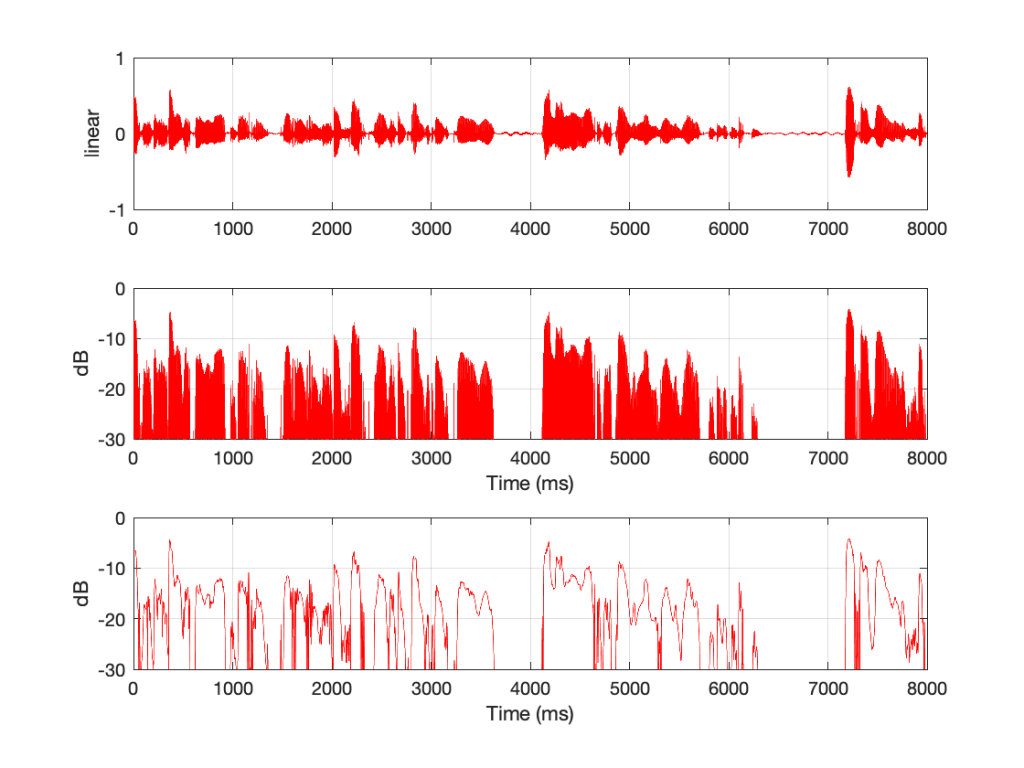
One of my jobs at Bang & Olufsen is to do the final measurements on each bespoke Beogram 4000c turntable before it’s sent to the customer. Those measurements include checking the end-to-end magnitude response, playing from a vinyl record with a sine sweep on it (one per channel), recording that from the turntable’s line-level output, and analysing it to make sure that it’s as expected. Part of that analysis is to very that the magnitude responses of the left and right channel outputs are the same (or, same enough… it’s analogue, a world where nothing is perfect…)
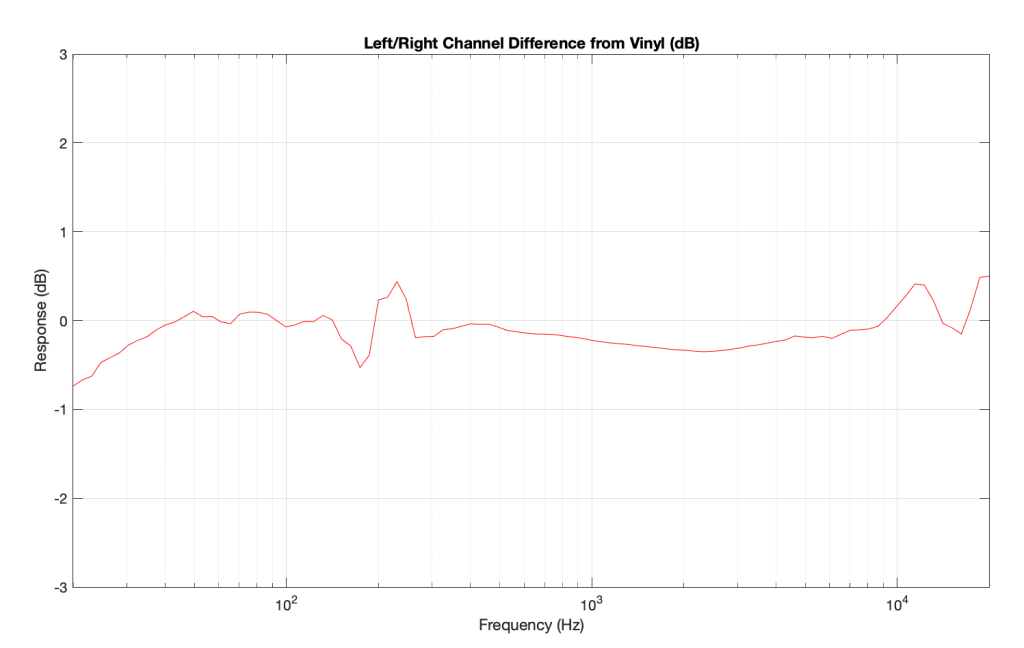
