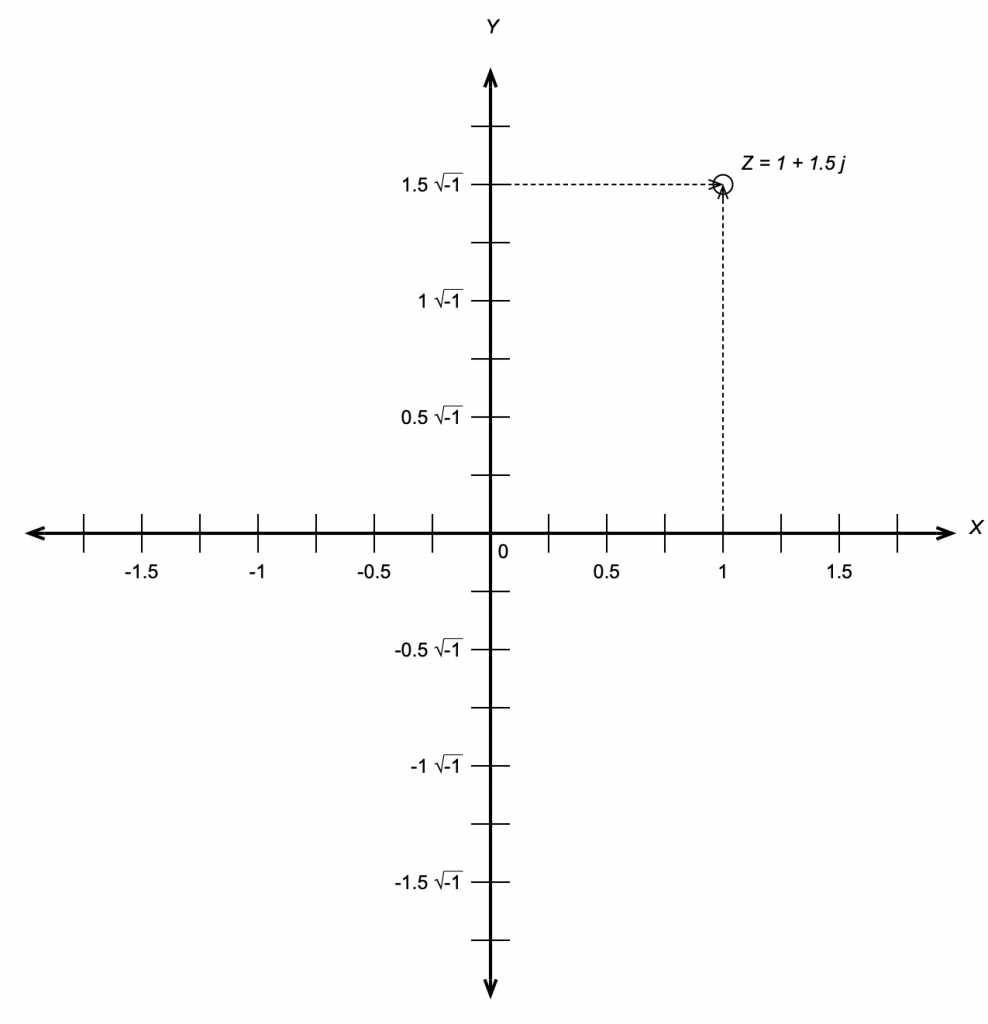
This meant that the number line we started with containing the real numbers is the X-axis on a 2-dimensional plane where the Y-axis contains the imaginary numbers. That plane is called the Z plane, where any point (which we’ll call ‘Z’) is the combination of a real number (X) and an imaginary number (Y).
If you look carefully at Figure 4, you’ll see that I used a “j” to indicate the imaginary portion of the number. Generally speaking, mathematicians use i and physicists and engineers use j so we’ll stick with j. (The reason physics and engineering people use j is that they use i to mean “electrical current”.)
“What is j?” I hear you cry. Well, j is just the square root of -1. Of course, there is no number that is the square root of -1
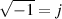
and therefore
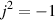
Now, remember that j * j = -1. This is useful for any square root of any negative number, you just calculate the square root of the number pretending that it was positive, and then stick a j after it. So, since the square root of 16, abbreviated sqrt(16) = 4 and sqrt(-1) = j, then sqrt(-16) = 4j.
Complex numbers
Now that we have real and imaginary numbers, we can combine them to create a complex number. Remember that you can’t just mix real numbers with imaginary ones – you keep them separate most of the time, so you see numbers like
3+2j
This is an example of a complex number that contains a real component (the 3) and an imaginary component (the 2j). In some cases, these numbers are further abbreviated with a single Greek character, like α or β, so you’ll see things like
α = 3+2j
In other cases, you’ll see a bold letter like the following:
Z = 3+2j
A lot of people do this because they like reserving Greek letters like α and ϕ for variables associated with angles.
Personally, I like seeing the whole thing – the real and the imaginary components – no reducing them to single Greek letters (they’re for angles!) or bold letters.
Absolute Value (aka the Modulus)
The absolute value of a complex number is a little weirder than what we usually think of as an absolute value. In order to understand this, we have to look at complex numbers a little differently:
Remember that j*j = -1.
Also, remember that, if we have a cosine wave and we delay it by 90º and then delay it by another 90º, it’s the same as inverting the polarity of the cosine, in other words, multiplying the cosine by -1. So, we can think of the imaginary component of a complex number as being a real number that’s been rotated by 90º, we can picture it as is shown in the figure below.
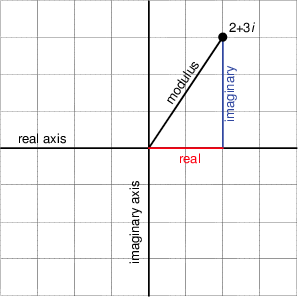
Notice that Figure 5 actually winds up showing three things. It shows the real component along the x-axis, the imaginary component along the y-axis, and the absolute value or modulus of the complex number as the hypotenuse of the triangle. This is shown in mathematical notation in exactly the same way as in normal math – with vertical lines. For example, the modulus of 2+3j is written |2+3j|
This should make the calculation for determining the modulus of the complex number almost obvious. Since it’s the length of the hypotenuse of the right triangle formed by the real and imaginary components, and since we already know the Pythagorean theorem then the modulus of the complex number (a + b j) is
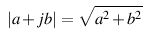
Given the values of the real and imaginary components, we can also calculate the angle of the hypotenuse from horizontal using the equation
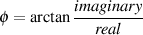
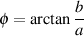
This will come in handy later.
Complex notation or… Who cares?
This is probably the most important question for us. Imaginary numbers are great for mathematicians who like wrapping up loose ends that are incurred when a student asks “what’s the square root of -1?” but what use are complex numbers for people in audio? Well, it turns out that they’re used all the time, by the people doing analog electronics as well as the people working on digital signal processing. We’ll get into how they apply to each specific field in a little more detail once we know what we’re talking about, but let’s do a little right now to get a taste.
In the previous posting, that introduces the trigonometric functions sine and cosine, we looked at how both functions are just one-dimensional representations of a two-dimensional rotation of a wheel. Essentially, the cosine is the horizontal displacement of a point on the wheel as it rotates. The sine is the vertical displacement of the same point at the same time. Also, if we know either one of these two components, we know:
- the diameter of the wheel and
- how fast it’s rotating
but we need to know both components to know the direction of rotation.
At any given moment in time, if we froze the wheel, we’d have some contribution of these two components – a cosine component and a sine component for a given angle of rotation. Since these two components are effectively identical functions that are 90º apart (for example, a cossine wave is the same as a sine that’s been delayed by 90º) and since we’re thinking of the real and imaginary components in a complex number as being 90º apart, then we can use complex math to describe the contributions of the sine and cosine components to a signal.
Huh?
Let’s look at an example. If the signal we wanted to look at a signal that consisted only of a cosine wave, then we’d know that the signal had 100% cosine and 0% sine. So, if we express the cosine component as the real component and the sine as the imaginary, then what we have is:
1 + 0 j
If the signal were an upside-down cosine, then the complex notation for it would be (–1 + 0 j) because it would essentially be a cosine * -1 and no sine component. Similarly, if the signal was a sine wave, it would be notated as (0 – 1 j).
This last statement should raise at least one eyebrow… Why is the complex notation for a positive sine wave (0 – 1 j)? In other words, why is there a negative sign there to represent a positive sine component? (Hint – we want the wheel to turn clockwise… and clocks turn clockwise to maintain backwards compatibility with an earlier technology – the sundial. So, we use a negative number because of the direction of rotation of the earth…)
This is fine, but what if the signal looks like a sinusoidal wave that’s been delayed a little? As we saw in the previous posting, we can create a sinusoid of any delay by adding the cosine and sine components with appropriate gains applied to each.
So, is we made a signal that were 70.7% sine and 70.7% cosine. (If you don’t know how I arrived that those numbers, check out the previous posting.) How would you express this using complex notation? Well, you just look at the relative contributions of the two components as before:
0.707 – 0.707 j
It’s interesting to notice that, although this is actually a combination of a cosine and a sine with a specific ratio of amplitudes (in this case, both at 0.707 of “normal”), the result will look like a sine wave that’s been shifted in phase by -45º (or a cosine that’s been phase-shifted by 45º). In fact, this is the case – any phase-shifted sine wave can be expressed as the combination of its sine and cosine components with a specific amplitude relationship.
Therefore (again), any sinusoidal waveform with any phase can be simplified and expressed as its two elemental components, the gains applied to the cosine (or real) and the sine (or imaginary). Once the signal is broken into these two constituent components, it cannot be further simplified.
DFT’s Part 1: Some introductory basics
This is the first posting in a 6-part series on doing and understanding Fourier Transforms – specifically with respect to audio signals in the digital domain. However, before we dive into DFT’s (more commonly knowns as “FFT’s”, as we’ll talk about in the next posting) we need to get some basic concepts out of the way first.
Frequency
When a normal person says “frequency” they mean “how often something happens”. I go to the dentist with a frequency of two times per year. I eat dinner with a frequency of one time per day.
When someone who works in audio says “frequency” they mean something like “the number of times per second this particular portion of the audio waveform repeats – even if it doesn’t last for a whole second…”. And, if we’re being a little more specific, then we are a bit more effuse than saying “this particular portion”… but I’m getting ahead of myself.
