The June, 1968 issue of Wireless World magazine includes an article by R.T. Lovelock called “Loudness Control for a Stereo System”. This article partly addresses the issue of resistance behaviour one or more channels of a variable resistor. However, it also includes the following statement:
It is well known that the sensitivity of the ear does not vary in a linear manner over the whole of the frequency range. The difference in levels between the threshold of audibility and that of pain is much less at very low and very high frequencies than it is in the middle of the audio spectrum. If the frequency response is adjusted to sound correct when the reproduction level is high, it will sound thin and attenuated when the level is turned down to a soft effect. Since some people desire a high level, while others cannot endure it, if the response is maintained constant while the level is altered, the reproduction will be correct at only one of the many preferred levels. If quality is to be maintained at all levels it will be necessary to readjust the tone controls for each setting of the gain control
The article includes a circuit diagram that can be used to introduce a low- and high-frequency boost at lower settings of the volume control, with the following example responses:
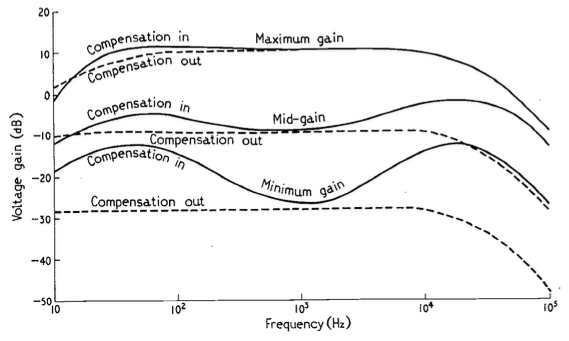
These days, almost all audio devices include some version of this kind of variable magnitude response, dependent on volume. However, in 1968, this was a rather new idea that generated some debate.
In the following month’s issue The Letters to the Editor include a rather angry letter from John Crabbe (Editor of Hi-Fi News) where he says
Mr. Lovelock’s article in your June issue raises an old bogey which I naively thought had been buried by most British engineers many years ago. I refer, not to the author’s excellent and useful thesis on achieving an accurate gain control law, but to the notion that our hearing system’s non-linear loudness / frequency behaviour justifies an interference with response when reproducing music at various levels.
Of course, we all know about Fletcher-Munson and Robinson-Dadson, etc, and it is true that l.f. acuity declines with falling sound pressure level; though the h.f. end is different, and latest research does not support a general rise in output of the sort given by Mr. Lovelock’s circuit. However, the point is that applying the inverse of these curves to sound reproduction is completely fallacious, because the hearing mechanism works the way it does in real life, with music loud or quiet, and no one objects. If `live’ music is heard quietly from a distant seat in the concert hall the bass is subjectively less full than if heard loudly from the front row of the stalls. All a `loudness control’ does is to offer the possibility of a distant loudness coupled with a close tonal balance; no doubt an interesting experiment in psycho-acoustics, but nothing to do with realistic reproduction.
In my experience the reaction of most serious music listeners to the unnaturally thick-textured sound (for its loudness) offered at low levels by an amplifier fitted with one of these abominations is to switch it out of circuit. No doubt we must manufacture things to cater for the American market, but for goodness sake don’t let readers of Wireless World think that the Editor endorses the total fallacy on which they are based.
with Lovelock replying:
Mr. Crabbe raises a point of perennial controversy in the matter of variation of amplifier response with volume. It was because I was aware of the difference in opinion on this matter that a switch was fitted which allowed a variation of volume without adjustment of frequency characteristic. By a touch of his finger the user may select that condition which he finds most pleasing, and I still think that the question should be settled by subjective pleasure rather than by pure theory.
and
Mr. Crabbe himself admits that when no compensation is coupled to the control, it is in effect a ‘distance’ control. If the listener wishes to transpose himself from the expensive orchestra stalls to the much cheaper gallery, he is, of course, at liberty to do so. The difference in price should indicate which is the preferred choice however.
In the August edition, Crabbe replies, and an R.E. Pickvance joins the debate with a wise observation:
In his article on loudness controls in your June issue Mr. Lovelock mentions the problem of matching the loudness compensation to the actual sound levels generated. Unfortunately the situation is more complex than he suggests. Take, for example, a sound reproduction system with a record player as the signal source: if the compensation is correct for one record, another record with a different value of modulation for the same sound level in the studio will require a different setting of the loudness control in order to recreate that sound level in the listening room. For this reason the tonal balance will vary from one disc to another. Changing the loudspeakers in the system for others with different efficiencies will have the same effect.
In addition, B.S. Methven also joins in to debate the circuit design.
The debate finally peters out in the September issue.
Apart from the fun that I have reading this debate, there are two things that stick out for me that are worth highlighting:
- Notice that there is a general agreement that a volume control is, in essence, a distance simulator. This is an old, and very common “philosophy” that we forget these days.
- Pickvance’s point is possibly more relevant today than ever. Despite the amount of data that we have with respect to equal loudness contours (aka “Fletcher and Munson curves”) there is still no universal standard in the music industry for mastering levels. Now that more and more tracks are being released in a Dolby Atmos-encoded format, there are some rules to follow. However, these are very different from 2-channel materials, which have no rules at all. Consequently, although we know how to compensate for changes in response in our hearing as a function of level, we don’t know what the reference level should be for any given recording.