Today, I was surprised to see this result on a turntable that was being inspected part-way through its restoration process :
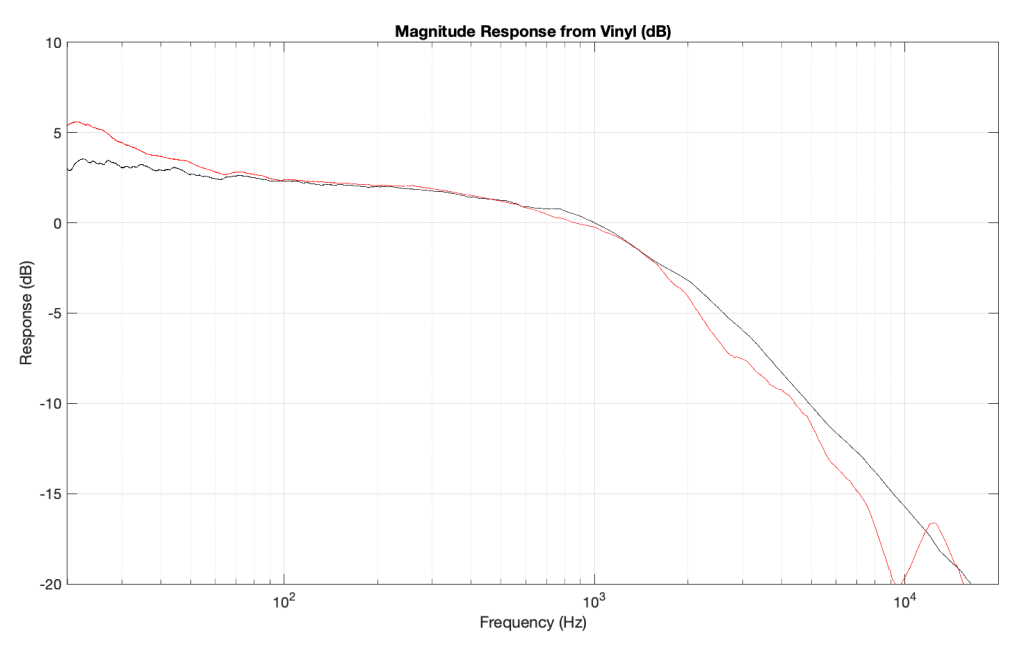
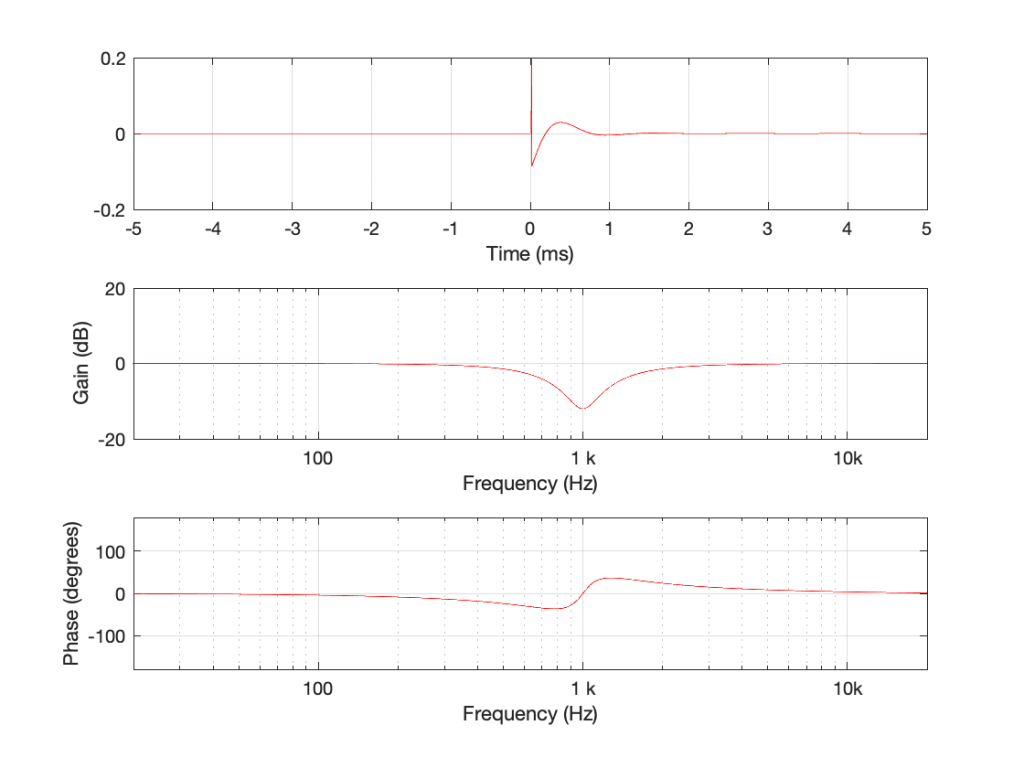
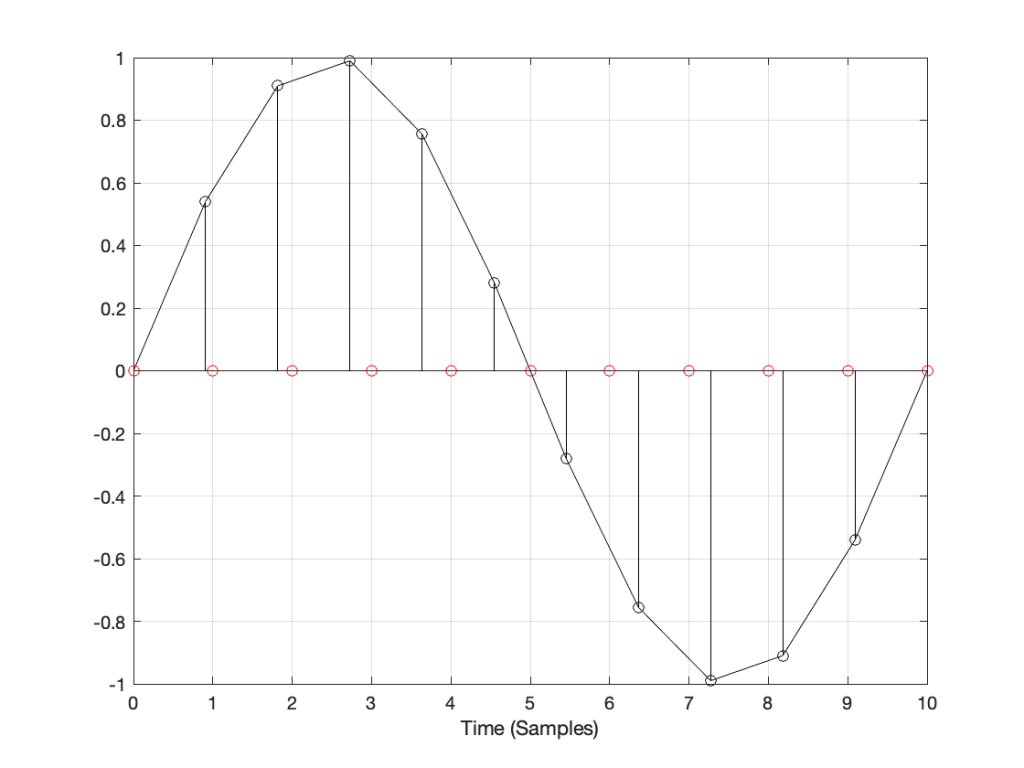
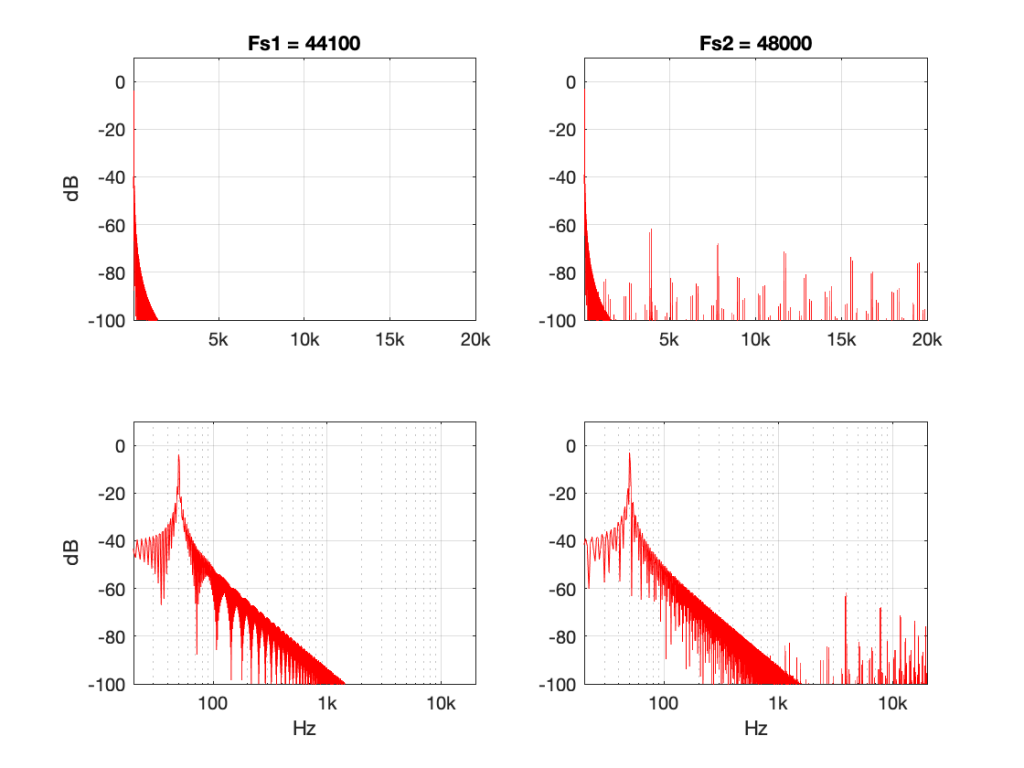
Taken at face value, this should have resulted in a rejection – or at least some very serious questions. This is a terrible result, with unacceptable differences in output level between the two channels. When I looked at the raw measurements, I could easily see that the left channel was behaving – it was the right channel that was all over the place.