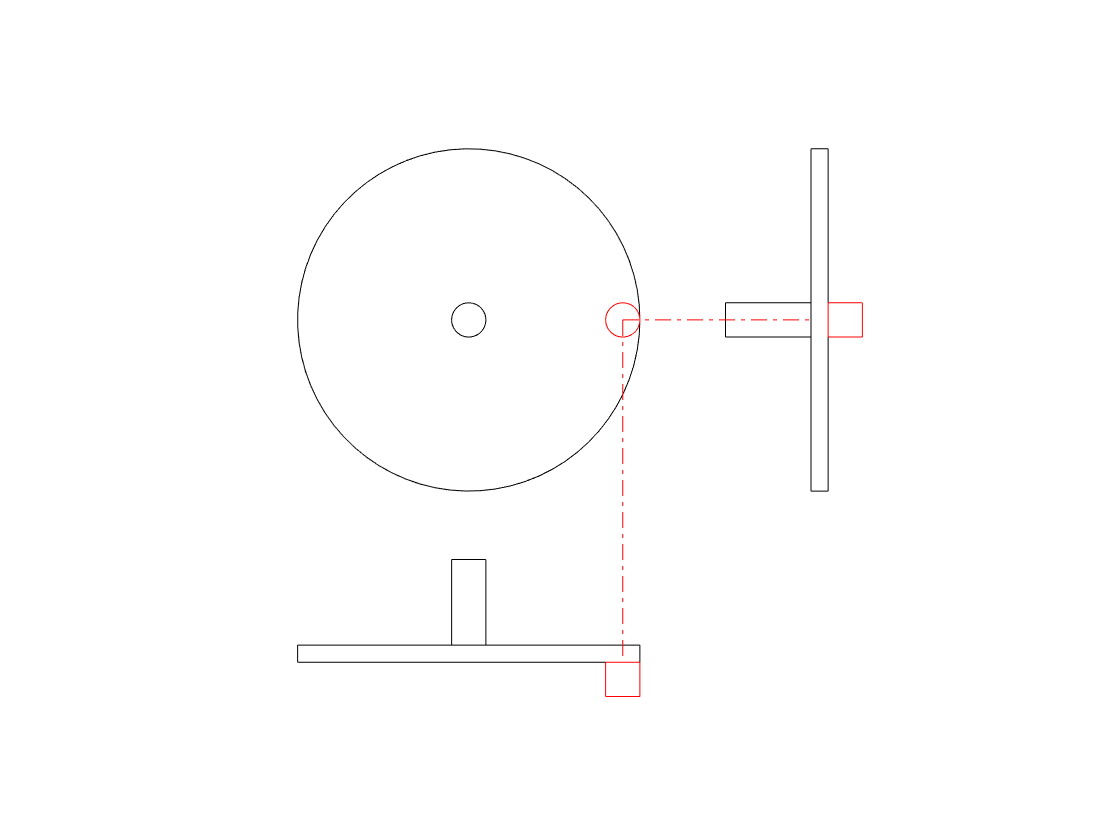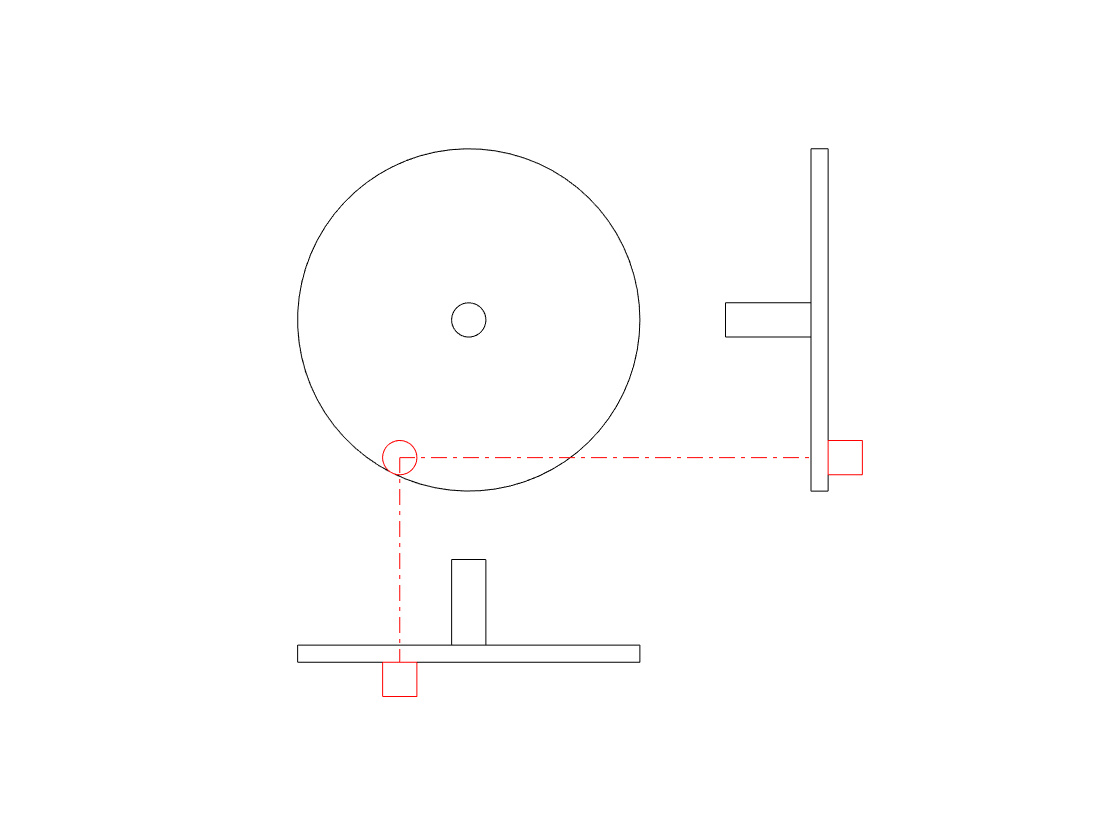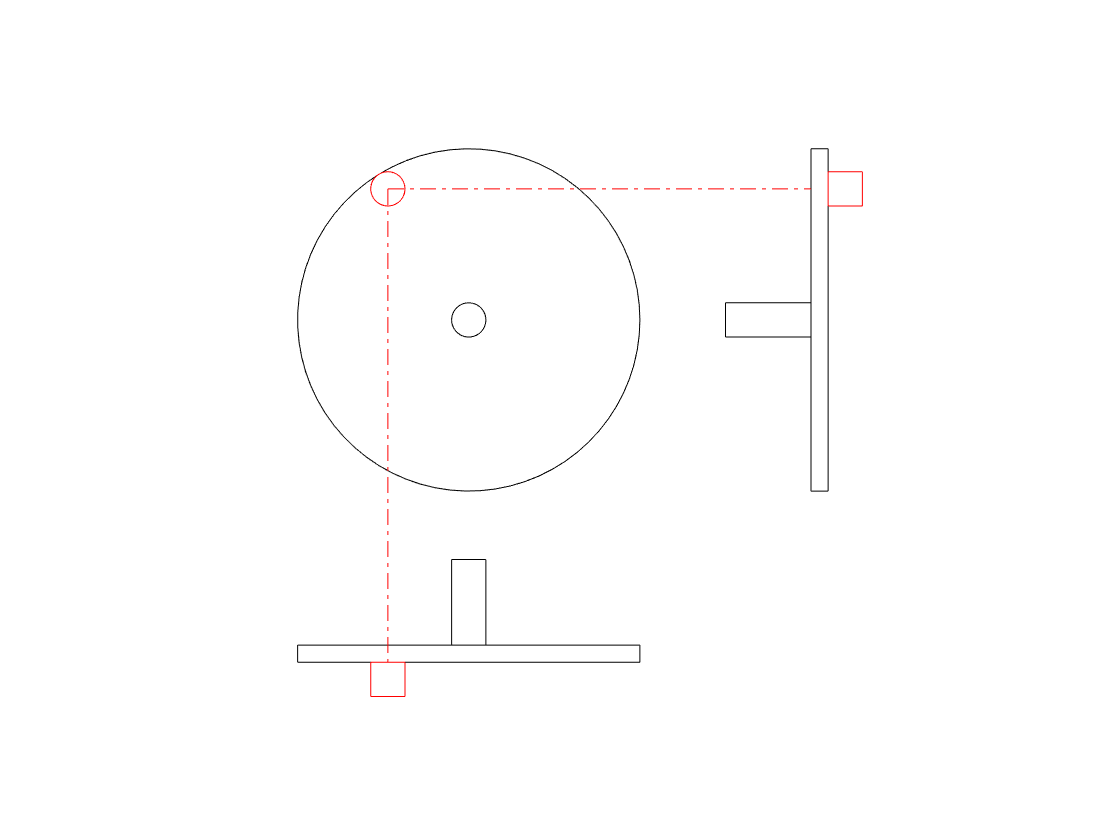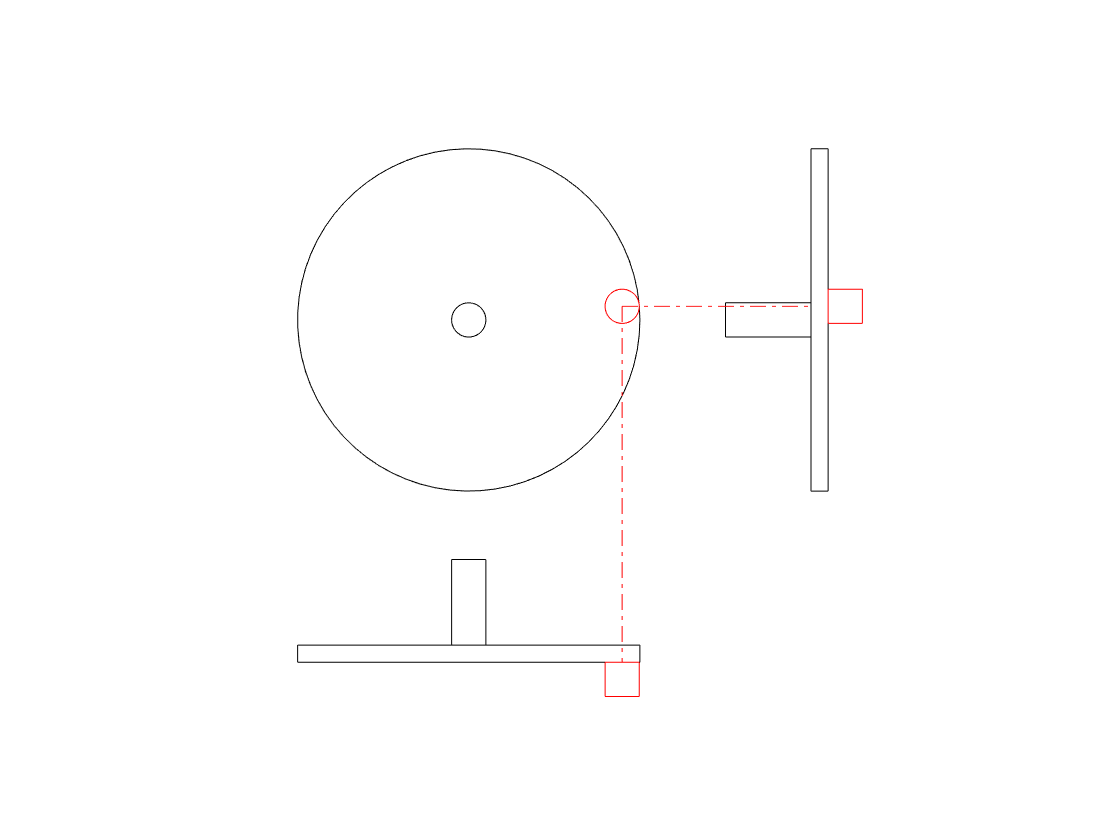
Let’s take a wheel with an axel, and a handle sticking out of it on its edge, like this:

We’ll turn the wheel clockwise, at a constant speed, or “frequency of rotation” – with some number of revolutions per second. If we look at the wheel from the “front” – its face – then we’ll see something like this:
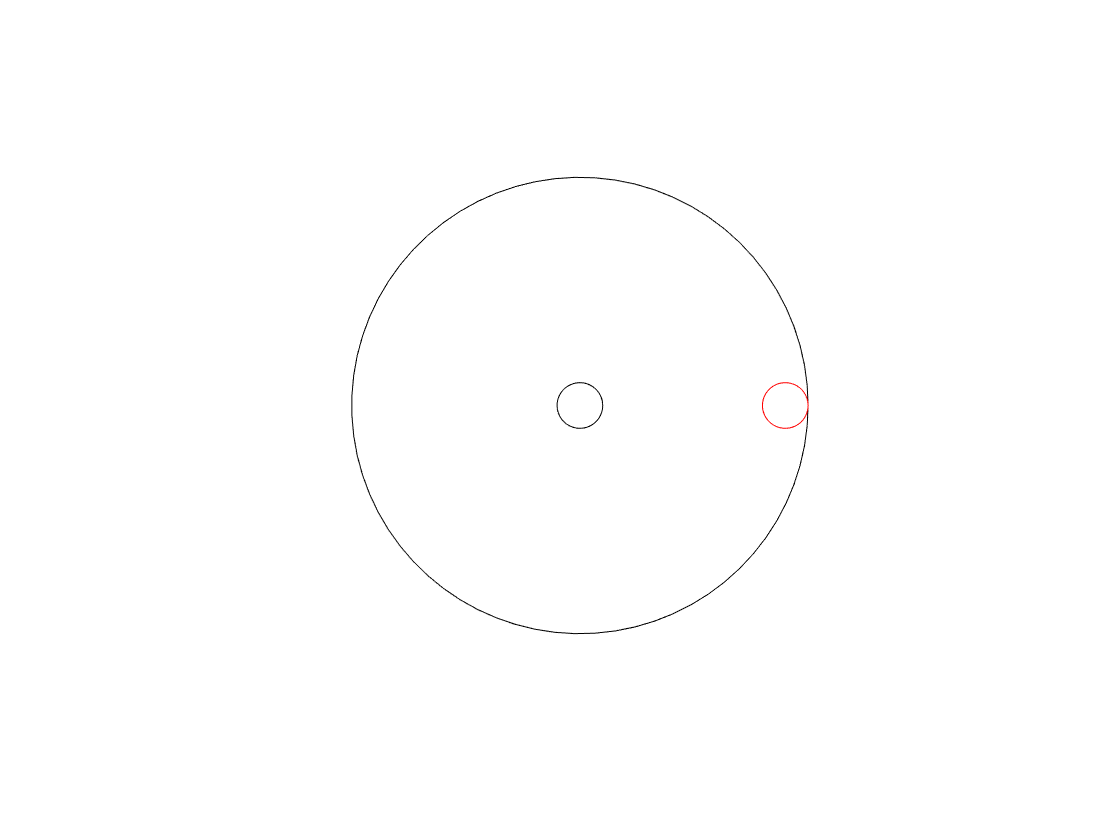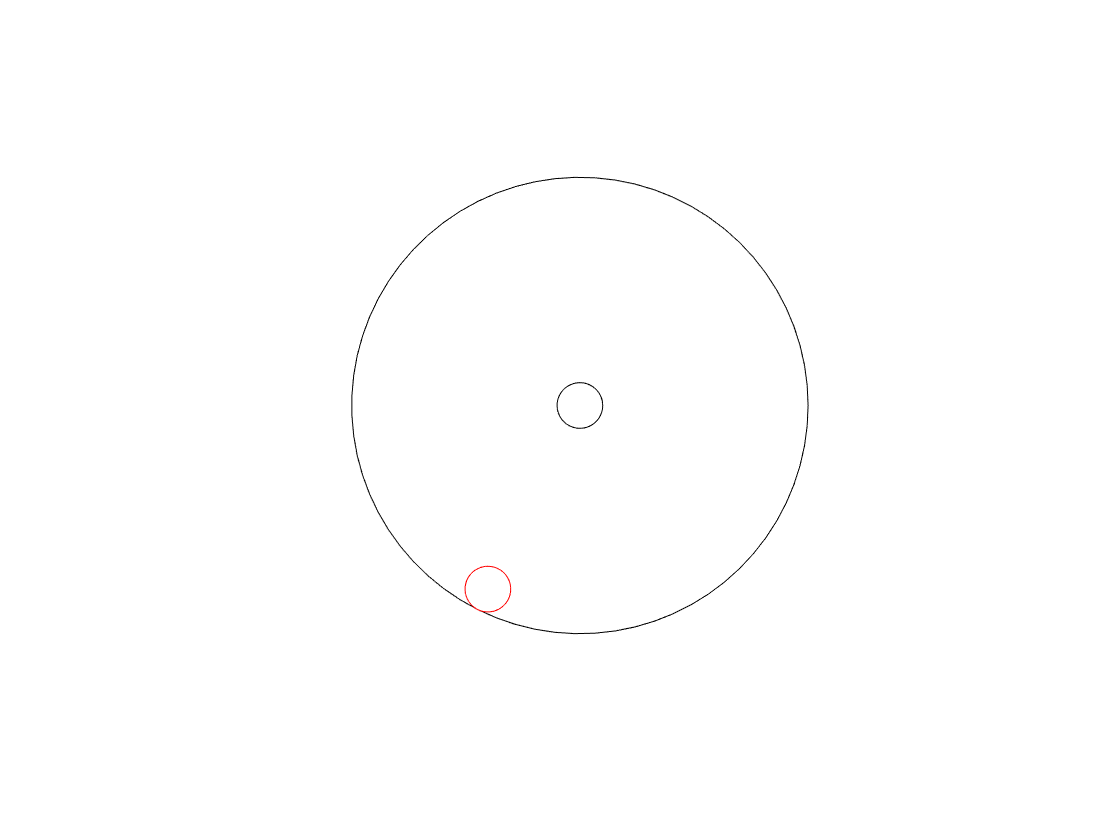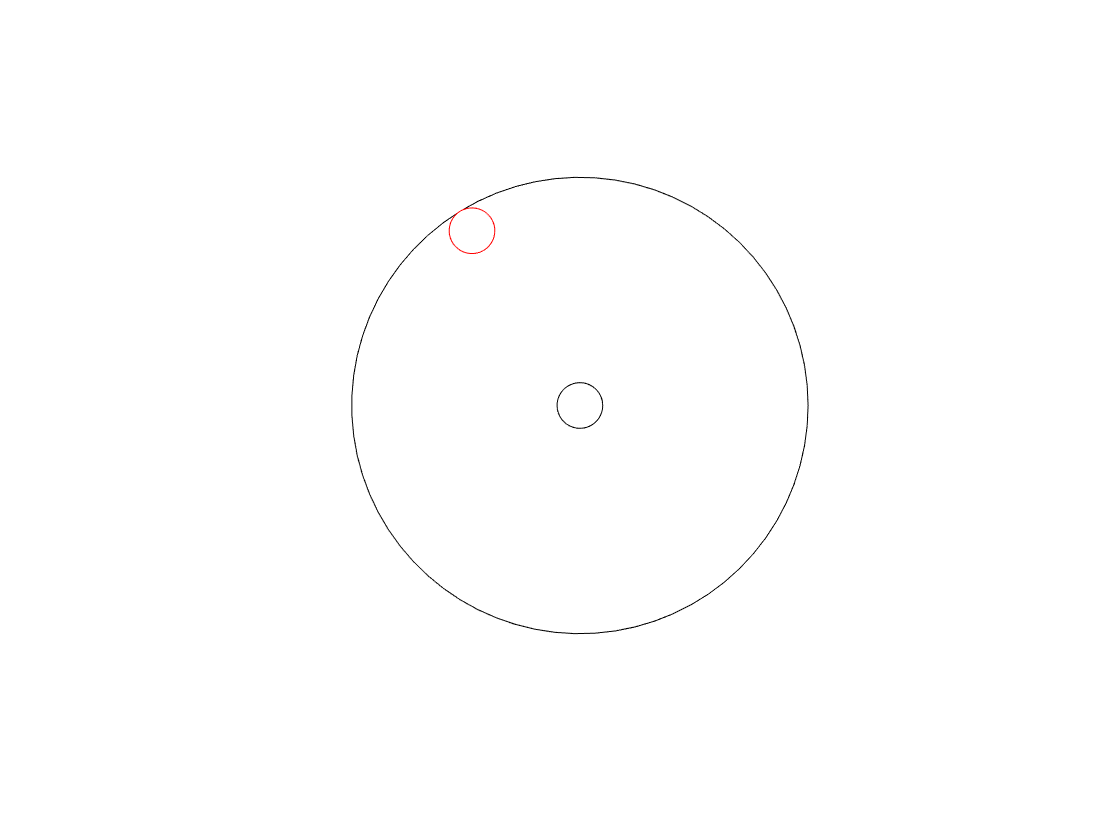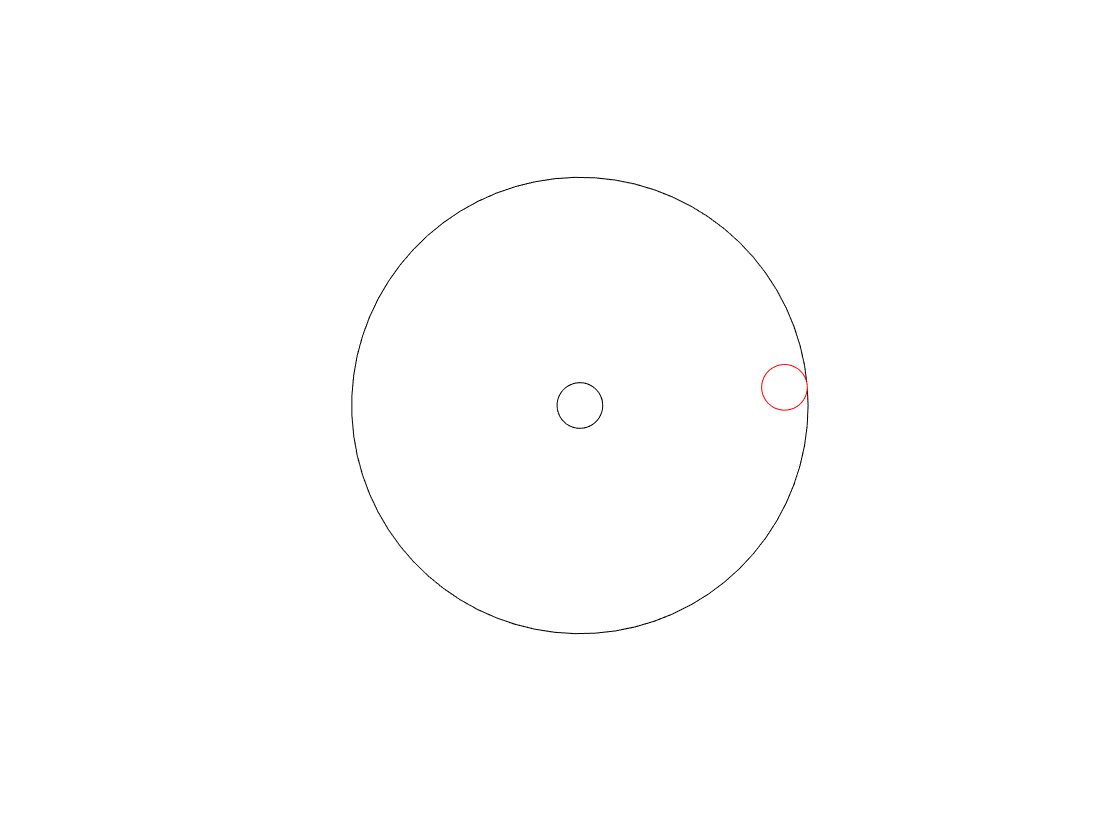
When we look at the front of the wheel, we can tell its diameter (the “size” of the wheel), the frequency at which it’s rotating (in revolutions or cycles per second), and the direction (clockwise or anti-clockwise).
One way to look at the rotation is to consider the position of the handle – the red circle above – as an angle. If it started at the “3 o’clock” position, and it’s rotating clockwise, then it rotated 90 degrees when it’s at the “6 o’clock” position, for example.
However, another way to think about the movement of the handle is to see it as simultaneously moving up and down as it moves side-to-side. Again, if it moves from the 3 o’clock position to the 6 o’clock position, then it moved downwards and to the left.
We can focus on the vertical movement only if we look at the side of the wheel instead of its face, as shown in the right-hand side of the animation below.