The black curve looks very much like what I would expect to see. This is the result of playing a track that is a sine sweep from 20 Hz to 20 kHz, where the signal below 1 kHz follows the RIAA curve, whereas the signal above 1 kHz does not. This is why, after it’s been filtered using a RIAA preamp, the low frequency portion has a flat response, but the upper frequency band rolls off (following the RIAA curve).
Notice that the right channel (the red curve) is a mess…
A quick inspection revealed what might have been the problem: a small ball of fluff collected around the stylus. (This was a pickup that was being used to verify that the turntable was behaving through the restoration – not the one intended for the final customer – and so had been used multiple times on multiple turntables.)
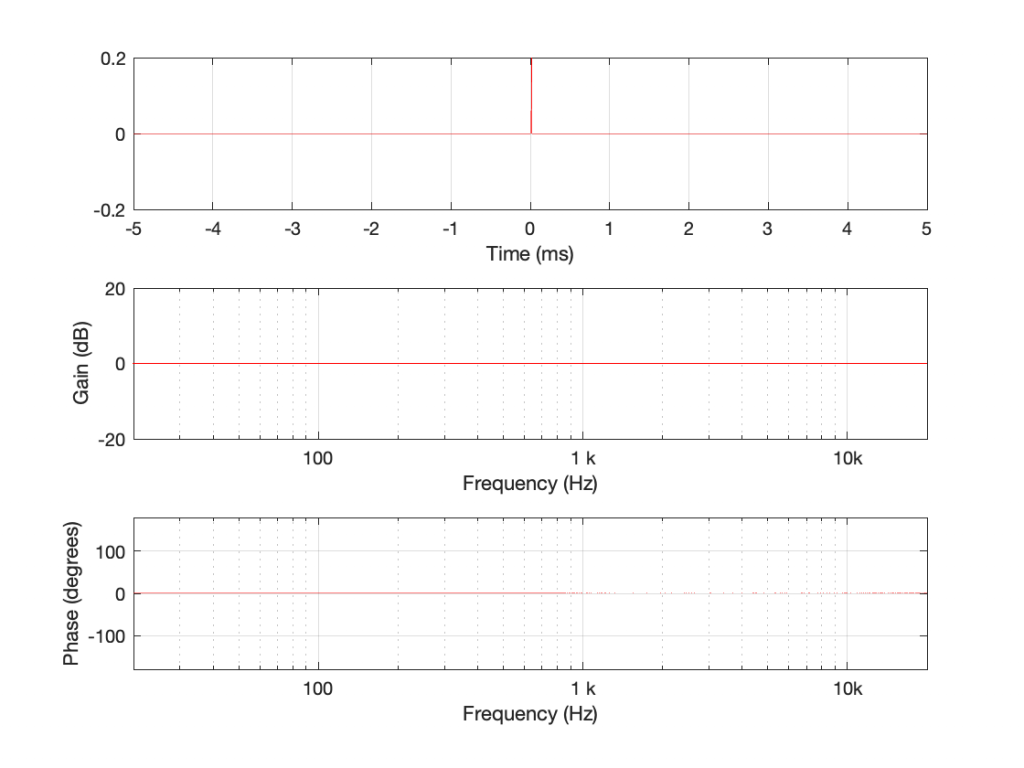
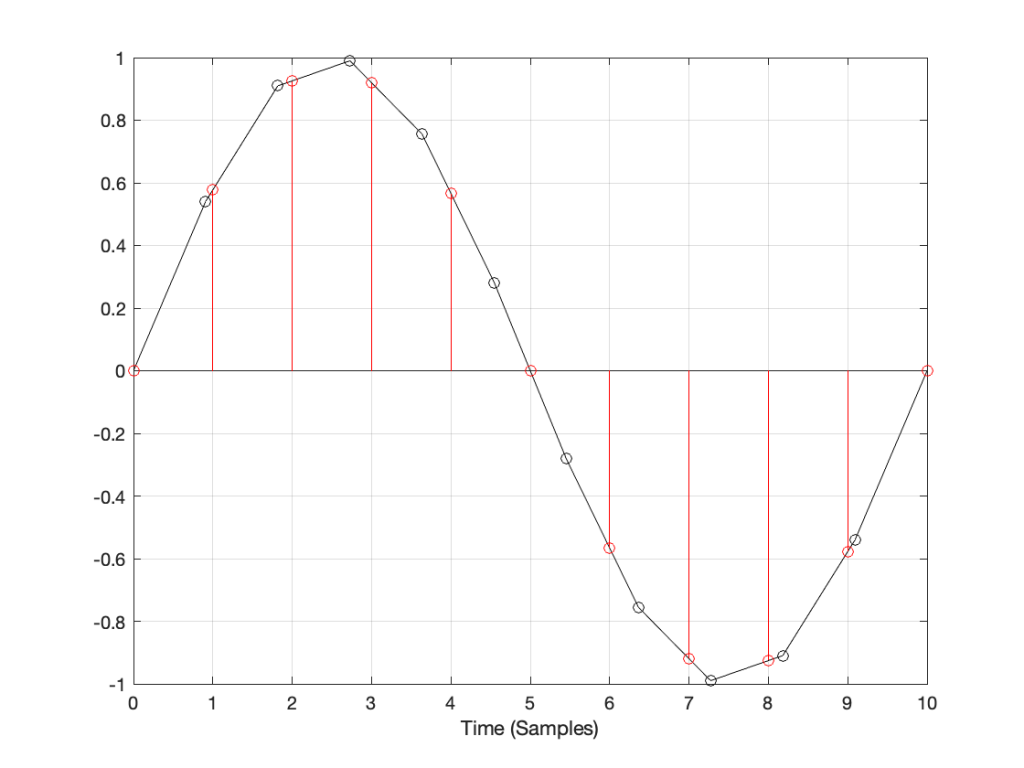
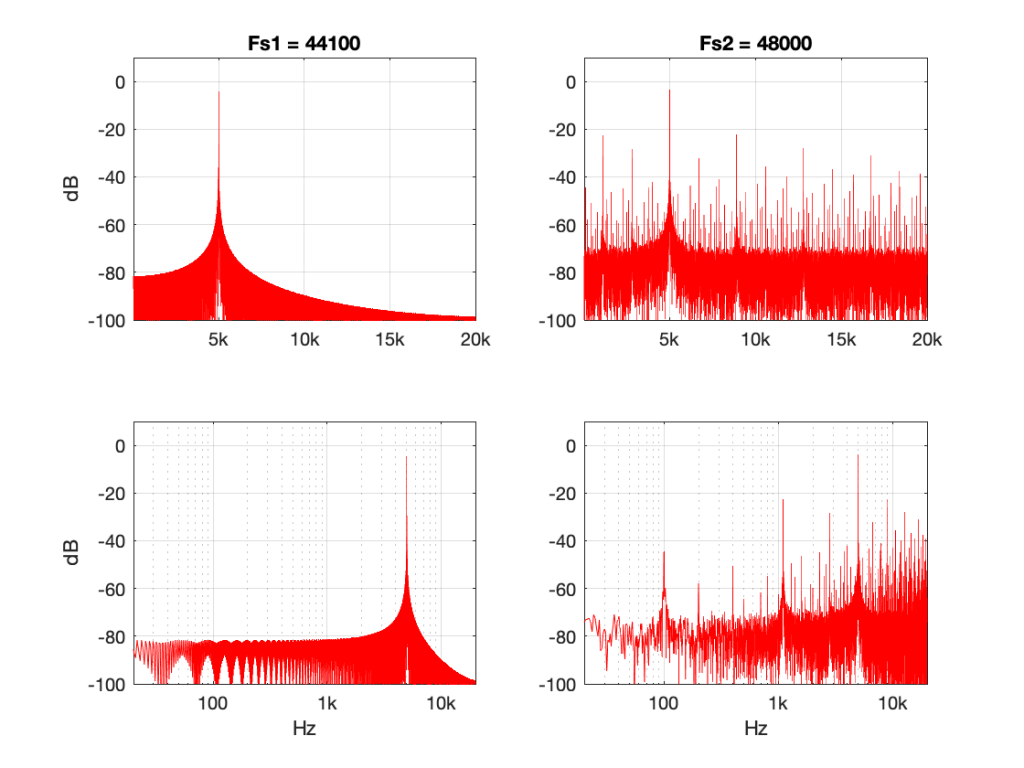
So, we used a stylus brush to clean off the fluff and ran the measurement again. The result immediately afterwards looked like this:
which is more like it! A left-right channel difference of something like ± 0.5 dB is perfectly acceptable.
The moral of the story: keep your pickup clean. But do it carefully! That cantilever is not difficult to snap.
There’s one last thing that I alluded to in a previous part of this series that now needs discussing before I wrap up the topic. Up to now, we’ve looked at how a filter behaves, both in time and magnitude vs. frequency. What we haven’t really dealt with is the question “why are you using a filter in the first place?”
Originally, equalisers were called that because they were used to equalise the high frequency levels that were lost on long-distance telephone transmissions. The kilometres of wire acted as a low-pass filter, and so a circuit had to be used to make the levels of the frequency bands equal again.
Nowadays we use filters and equalisers for all sorts of things – you can use them to add bass or treble because you like it. A loudspeaker developer can use them to correct linear response problems caused by the construction or visual design of the device. They can be used to compensate for the acoustical behaviour of a listening room. Or they can be used to compensate for things like hearing loss. These are just a few examples, but you’ll notice that three of the four of them are used as compensation – just like the original telephone equalisers.
Let’s focus on this application. You have an issue, and you want to fix it with a filter.
IF the problem that you’re trying to fix has a minimum phase characteristic, then a minimum phase filter (implemented either as an analogue circuit or in a DSP) can be used to “fix” the problem not only in the frequency domain – but also in the time domain. IF, however, you use a linear phase filter to fix a minimum phase problem, you might be able to take care of things on a magnitude vs. frequency analysis, but you will NOT fix the problem in the time domain.
This is why you need to know the time-domain behaviour of the problem to choose the correct filter to fix it.
For example, if you’re building a room compensation algorithm, you probably start by doing a measurement of the loudspeaker in a “reference” room / location / environment. This is your target.
You then take the loudspeaker to a different room and measure it again, and you can see the difference between the two.
In order to “undo” this difference with a filter (assuming that this is possible) one strategy is to start by analysing the difference in the two measurements by decomposing it into minimum phase and non-minimum phase components. You can then choose different filters for different tasks. A minimum phase filter can be used to compensate a resonance at a single frequency caused by a room mode. However, the cancellation at a frequency caused by a reflection is not minimum phase, so you can’t just use a filter to boost at that frequency. An octave-smoothed or 1/3-octave smoothed measurement done with pink noise might look like you fixed the problem – but you’ve probably screwed up the time domain.
Another, less intuitive example is when you’re building a loudspeaker, and you want to use a filter to fix a resonance that you can hear. It’s quite possible that the resonance (ringing in the time domain) is actually associated with a dip in the magnitude response (as we saw earlier). This means that, although intuition says “I can hear the resonant frequency sticking out, so I’ll put a dip there with a filter” – in order to correct it properly, you might need to boost it instead. The reason you can hear it is that it’s ringing in the time domain – not because it’s louder. So, a dip makes the problem less audible, but actually worse. In this case, you’re actually just attenuating the symptom, not fixing the problem – like taking an Asprin because you have a broken leg. Your leg is still broken, you just can’t feel it.
So far, we have looked at minimum phase and linear phase examples of one basic kind of filter, but everything I’ve shown you are just examples. There are other filters (I could be showing you shelving filters instead of peaking filters – which would be a through-put plus a low- or high-pass instead of a bandpass) and other implementations (for example, there are other ways to make a linear phase filter).
We won’t go through these other versions because we’re not here to learn how to make filters, we’re here to learn why, when someone asks you “which is better, minimum-phase or linear phase?” or “aren’t you worried about the unnatural effects of pre-ringing?” you can answer “it depends” (which is almost always the correct answer for any question related to audio).
At this point you should know that
a filter that changes the frequency response also changes the time response. This is unavoidable.
some filters will also ‘pre-ring’ ahead of the sound
a filter may or may not have an effect on the phase of the signal
If you’re designing (or choosing) a filter, nothing comes for free. (For example, if you want linear phase, the price is latency. There are other prices attached to other design decisions.)
The question that we have not yet addressed is “so what?”
This is the point in the discussion where things are going to get a little fuzzy… Hang on!
You probably read somewhere that human hearing extends from 20 Hz to 20 kHz, therefore anything outside that range is not audible. This is not true. You might have read a little farther where they added an extra detail saying something about your age: the older you are, the lower that top number gets. That might be true.
You can also read that the quietest sound you can hear has a sound pressure level of 20 µPa, which is equivalent to 0 dB SPL, and that the loudest sound you can “hear” (over the sound of your screams of pain) is about 120 dB SPL or so. You might have also read a little farther where they added an extra detail that points out that this is only at 1 kHz. But this is probably also not true.
There are many reasons why all of those numbers are basically meaningless – but the main one is that they’re numbers based on averages. Imagine if an optometrist only carried one strength of glasses, which happened to be the average of the prescriptions required by all of his or her patients. We’d all be tripping over out own feet, and getting blinding headaches caused by wearing the wrong glasses.
Actually, a similar point was once proven by the American Air Force. They wanted to design the perfect airplane cockpit, so they measured all their pilots, averaged all the numbers, and built a seat for the result. Of course, the result was that the seat fit no one, since there was no single person that matched the average.