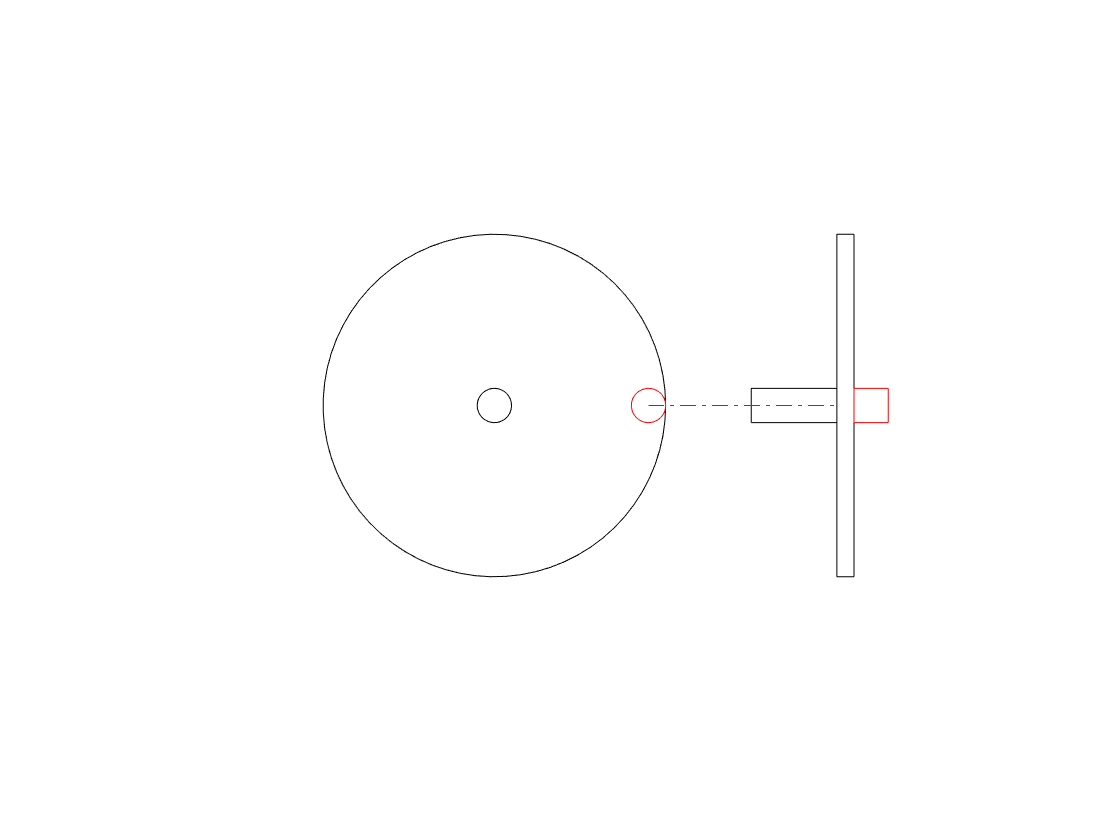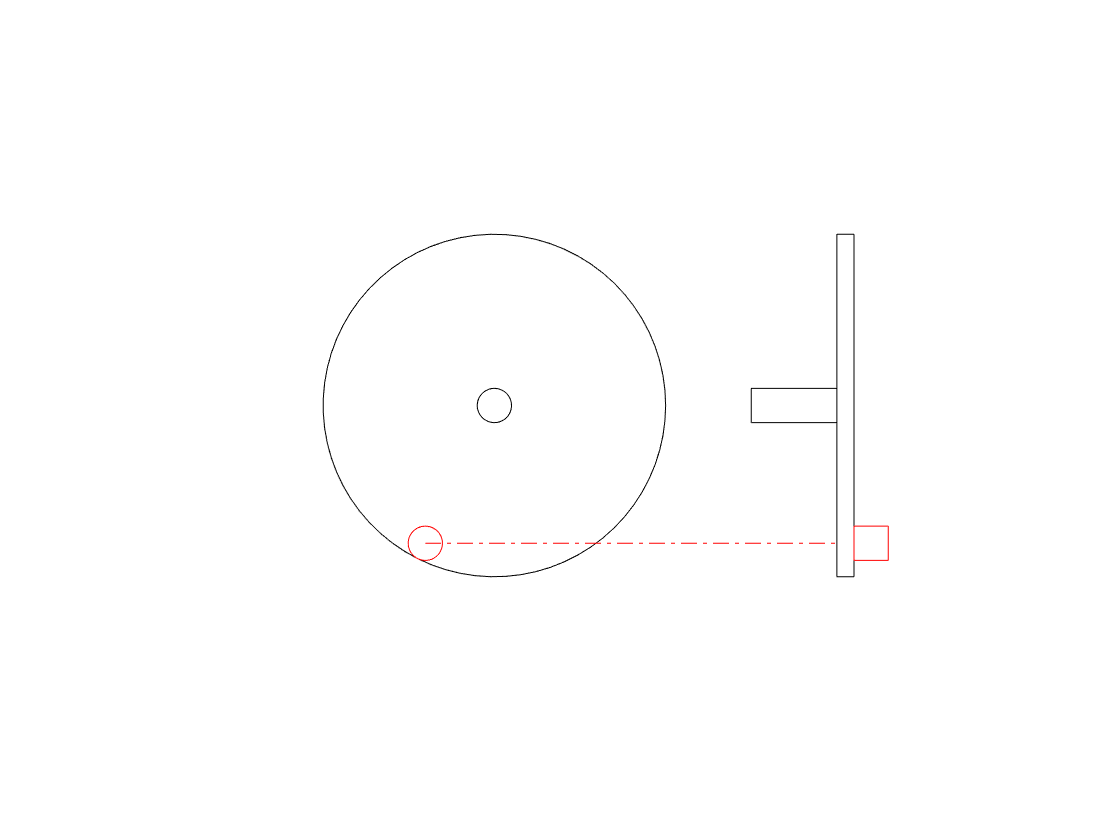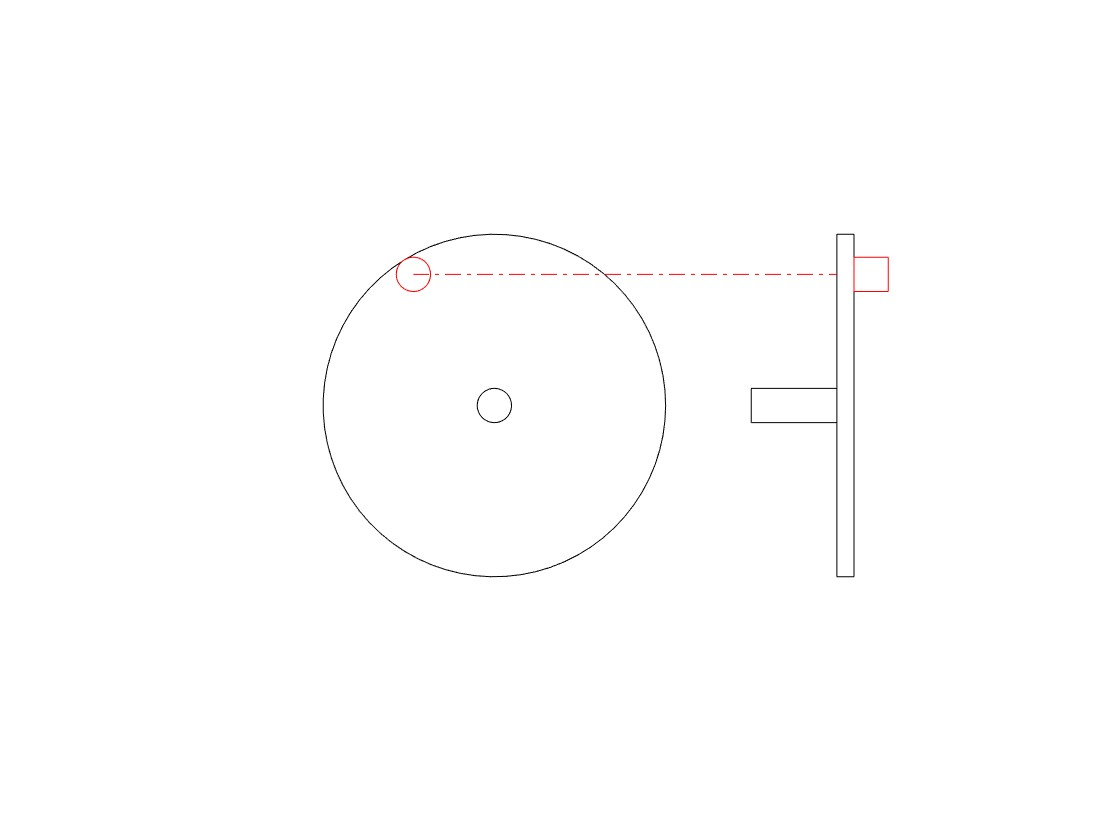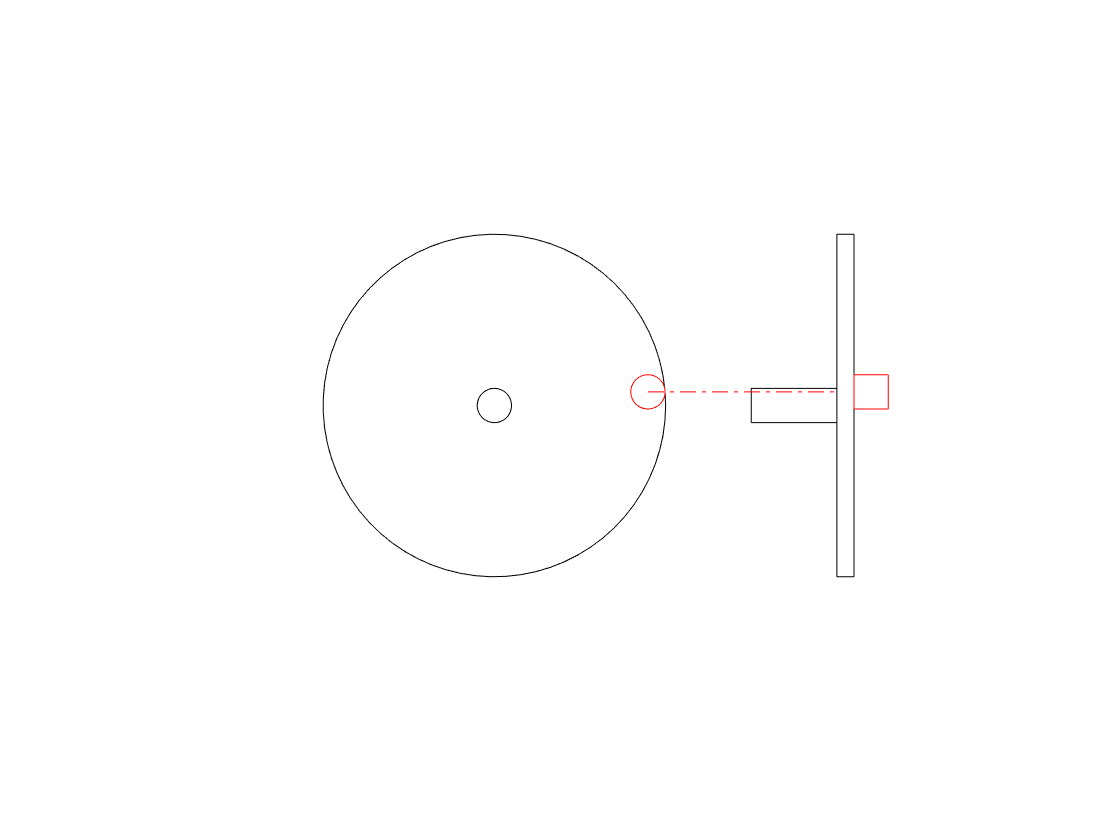
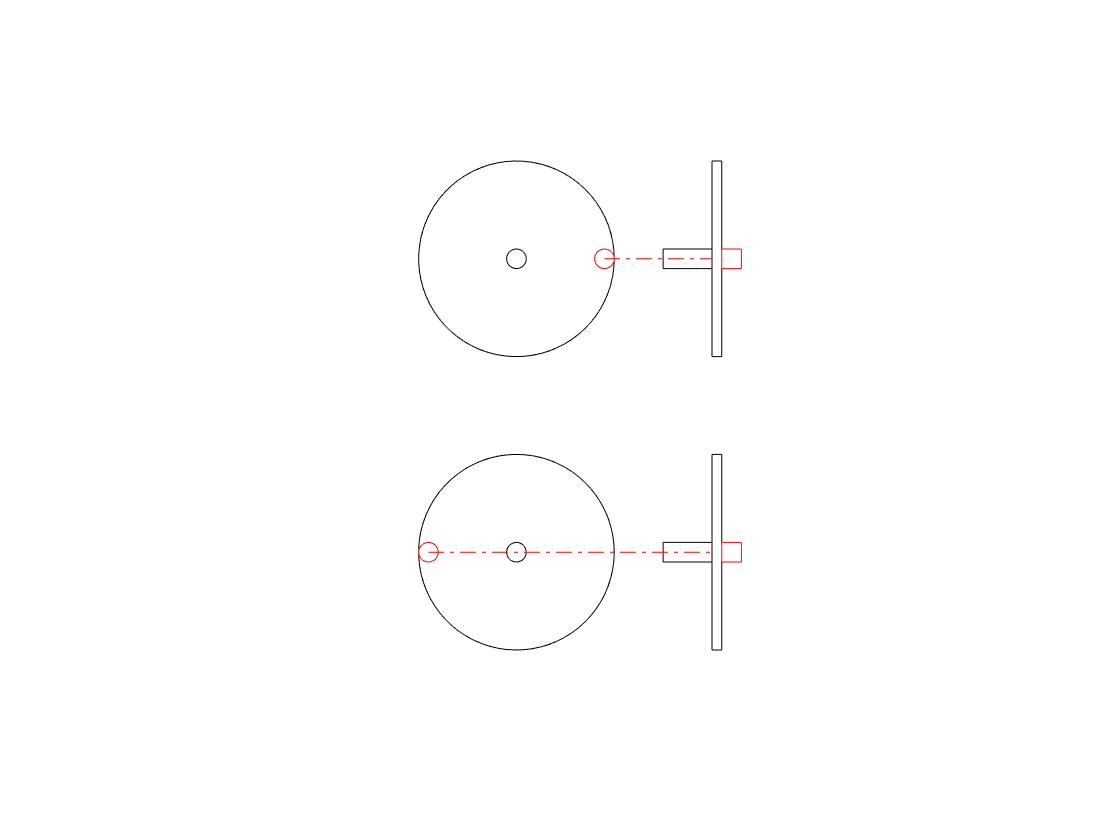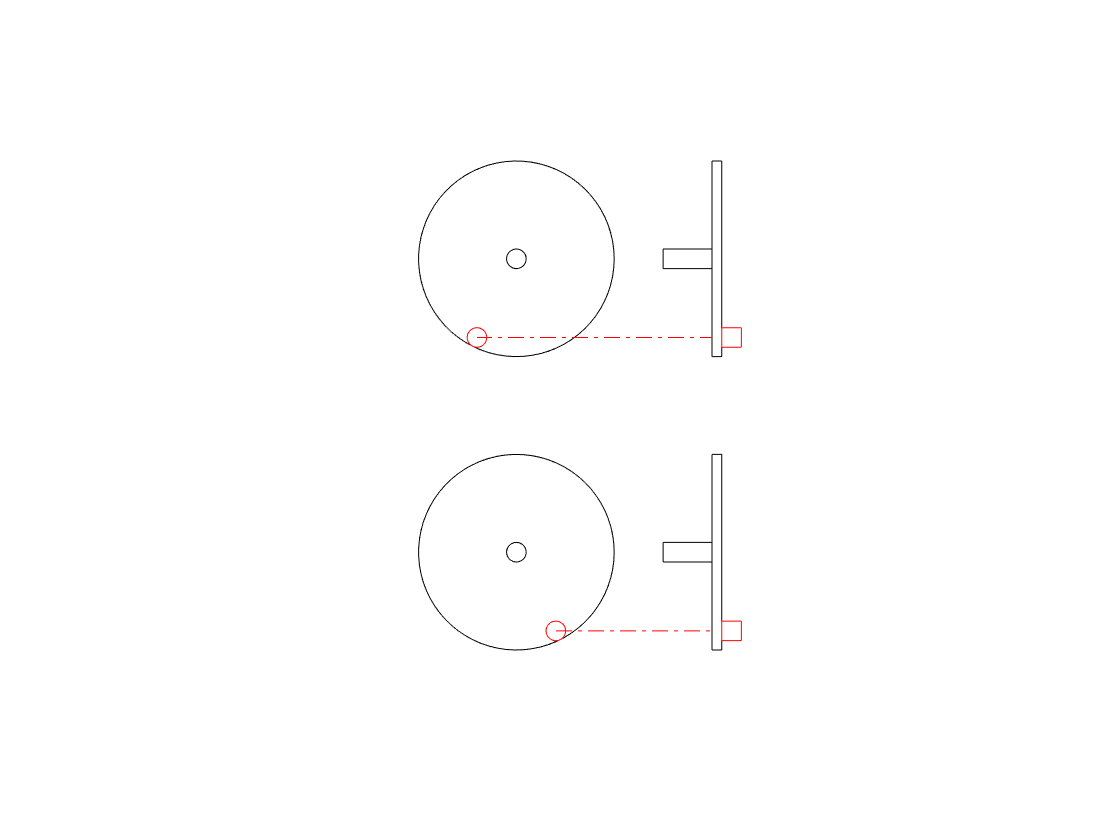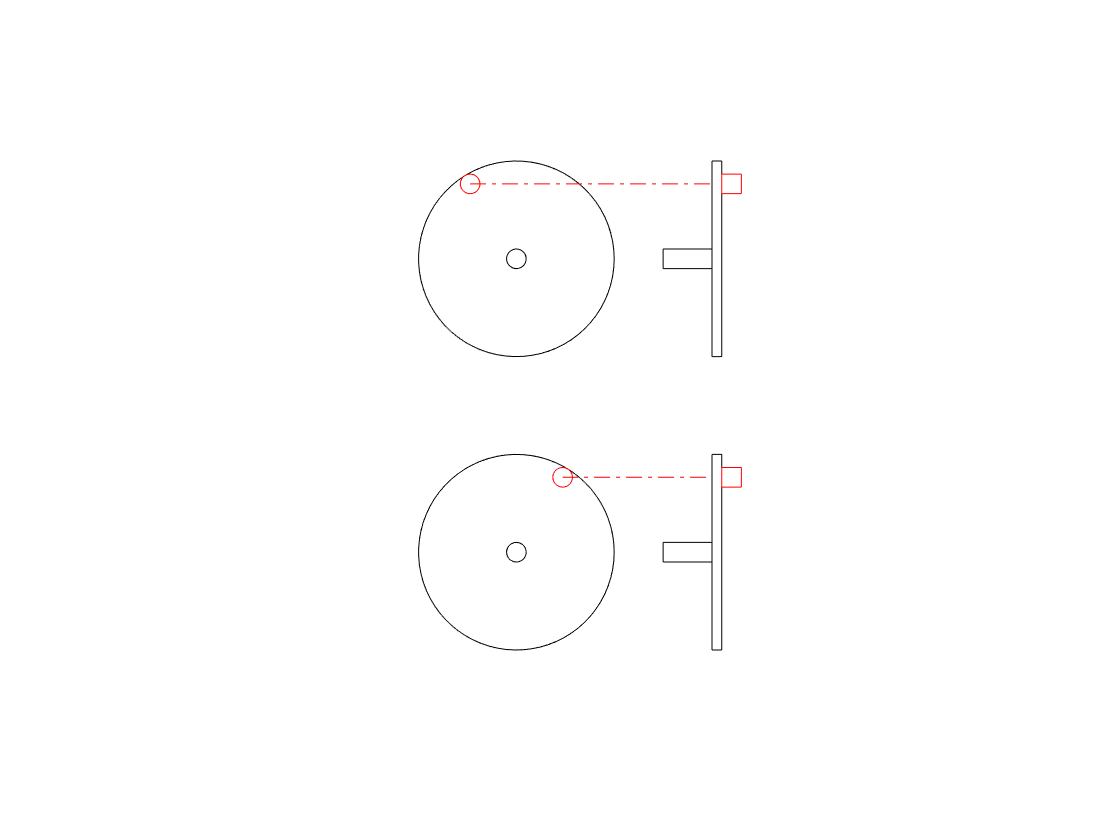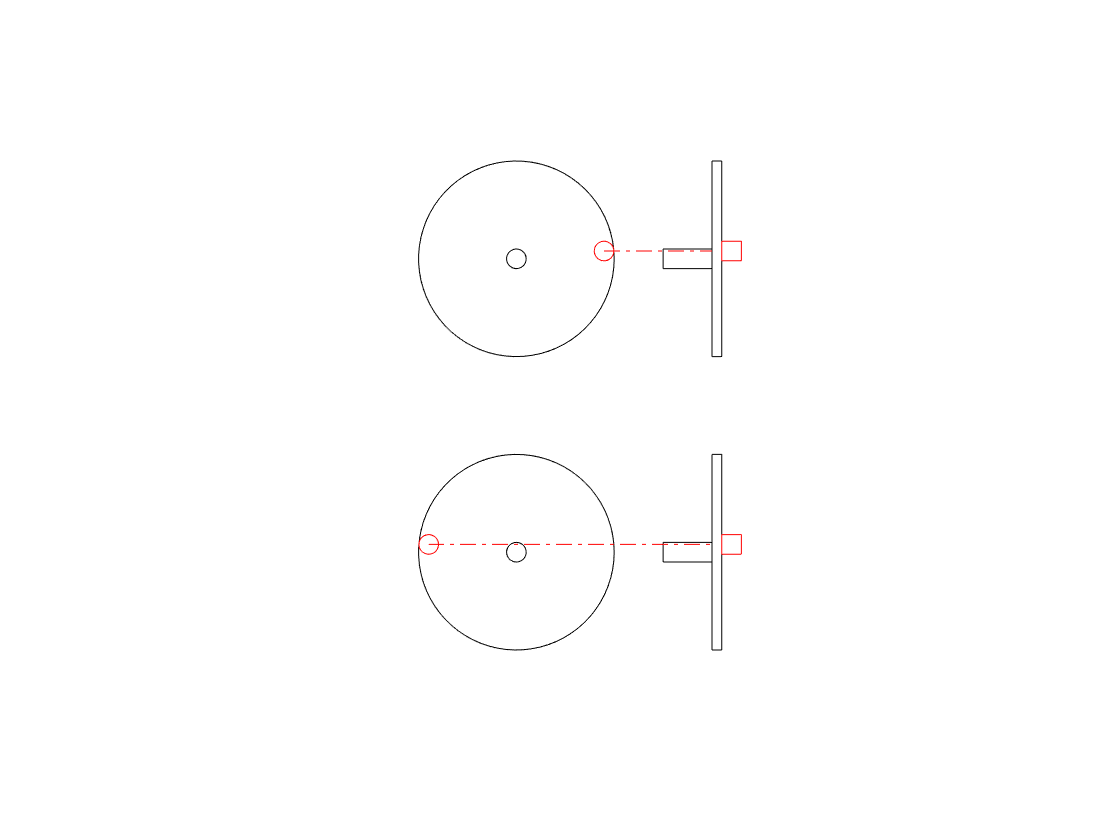
The side-view of the wheel in that animation tells us two of the three things we know from the front-view. We can tell the size of the wheel and the frequency of its rotation. However, we don’t know whether the wheel is turning clockwise or anti-clockwise. For example, if you look at the animation below, the two side views (on the right) are identical – but the two wheels that they represent are rotating in opposite directions.
So, if you’re looking only at the side of the wheel, you cannot know the direction of rotation. However, there is one possibility – if we can look at the wheel from the side and from above at the same time, then we can use those two pieces of information to know everything. This is represented in the animation below.
Although I haven’t shown it here, if the wheel was rotating in the opposite direction, the side view would look the same, but the top view would show the opposite…
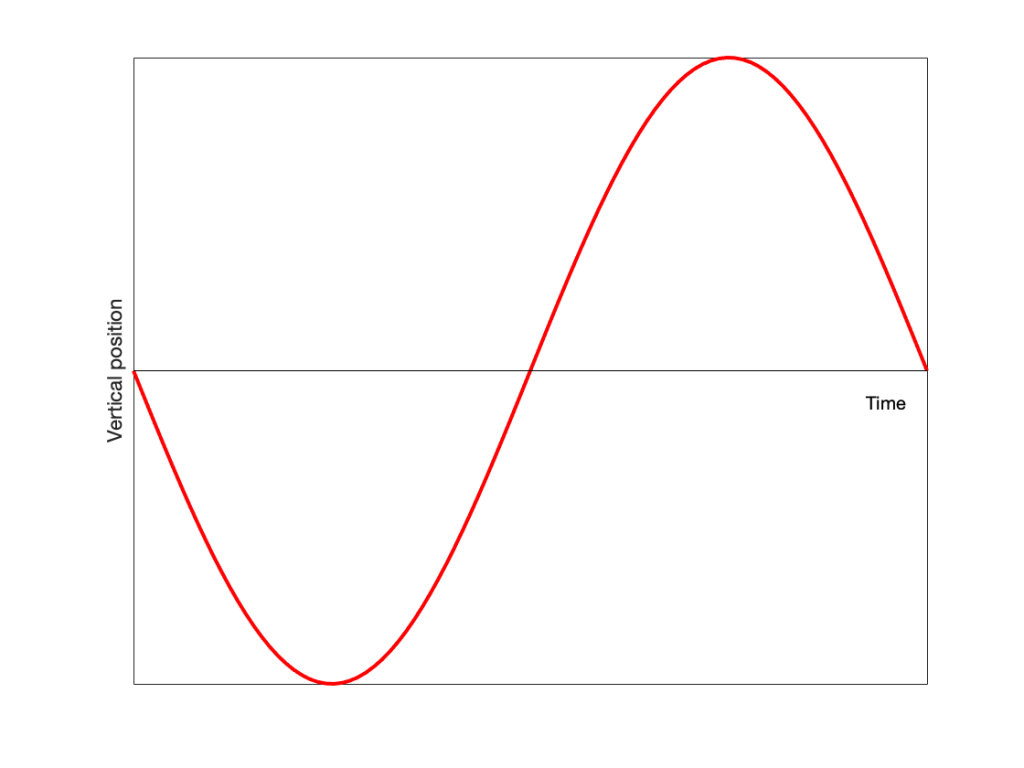
If we were to make a plot of the vertical position of the handle as a function of time, starting at the 3 o’clock position, and rotating clockwise, then the result would look like the plot below. It would start at the mid-point, start moving downwards until the handle had rotated with a “phase shift” of 90 degrees, then start coming back upwards.
If we graph the horizontal position instead, then the plot would look like the one below. The handle starts on the right (indicated as the top of the plot), moves towards the mid-point until it gets all the way to the left (the bottom of this plot) when then wheel has a phase shift (a rotation) of 180 degrees.

If we were to put these two plots together to make a three dimensional plot, showing the side view (the vertical position) and the top view (the horizontal position), and the time (or the angular rotation of the wheel), then we wind up with the plot shown below.