There are other examples that prove that averages are useless information. For example, I have more than the average number of legs. Also, since one in every three mammals on the earth is a bat, if I have meeting with two other people, one of us must be Batman…
Of course, the message is that we’re all different. For example. I don’t taste things very well. I don’t understand people who talk about the various elements in the taste of wine. All I know is that it’s drinkable, or it’s good for putting on fish & chips. When I eat food, I tend to put on pepper and chill so that I can at least taste something…
Hearing is the same: so all of the stuff I’m about to say is based on averages, which may or may not apply to you. You might be more or less sensitive than the average. Don’t email me to argue about the numbers I’m using here. You’re different. I know… We all are…
Psychoacoustic Masking
Let’s go to an AC/DC concert together. Halfway through You Shook Me (All Night Long), I’ll whisper a secret code word into your left ear. Then, you whisper it back to me.
This exercise will not work. You won’t hear me, which is strange because the changes in air pressure that I’m making by whispering are exactly the same as when AC/DC is not playing – and normally, you’d be able to hear that. Also, your eardrum is wiggling in exactly the same way as a result of that whispering – it also happens to be wiggling to the AC/DC more. So, why can’t you hear me?
The answer lies in your brain. It decides that I’m not as important as AC/DC, so the signal is thrown out as being irrelevant, and so the sound my my whispering is ‘psychoacoustically masked’ by AC/DC. Notice the ‘psycho-‘ part of that, which is the indication that the acoustic masking is happening in your brain, not as a result of a mechanical or physical issue.
This probably doesn’t come as a surprise – at some point in your life, you’ve probably been somewhere where you’ve asked someone to speak up because you can’t hear them over the noise. You’ve been the victim of the limitations of your own brain.
Temporal Masking
What might come as a surprise is that this effect also works when the loud sound (AC/DC) and the quiet sound (me whispering) don’t happen simultaneously.
For example, let’s say that you are getting your photo taken by someone with a flash camera. You’re looking right at the camera, and the flash goes off. For a short while after that, you can’t see anything but the leftover spot in the middle of your vision. If, right after the flash, someone were to hold up some number of fingers and ask “how many fingers?”, you’d have to guess. (This is only an analogous example; the spot in your eyes is not happening in your brain, but the effect is similar.)
Similarly, if I were to fire a gun (not at you… don’t worry), and quickly whisper a word immediately afterwards, you wouldn’t hear the whisper. The gunshot and the whisper didn’t happen simultaneously, but there is temporal masking that causes you to not hear the quieter sound for a little which after the loud sound has happened.
Even weirder, there is an effect called pre-masking. If I were REALLY quick and VERY well-timed, I could whisper the word right BEFORE the gunshot and you also wouldn’t hear it. The loud sound (the gun shot) not only masks quiet sounds that come after it, but also sounds that come before it.
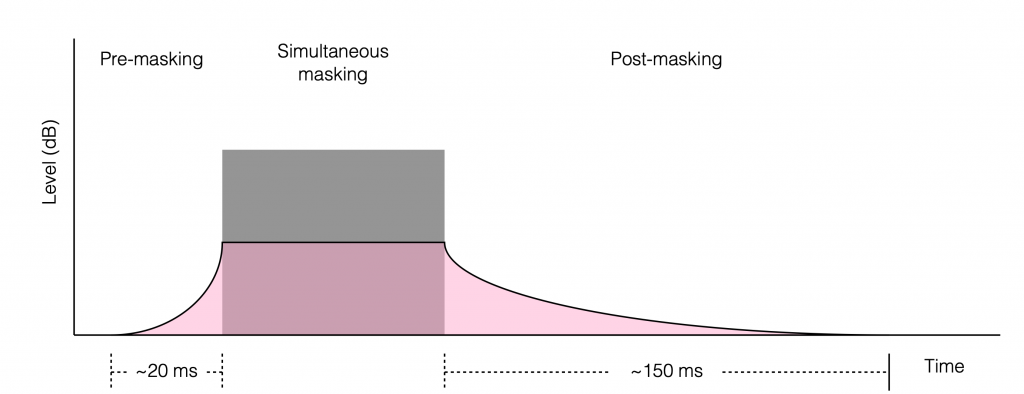
Fig 1. Generalised representation of temporal masking. The gray block is a loud noise. Anything in the pink area won’t be heard by most people most of the time. This plot is intentionally vague. The point is the effect, not the actual values.
So, if I were to play a loud noise (a gunshot, a blast of pink noise, a portion of an AC/DC song) and play a quiet sound before, during, or afterwards, and ask what the quiet sound was (to test if you heard it) your behaviour will match something like the plot in Figure 1. The gray block represents the loud sound. Anything in the pink shape is “stuff you can’t hear”. If the quiet sound occurs much earlier or much later than the loud sound, then it will have to be really quiet for you to not hear it. The closer in time the quiet sound occurs to the loud sound, the louder it has to be for you to hear it.
Of course, this is very general plot, so don’t use it for arguments while you’re drinking beer with your friends. For example, one element that I have not mentioned is frequency content. If the loud sound is the low frequency effects of a recording of distant thunder, and the quiet sound is a kitten mewing, then these two sounds are too far apart in frequency to have any influence on each other, and the graph is just plain wrong.
Signal Envelope
Unless you, like me, spend a lot of time listening to sinusoidal tones, you’ll notice that everything you listen to varies in level over time. This happens on different time scales. The sound pressure level (SPL) in the car while you’re driving to work or at the daycare picking up the kids is much louder than the SPL in your bedroom while you’re dealing with the free-floating existential anxiety that comes to visit at 2:00 in the morning. This is the ‘slow’ time scale. On the ‘fast’ end of the time scale, you have the extreme, and short SPL cause by closing a car door, or the very short, but not very loud sound of a high heel impacting a hardwood or tiled floor. Speech is somewhere in between these two. There are short, spikes caused by “t-” and “k-” sounds, and long-ish portions produced by vowels.
Note that we’re not really talking about how loud or how quiet things are. We’re talking about the change in level from quieter to louder and back again.
If we plot that change over time, we have a view of the signal’s envelope. For example, a single note on a piano has a fast attack (from quieter to louder) and a slow decay (from louder to quieter). A car horn honked in an open area (not a city intersection, where there are buildings to reflect the sound) has almost identical attack and decay envelopes.
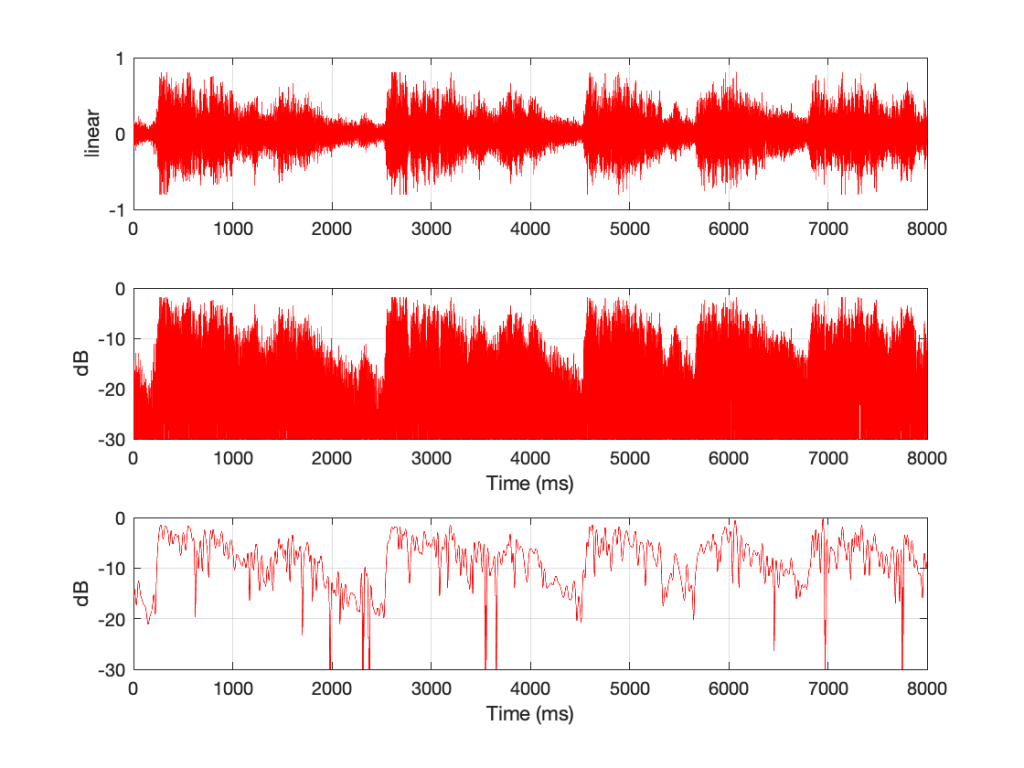
Fig 1. Three different representations of an audio signal in time.