Time to name names… The plot shown in Figure 6 is a “sine wave”, plotted upside down. (The word sine coming from the same root as words like “sinuous” and “sinus” (as in “could you hand me a tissue, please… my sinuses are all blocked up…”) – from the Latin word “sinus” meaning “a bay” – as in “sittin’ by the dock of the bay, watchin’ the tide roll in…”.) Note that, if the wheel were turning anti-clockwise, then it would not be upside down.
Phase
If you look at the plot in Figure 7, you may notice that it looks the same as a sine wave would look, if it started 90 degrees of rotation later. This is because, when you’re looking at the wheel from the top, instead of the side, then you have rotated your viewing position by 90 degrees. This is called a “cosine wave” (because it’s the complement of the sine wave).
Notice how, whenever the sine wave is at a maximum or a minimum, the cosine wave is at 0 – in the middle of its movement. The opposite is also true – whenever the cosine is at a maximum or a minimum, the sine wave is at 0.
Remember that if we only knew the cosine, we still wouldn’t know the direction of rotation of the wheel – we need to know the simultaneous values of the sine and the cosine to know whether the wheel is going clockwise or counterclockwise.
The important thing to know so far is that a sine wave (or a cosine wave) is just a two-dimensional view of a three-dimensional thing. The wheel is rotating with a frequency of some angle per second (one full revolution per second = 360º/sec. 10 revolutions per second = 3600º/sec) and this causes a point on its circumference (the handle in the graphics above) to move back and forth (along the x-axis, which we see in the “top” view) and up and down (along the y-axis, which we see in the side view).
So what?
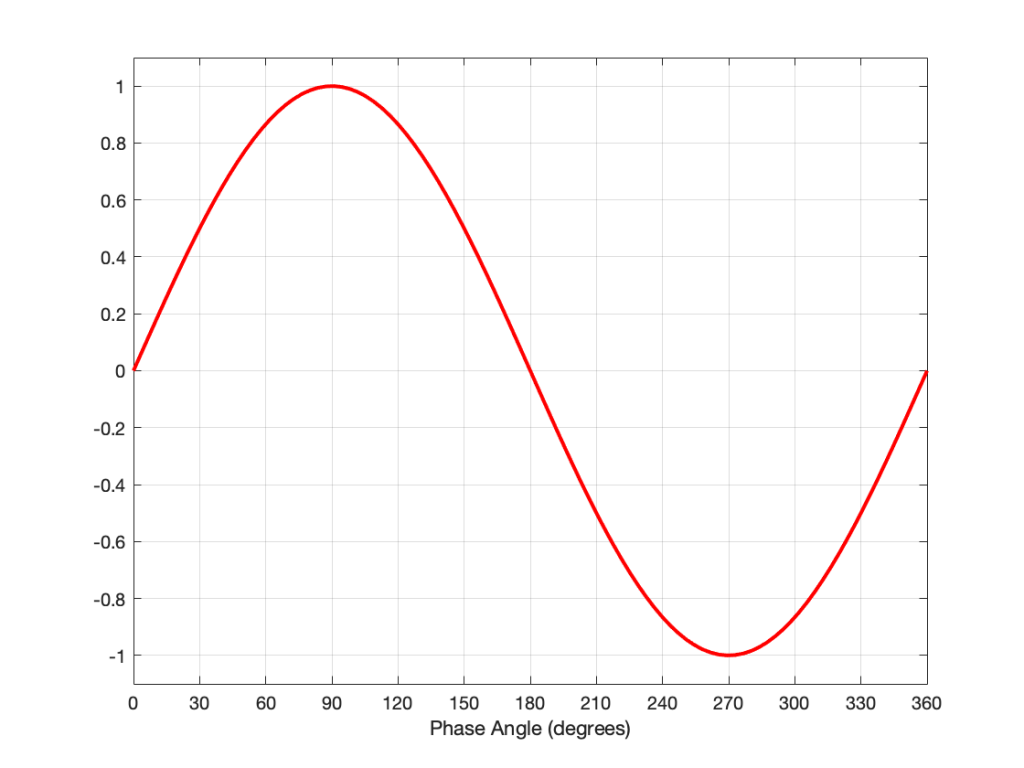
Let’s say that I asked you to make a sine wave generator – and I would like the wave to start at some arbitrary phase. For example, I might ask you to give me a sine wave that starts at 0º. That would look like this:
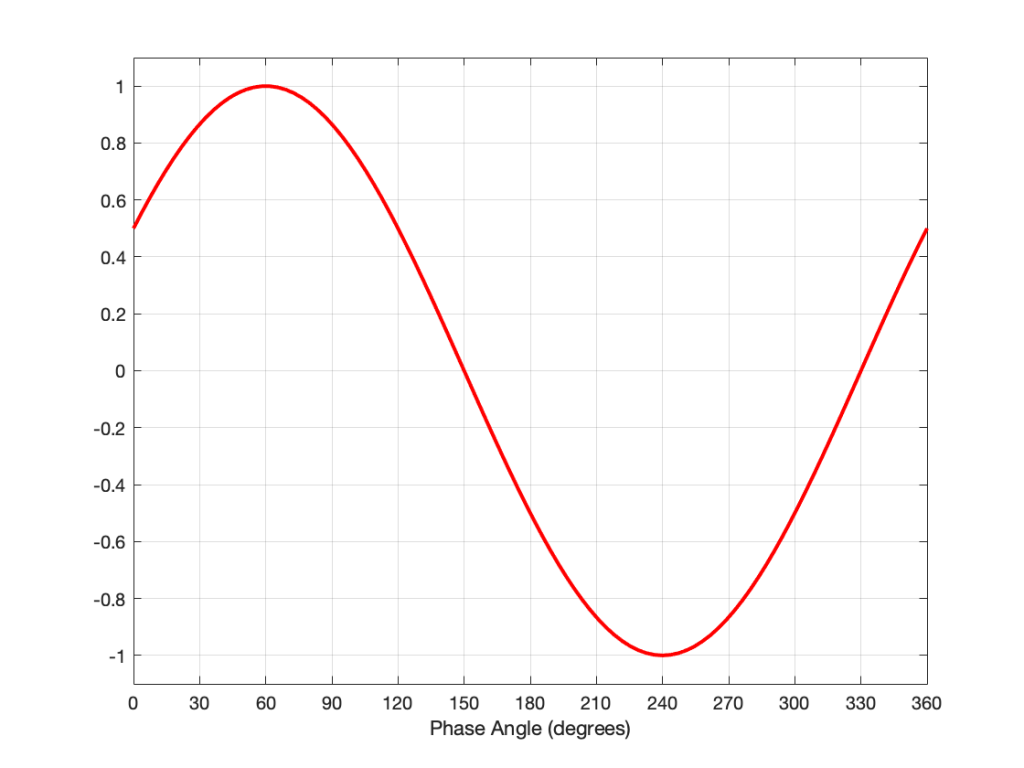
But, since I’m whimsical, I might say “actually, can you start the sine wave at 45º instead please?” which would look like this:
One way for you do do this is to make a sine wave generator with a very carefully timed gain control after it. So, you start the sine wave generator with its output turned completely down (a gain of 0), and you wait the amount of time it takes for 45º of rotation (of the wheel) to elapse – and then you set the output gain suddenly to 1.
However, there’s an easier way to do it – at least one that doesn’t require a fancy timer…
If you add the values of two sinusoidal waves of the same frequency, the result will be a sinusoidal waveform with the same frequency. (There is one exception to this statement, which is when the two sinusoids are 180º apart and identical in level – then if you add them, the result is nothing – but we’ll forget about that exception for now…)
This also means that if we add a sine and a cosine of the same frequency together (remember that a cosine wave is just a sine wave that starts 90º later) then the result will be a sinusoidal waveform of the same frequency. However, the amplitude and the phase of that resulting waveform will be dependent on the amplitudes of the sine and the cosine that you started with…
Let’s look at a couple of examples of this.
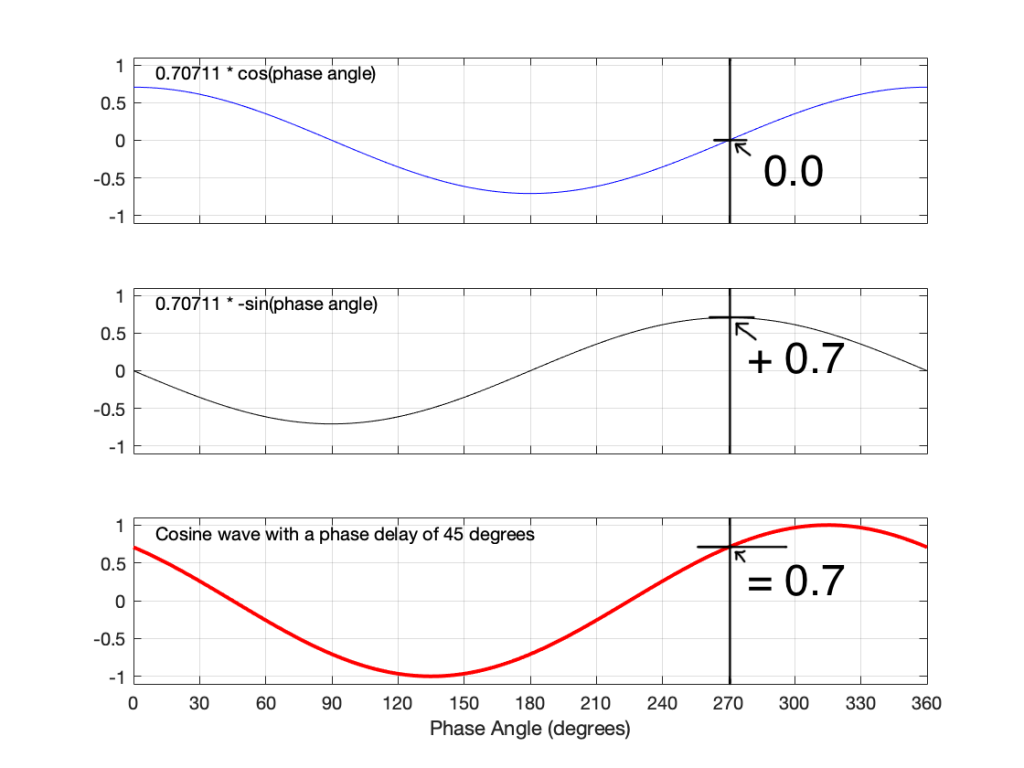
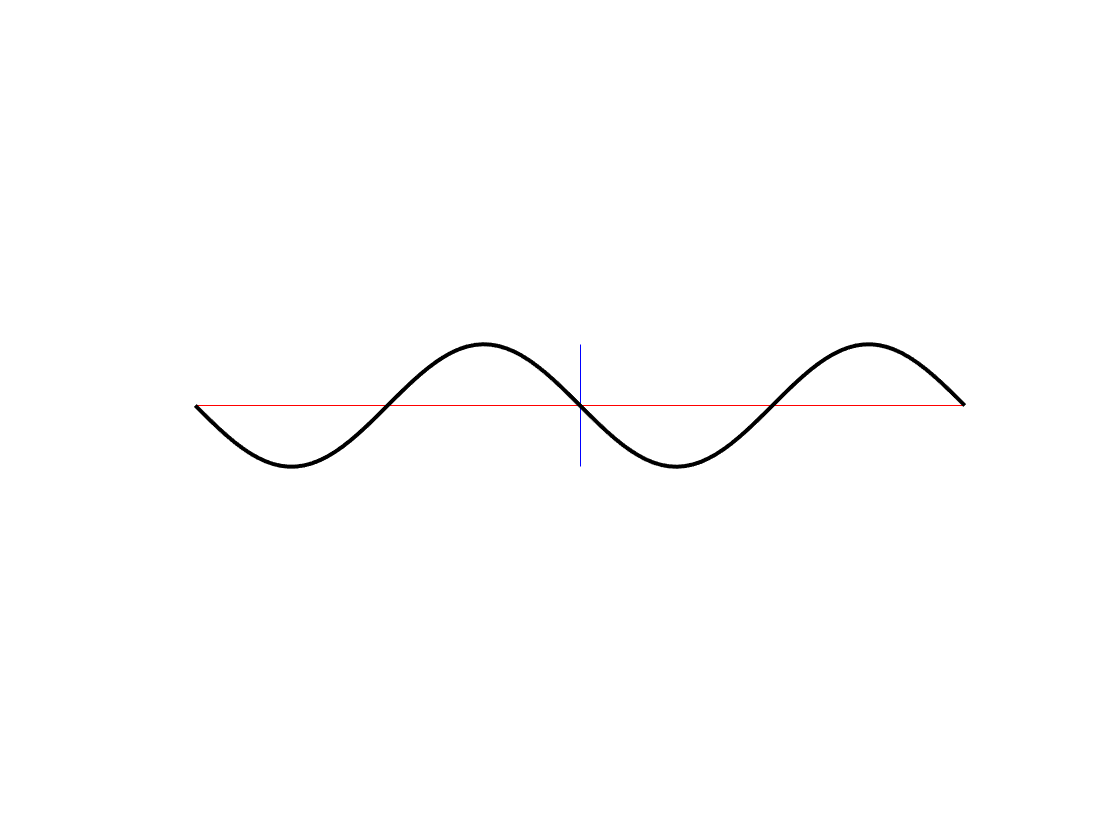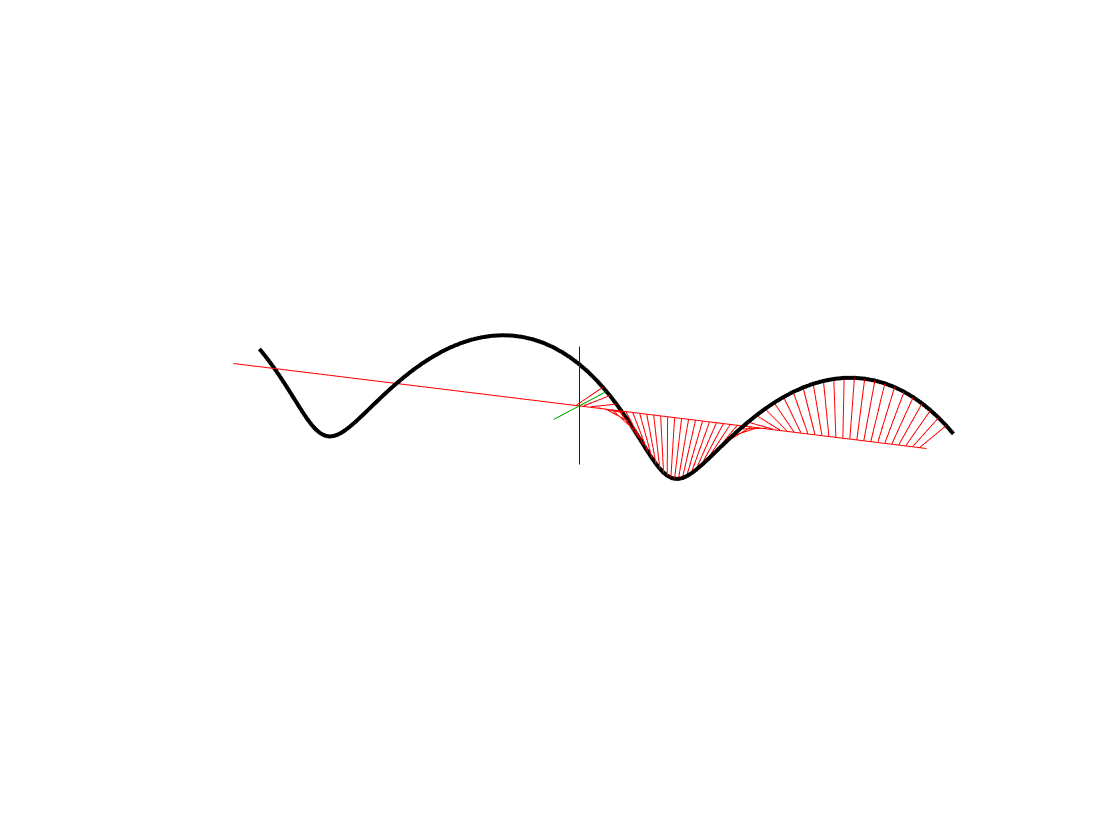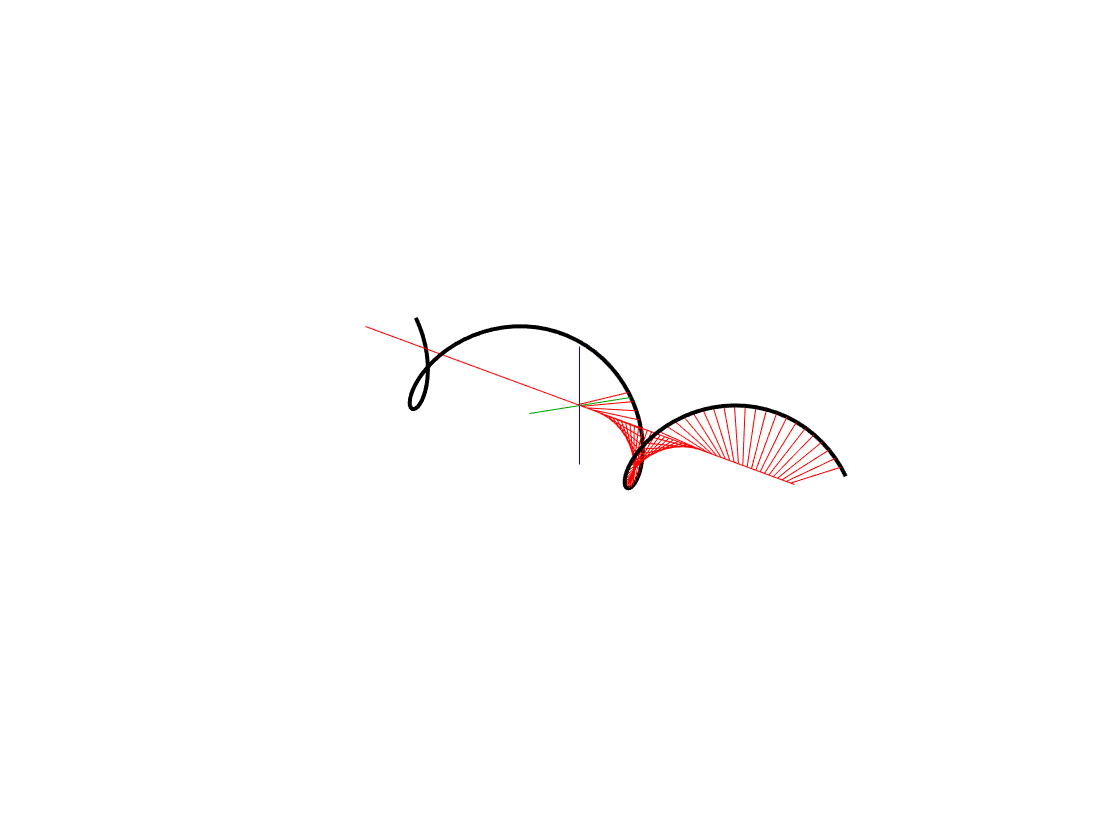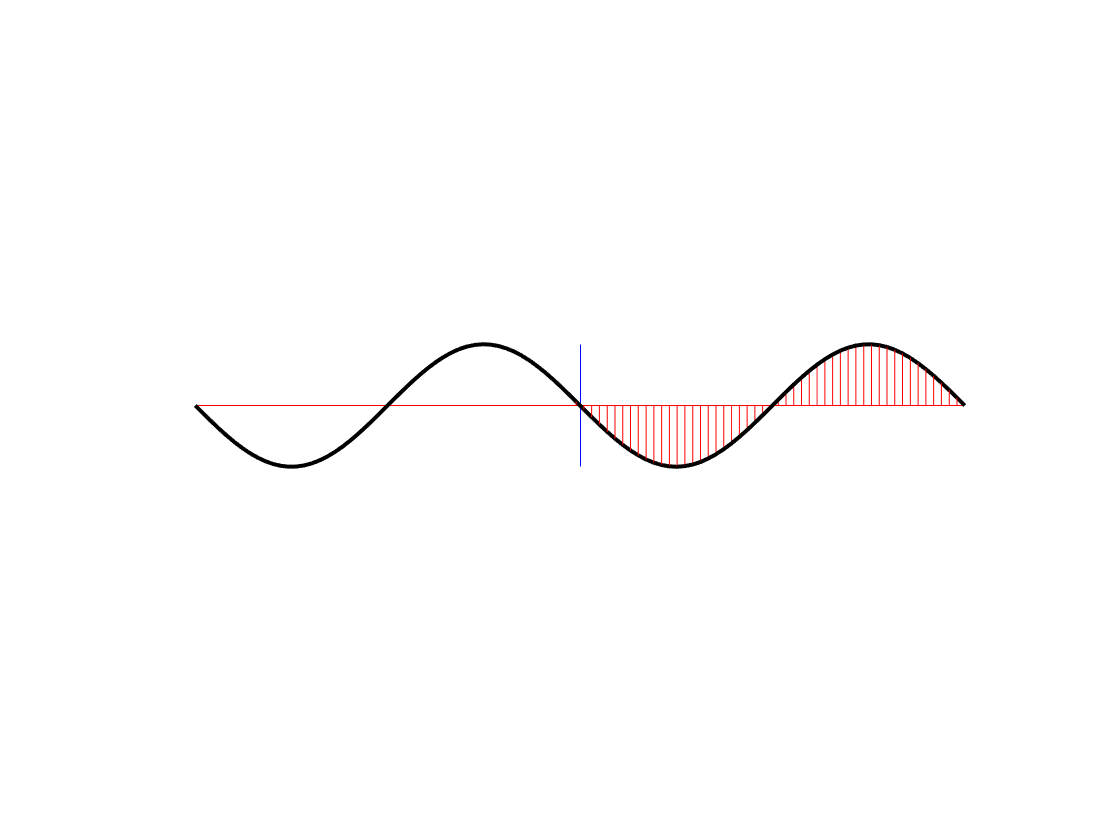
Figure 11, above shows that if you take a cosine wave with a maximum amplitude of 0.7 (in blue) and a sine wave of the same frequency and amplitude, starting at a phase of 180º (or -1 * the sine wave starting at 0º), and you add them together (just add their “y” values, for each point on the x axis – I’ve shown this for an X value of 270º in the figure), then the result is a cosine wave with an amplitude of 1 and a phase delay of 45º (or a sine wave with a phase delay of 135º (45+90 = 135) – it’s the same thing…)
Here’s another example:
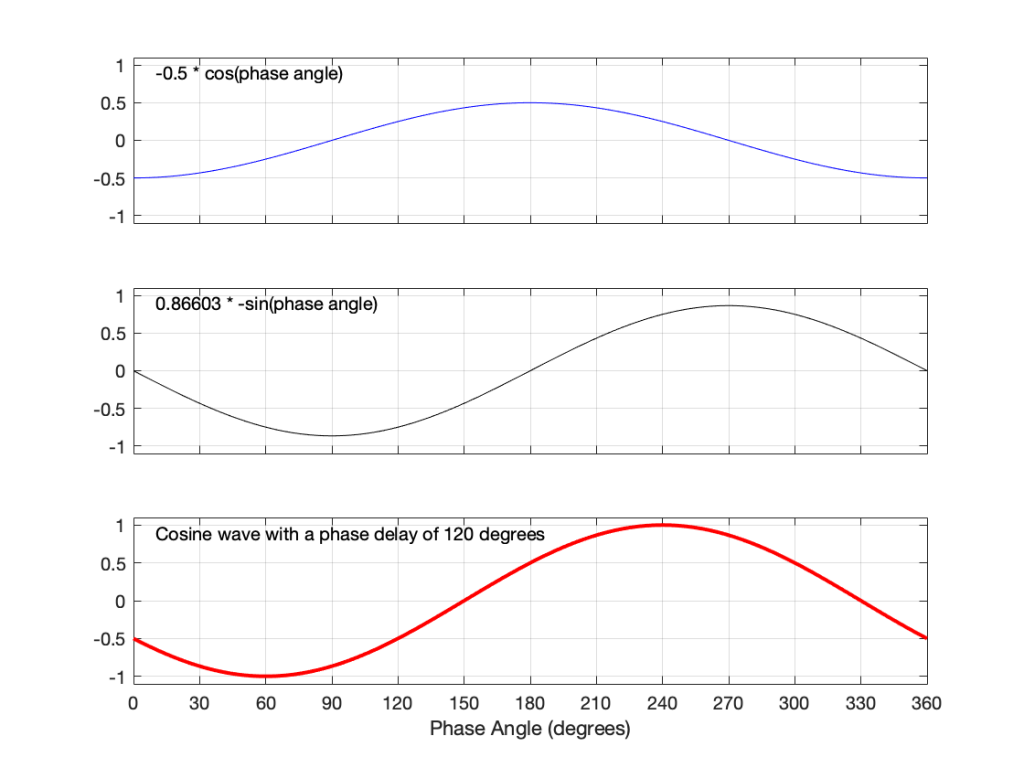
In Figure 12 we see that if we add a a cosine wave * -0.5 and add it to a sine wave * -0.866, then the result is a cosine wave with an amplitude of 1, starting at 120º.