Figure 1 shows an 8-second slice of a recording of the Alleluia Chorus from Handel’s “Messiah”, chosen because it’s easy for me to load that into Matlab using the “load handel” command, and I’m very lazy.
The top plot shows the signal in the way we’re used to looking at sound files. The x-axis is time, in ms. The Y-axis shows the linear value of each of the samples. Oddly, this is the way we normally look at sound files, but it represents how we hear sound very poorly, because we don’t hear amplitude linearly.
So, in the middle plot, I’ve taken the same data and, sample-by-sample, plotted each value on a decibel scale (using the equation DisplayOutput = 20*log10(abs(signal)). The absolute value is there because calculating the log of a negative number gives you strange results)
The third plot is the one we’re really interested in. That’s created by connecting the peaks in the middle plot, which results in a running plot of the signal’s level over time. This is its envelope. As you can see in that particular musical example, the attacks (the changes from quieter to louder) are steeper (and therefore faster) than the decays. This is not surprising. It’s hard to get an orchestra and choir to all stop instantaneously…
Fig 2. The same treatment to a different audio signal. In this case, it’s female speech recorded in an anechoic chamber.
Figure 2 shows the same three ways of plotting an audio signal, but in this case, the signal is female speech recorded in an anechoic chamber. Notice that, partly because it’s only one sound source and partly because there is no reverberation in the signal, the decays are almost as fast as the attacks. However, this is a very strange recording. Most people don’t listen to anything in an anechoic chamber, and we don’t typically go to the middle of a football field or a frozen lake to have a conversation.
Back to the “so what?”
Let’s assemble the three collections of information that we’ve been throwing around.
Firstly, focusing on filter response:
We know that filters can ring.
We also know that some filters can pre-ring.
We also know that, unless the Q is really high, that ringing decays pretty quickly.
Finally, we know that, if the frequency that’s ringing in the filter is not present in the signal, it won’t ring because there’s nothing there to ring. (Similarly if you turn up the low bass while listening to a solo piccolo recording, you won’t hear a difference because there’s no bass to boost.)
Secondly, we looked at our own response to quiet and loud signals in time
A loud sound will simultaneously mask a quiet sound that occurs at the same time (fancy-talk for “drown it out so I can’t hear it)
The loud sound will also post-mask a quiet sound that occurs after within a short time window (on the order of 100 – 200 ms)
The loud sound will also pre-mask a quiet sound that occurs before it within a short time window (on the order of 10 – 20 ms)
Finally, we looked at signal envelopes – the change in level of an audio signal over time
Sounds never start instantaneously. In order to do so, they would have to have an infinite frequency range measured at the receiver (e.g. your eardrum, which is most certainly band-limited as well). Even very fast attacks take milliseconds to ramp up.
Sounds in real life have longer decay times
I know, I know, you can name sounds that have very fast attacks (e.g. the pluck of a harpsichord plectrum on a high string, or a single xylophone bar struck in an anechoic environment) and very fast decays (ummm…. good luck finding something that decays more than 100 dB in less than 100 ms…)
The question is: if you have a filter that rings or pre-rings, and you apply it to a sound,
Is that ringing the thing that defines the envelope of the resulting sound? In other words, does the signal’s attack and/or decay envelope change significantly as a result of the time response of the filter?
Is that change in the envelope outside the limits of your ability to detect it due to pre-masking and post-masking?
There is no single answer to this question. If the audio signal is someone hitting a rim shot, and the filter is a peak filter with 12 dB of gain at 500 Hz with a Q of 100, then you’ll hear it ringing. In fact, it will sound like a rim shot with a sine wave generator. If the audio signal is a single bowed note on a ‘cello, and the filter is a dip filter with -3 dB of gain at 100 Hz with a Q of 0.707, then you won’t.
However, (for example) you CANNOT automatically jump to a conclusion that “pre-ringing sounds unnatural” because that starts with the assumption that you can hear it, and therefore it sounds “like” anything.
Whether or not you can hear the effects of a filter applied to an audio signal is dependent not only on the very specific characteristics of the filter, but its interaction with the signal. Change the filter OR change the signal, and the result will change.
This means that you CANNOT say things like “linear phase filters are better (or worse) than minimum phase filters” or “the pre-ringing of a linear phase filter sounds unnatural” because both of those statements start with the (possibly incorrect) assumption that you can hear the effect of the filter.
Now, don’t mis-interpret what I’ve said to mean “you can’t hear a filter ringing” – I didn’t say that. What I said was “just because a filter can be measured to be ringing doesn’t necessarily mean that you can hear it with a given audio signal”.
In this part, we’re going to do something a little weird.
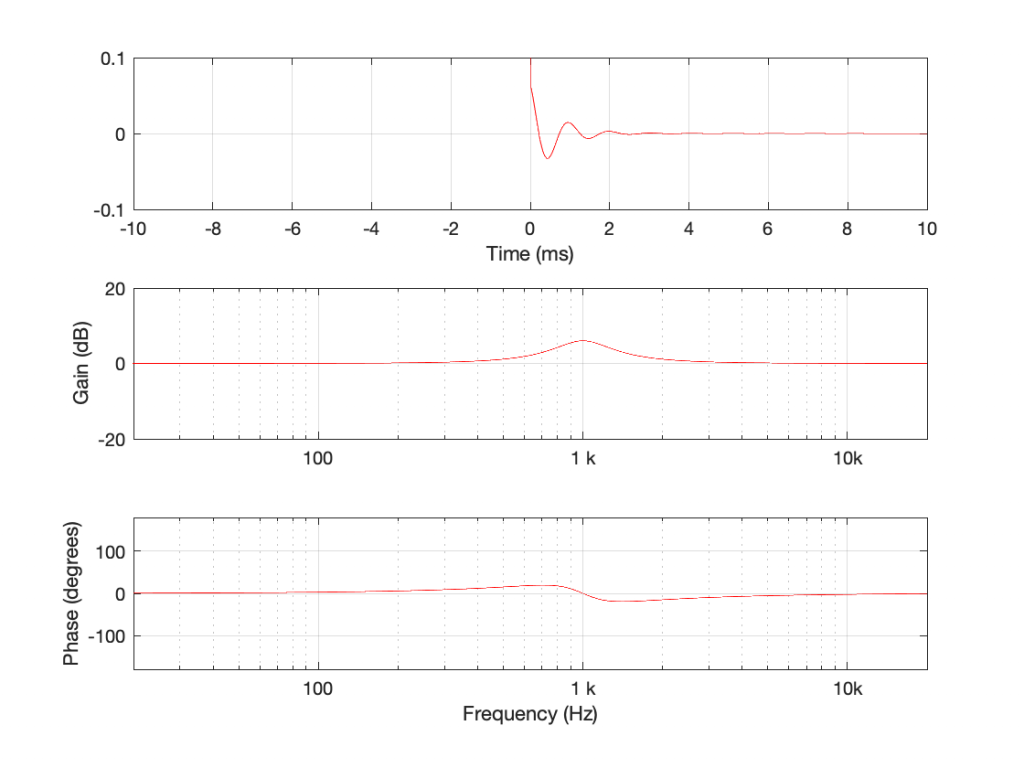
We’ll start by making a minimum phase peaking filter that has Q of 2 and a gain of +6 dB. The response of that filter is shown in Figure 1.