I can keep doing this for different gains applied to the cosine and sine wave, but at this point, I’ll stop giving examples and just say that you’ll have to trust me when I say:
If I want to make a sinusoidal waveform that starts at any phase, I just need to add a cosine and a sine wave with carefully-chosen gains…
Pythagoreas gets involved…
You may be wondering how I found the weird gains in Figures 11 and 12, above. In order to understand that, we need to grab a frame from the animation in Figure 5. If we do that, then you can see that there’s a “hidden” right triangle formed by the radius of the wheel, and the vertical and the horizontal displacement of the handle.
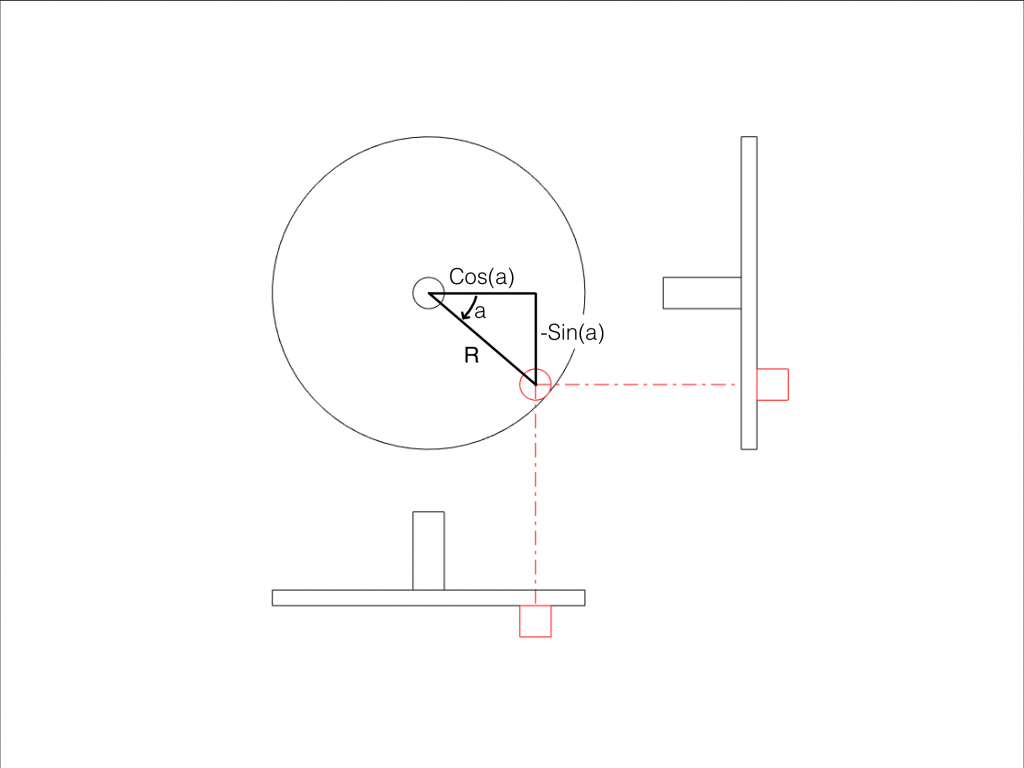
Pythagoras taught us that the square of the hypotenuse of a right triangle is equal to the sum of the squares of the two other sides. Or, expressed as an equation:
a2 + b2 = c2
where “c” is the length of the hypotenuse, and “a” and “b” are the lengths of the other two sides.
This means that, looking at Figure 13:
cos2(a) + sin2(a) = R2
I’ve set “R” (the radius of the wheel ) to equal 1. This is the same as the amplitude of the sum of the cosine and the sine in Figures 11 and 12… and since 1*1 = 1, then I can re-write the equation like this:
sine_gain = sqrt ( 1 – cosine_gain2)
So, for example, in Figure 12, I said that the gain on the cosine is -0.5, and then I calculated sqrt(1 – -0.52) = 0.86603 which is the gain that I applied to the upside-down sine wave.
Three ways to say the same thing…
I can say “a sine wave with an amplitude of 1 and a phase delay of 135º” and you should now know what I mean.
I could also express this mathematically like this:

which means the value of y at a given value of α is equal to A multiplied by the sine of the sum of the values α and ϕ. In other words, the amplitude y at angle α equals the sine of the angle α added to a constant value ϕ and the peak value will be A. In the above example, y(α) would be equal to 1*sin(α +135∘) where α can be any value depending on the time (because it’s the angle of rotation of the wheel).
But, now we know that there is another way to express this. If we scale the sine and cosine components correctly and add them together, the result will be a sinusoidal wave at any phase and amplitude we want. Take a look at the equation below:

where A is the amplitude
ϕ is the phase angle
α is any angle of rotation of the wheel
a = Acos(ϕ)
b = Asin(ϕ)
What does this mean? Well, all it means is that we can now specify values for a and b and, using this equation, wind up with a sinusoidal waveform of any amplitude and phase that we want. Essentially, we just have an alternate way of describing the waveform.
In Part 2, we’ll talk about a fourth way of saying the same thing…
A little good news
8-Track is the new Vinyl
The opposite of wireless
Why I always feel uncomfortable…

Listening Tips
So, you want to evaluate a pair of loudspeakers, or a new turntable, or you’re trying to decide whether to subscribe to a music streaming service, or its more expensive “hi-fi” version – or just to stick with your CD collection… How should you listen to such a thing and form an opinion about its quality or performance – or your preference?
One good way to do this is to compartmentalise what you hear into different categories or attributes. This is similar to breaking down taste and sensation into different categories – sweetness, bitterness, temperature, etc… This allows you to focus or concentrate on one thing at a time so that you’re not overwhelmed by everything all at once… Of course, the problem with this is that you become analytical, and you stop listening to the music, which is why you’re there in the first place…
Normally, when I listen to a recording over a playback system, I break things down into 5 basic categories:
- timbre (or spectral balance)
- spatial aspects
- temporal behaviour
- dynamics
- noise and distortion
Each of these can be further broken down into sub-categories – and there’s (of course) some interaction and overlap – however it’s a good start…
Timbre
One of the first things people notice when they listen to something like a recording played over a system (for example, a pair of headphones or some loudspeakers in a room) is the overall timbre – the balance between the different frequency bands.
Looking at this from the widest point of view, we first consider the frequency range of what we’re hearing. How low and how high in frequency does the signal extend?
On the next scale, we listen for the relative balance between the bass (low frequencies), the midrange, and the treble (high frequencies). Assuming that all three bands are present in the original signal, do all three get “equal representation” in the playback system? And, possibly more importantly: should they? For example, if you are evaluating a television, one of the most important things to consider is speech intelligibility, which means that the midrange frequency bands are probably a little more important than the extreme low- and high-frequency bands. If you are evaluating a subwoofer, then its behaviour at very high frequencies is irrelevant…
Zooming into more details, we can ask whether there are any individual notes sticking out. This often happens in smaller rooms (or cars), often resulting in a feeling of “uneven bass” – some notes in the bass region are louder than others. If there are narrow peaks in the upper midrange, then you can get the impression of “harshness” or “sharpness” in the system. (although words like “harsh” and “sharp” might be symptoms of distortion, which has an effect on timbre…)
Spatial
The next things to focus on are the spatial aspects of the recording in the playback system. First we’ll listen for imaging – the placement of instruments and voices across the sound stage, thinking left – to – right. This imaging has two parameters to listen for: accuracy (are things where they should be?) and precision (are they easy to point to?). Note that, depending on the recording technique used by the recording engineer, it’s possible that images are neither accurate nor precise, so you can’t expect your loudspeakers to make things more accurate or more precise.
Secondly, we listen for distance and therefore depth. Distance is the perceived distance from you to the instrument. Is the voice near or far? Depth is the distance between the closest instrument and the farthest instrument (e.g. the lead vocal and the synth pad and reverberation in the background – or the principal violin at the front and the xylophone at the back).
Next we list for the sense of space in the recording – the spaciousness and envelopment. The room around the instruments can range from non-existent (e.g. Suzanne Vega singing “Tom’s Diner”) to huge (a trombone choir in a water reservoir) and anything in between.
It is not uncommon for a recording engineer to separate instruments in different rooms and/or to use different reverb algorithms on them. In this case, it will sound like each instrument or voice has its own amount of spaciousness that is different from the others.
Also note that, just because an instrument has reverb won’t necessarily make it enveloping or spacious. Listen to “Chain of Fools” by Aretha Franklin on a pair of headphones. You’ll hear the snare drum in your right ear – but the reverb from the same snare is in the centre of your head. (It was a reverb unit with a single channel output, and the mixing console could be used to only place images in one of three locations, Left, Centre, or Right.)
Temporal
The temporal aspects of the sound are those that are associated with time. Does the attack of the harpsichord or the pluck of a guitar string sound like it starts instantaneously, or does it sound “rounded” or as if the plectrum or pick is soft and padded?
The attack is not the only aspect of the temporal behaviour of a system or recording. The release – the stop of a sound – is just as (or maybe even more) important. Listen to a short, dry kick drum (say, the kick in “I Bid You Goodnight” by Aaron Neville that starts at around 0:20). Does it just “thump” or does it “sing” afterwards at a single note – more like a “boommmmmm”… sound?
It’s important to say here that, if the release of a sound is not fast, it might be a result of resonance in your listening room – better known as “room modes”. These will cause a couple of frequencies to ring longer than others, which can, in turn, make things sound “boomy” or “muddy”. (In fact, when someone tells me that things sound boomy or muddy, my first suspect is temporal problems – not timbral ones. Note as well that those room modes might have been in the original recording space… And there’s not much you’re going to be able o do about that without a parametric equaliser and a lot of experience…
Dynamics
Dynamics are partly related to temporal behaviour (a recording played on loudspeakers can’t sound “punchy” if the attack and release aren’t quick enough) but also a question of capability. Does the recording have quiet and loud moments (not only in the long term, but also in the very short term)? And, can the playback system accurately produce those differences? (A small loudspeaker simply cannot play low frequencies loudly – so if you’re listening to a track at a relatively high volume, and then the kick drum comes in, the change in level at the output will be less than the change in level on the recording.)
Noise and Distortion
So far, the 4 attributes I’ve talked about above are descriptions of how the stuff -you-want “translates” through a system. Noise and Distortion is the heading on the stuff-you-don’t-want – extra sounds that don’t belong (I’m not talking about the result of a distortion pedal on an AC/DC track – without that, it would be a Tuck and Patti track…)
However, Noise and Distortion are very different things. Noise is what is known as “program independent” – meaning that it does not vary as a result of the audio signal itself. Tape hiss on a cassette is a good example of this… It might be that the audio signal (say, the song) is loud enough to “cover up” or “mask” the noise – but that’s your perception changing – not the noise itself.
Distortion is different – it’s garbage that results from the audio signal being screwed up – so it’s “program dependent”. If there was no signal, there would be nothing to distort. Note, however, that distortion takes many forms. One example is clipping – the loud signals are “chopped off”, resulting in extra high frequencies on the attacks of notes. Another example is quantisation error on old digital recordings, where the lower the level, the more distortion you get (this makes reverberation tails sound “scratchy” or “granular”).
A completely different, and possibly more annoying, kind go distortion is that which is created by “lossy” psychoacoustic codec’s such as MP3. However, if you’re not trained to hear those types of artefacts, they may be difficult to notice, particularly with some kinds of audio signals. In addition, saying something as broad as “MP3” means very little. You would need to know the bitrate, and a bunch of parameters in the MP3 encoder, in addition to knowing something about the signal that’s being encoded, to be able to have any kind of reasonable prediction about its impact on the audibility of the “distortion” that it creates.
Wrapping up…
It’s important here to emphasise that, although the loudspeakers, their placement, the listening room, and the listening position all have a significant impact on how things sound – the details of the attributes – the recording is (hopefully) the main determining factor… If you’re listening to a recording of solo violin, then you will not notice if your subwoofer is missing… Loudspeakers should not make recordings sound spacious if the recordings are originally monophonic. This would be like a television applying colours to a black and white movie…
(don’t) Listen to this…
A two-part excellent podcast on the effects of sound on our health.