Fig 1. A minimum phase implementation of a peaking filter with a centre frequency of 1 kHz, a gain of 6 dB and a Q of 2.
Almost everything in the plots above should look familiar. The one weird thing is that I’ve left out the data in the time response before T = 0 ms. That’s because the future doesn’t matter, since we’re talking about a non-causal filter, right?
What if I (for some reason) wanted to make a filter that had a desired magnitude response, but a flat phase response? Let’s say that you’re allergic to phase shifts or you belong to an ancient religious cult that thinks that phase shifts are against the order of nature. How would we create that filter?
One way to do it is to create a filter that has the same magnitude response as the one above, but with an opposite phase response so that the two cancel each other. But, how do we create a filter with the opposite phase response?
One trick for doing this is to ignore what I said earlier. Remember when I was being pedantic about how filters advance signals in phase BUT NOT TIME? What if you were to ignore that for a brief moment? Could we use that ignorance to an advantage?
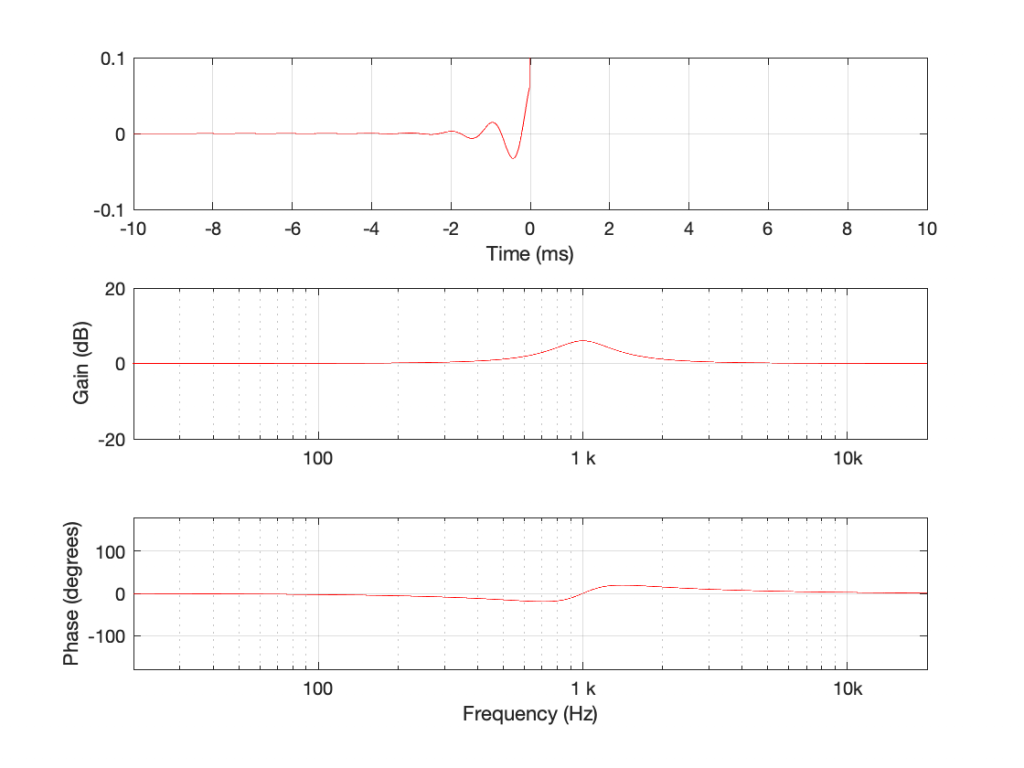
For example, what would happen if we took the time response shown above and reversed it? All of the component frequencies are still there, at all the same relative amplitudes. So the Magnitude Response won’t change. But what happens to the phase response? The answer is this:
Fig 2. The same impulse response as shown in Figure 1, reversed in time.
Now we have a weird filter that can only have an output based on future inputs (therefore it’s non-causal, and therefore not minimum-phase), with the same magnitude response as the one shown in Figure 1. But check out that phase response. It’s the inverse of the first filter.
So reversing time has the effect of flipping the polarity of the phase (not the polarity of the signal!) without modifying the magnitude response. What would have been a 45º phase shift (earlier) becomes a -45º phase shift (later).
So, if I were (conceptually – not really…) to put these two filters in series, feeding the output of one into the input of the other then their total magnitude responses would add (so I’d get a 12 dB boost instead of a 6 dB boost at 1 kHz) and their phase responses would cancel each other out. The end result would look like this:
Fig 3. The combination of the filters in Figure 1 and Figure 2. Notice that it has a gain of 12 dB at 1 kHz (because 6 + 6 = 12)
By now, you’ve probably figured out that what we’re looking at here is a linear phase filter, since can be used to change the magnitude response of a signal without mucking up its phase response.
The catch with this way of implementing a linear phase filter is that it has to see into the future. Of course, in real life this is difficult, but there is a trick you can use to fake it.
If you look at the impulse response plot in Figure 1, you can see that the peak in the response is at Time = 0 ms. As you get later, moving away from that moment in time, the signal is quieter and quieter until it dies away to (almost) nothing. The problem is that ‘almost nothing’ is not the same as ‘nothing’. In fact, if we’re being pedantic, the ringing keeps going forever, which is why it’s called a filter with an Infinite Impulse Response – an IIR filter.
This also means that the same is true for the filter in Figure 2, but the ringing extends infinitely backwards in time.
However, our resolution in measuring and storing the amplitude is not infinite – when the signal is quiet enough, we run out of resolution (‘ticks’ on the ruler) – and when the signal gets that quiet, it effectively becomes the same as nothing.
So, if we decide on the level where ‘almost nothing’ is the same as ‘nothing’ (this is more-or-less up to us if we’re the ones designing the filter), then we can look at the filter’s response and decide when that signal level is reached (both forwards and backwards in time).
For example, with the extremely limited resolution of the plots that I’ve made above, we can decide that ‘nothing’ is what’s left when you get ±10 ms from the impulse peak. Of course, the resolution of the pixels on that plot is not even close to the resolution of the audio signal, so ‘nothing’ on our plot and ‘nothing’ for the audio signal are two different things – but the concept is the same.
Back to the Future
Let’s pretend for a moment that, for the impulse response in Figure 3, we decide that ±10 ms is the window of time we need to get to ‘nothing’. This means that we could implement this filter by sending audio into it, letting it pre-ring with an increasing amount until it hits the maximum peak 10 ms after the sound comes into it, then ringing for another 10 ms until it’s out.
This means that the latency (the delay time between the input and the output of the filter) would appear to be 10 ms. Yes, when you feed in a signal, you immediately start getting something out of the filter, but the output is loudest after the signal has been feeding into the filter for 10 ms.
In other words, if you want to have a linear-phase filter that’s implemented using this method, you are going to have to accept that the cost will be latency. In our case (a filter with a Q of 2, with a centre frequency of 1 kHz, and the decisions we’ve made here) this results in a 10 ms latency. Change a parameter, and you change the latency. For example, as we’ve already seen, the lower the centre frequency, the longer in time the filter will ring. So, if we change the centre frequency of this filter to 100 Hz, then it will have 10 times the latency (because 100 Hz is 1/10 of 1 kHz – therefore the periodicity of the ringing is 10x longer). If we increase the Q, then the ringing lasts longer – both forwards and backwards and time.
Generally speaking, this means that, if you’re building a linear phase filter, you need to decide what characteristics the filter has, and then you need to start making decisions about the quality of the filter (e.g. is the response exactly what you want, or is just almost what you want?) and its latency.
Although I’m not going to talk about implementation much, the latency has two primary considerations. The first is obvious: are you willing to wait for the output? If you’re building a filter for a PA system, then you don’t want the output delayed so much that it sounds like an echo. However, the second issue is one for the person building the filter: latency means memory. This was a bigger problem in the ‘old days’ when memory was expensive, but it’s still an issue.
Why? The problem is that the latency is defined by the frequency and Q of the filter, which define the total time the filter takes to get through the entire impulse response. However, the filter’s processing doesn’t think of time in milliseconds, it thinks in samples. If you double the sampling rate, then you double the amount of memory you need to implement the filter.
So, going from 48 kHz to 192 kHz requires 4x the memory.
A little perspective
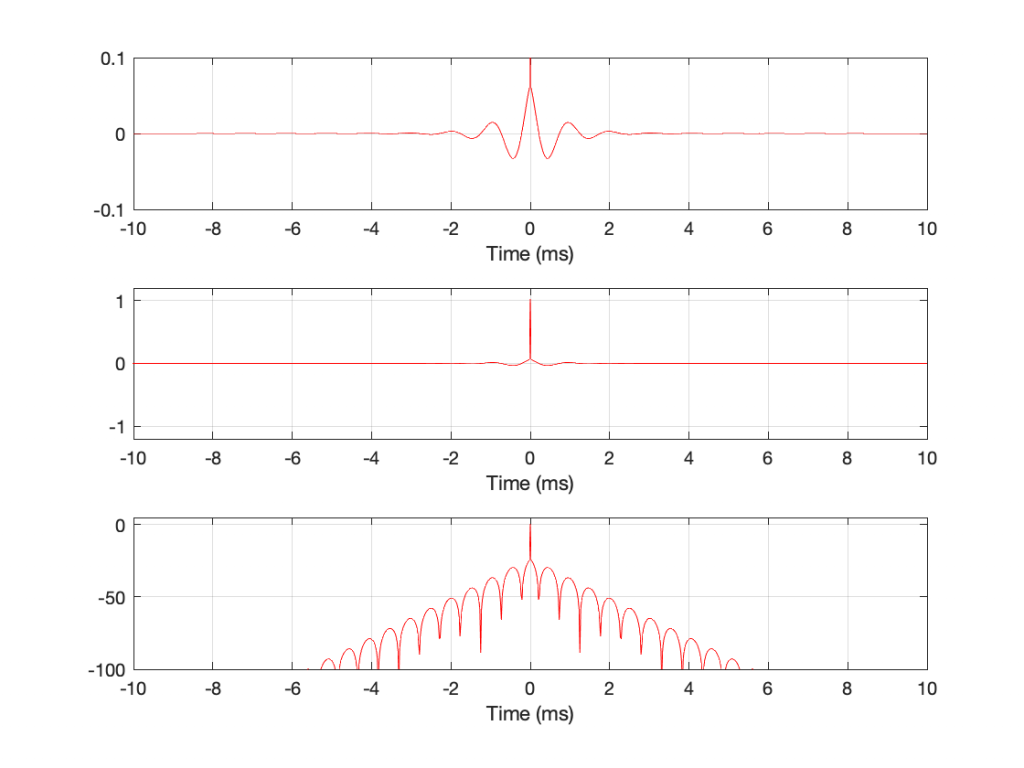
One thing to notice in the three figures above is the vertical scale of the time response plots. You can see there that the range is ±0.1, which is a zoomed-in view of the amplitude. This may give you a distorted impression of the level of the ringing relative to the signal (the impulse). Figure 4 should clear this up.
Fig 4. Three plots showing exactly the same data in three different ways.
The top plot in Figure 4 is identical to the top plot in Figure 3. The middle plot is also on a linear amplitude scale, but the range of the plot shows the entire range of the signal. You can see there that the impulse at T = 0 hits a value of 1, and so the pre- and post-ringing isn’t as loud as you might have thought based on the first three figures.
The bottom plot shows the same information, plotted on a dB scale instead. The impulse at T = 0 ms hits 0 dB. Relative to that, the pre- and post-ringing has a maximum value of about -24 dB. You can also see there that the ringing is at least 100 dB down by the time we’re 6 ms away from the main impulse, looking both backwards and forwards in time.
Of course, all of these characteristics would be different for filters with different parameters. The point here is to understand the general characteristics, not the specifics.
Additional Comment
You may read on various fora someone who claims that there’s no such thing as “pre-ringing”. “It’s ‘ripple'” They’ll claim.
This is incorrect.
Pre-ringing and ringing are behaviours that occur in the time domain.
Ripple is a wiggle in the response in the frequency domain. (Say, for example, you zoom into the magnitude response, it won’t be completely flat in some cases – and if it’s not, you have ripple.)
I’m going to start this part by doing something I very, very rarely do: to quote Wikipedia.
“In control theory and signal processing, a linear, time-invariant system is said to be minimum-phase if the system and its inverse are causal and stable.”
However, in my defence, one of the references attached to that statement is Julius O. Smith III, so that makes it okay.
Let’s unwrap that sentence and see if we know enough to know what it’s telling us.
We don’t care about control theory. So let’s ignore that part. We’re only interested in signal processing, where our signal is audio; so we move on.
We already know what a ‘linear, time-invariant” system (like our filters) is, and we now know that we can say that that system is ‘minimum-phase’ if:
the system (our peak filter in the previous part, for example)
and its inverse (our dip filter in the previous part, for example)
are causal
and stable
Let’s deal with the ‘stable’ part first. We know that our two filters are stable because we saw that their poles are inside the unit circle in the Z-Plane representation. (We also know it because they both have ringing that decays instead of increases over time.)
We also know that their zeros are also inside the unit circle, since the zeros of each filter are in the same place as the poles of the other filter, which we already said, are inside the unit circle.
So, what does ‘causal’ mean? It’s really just a fancy word that means that the output of our filter is determined by either the past or the present, or some combination of the two. In real life, all filters and systems are causal, since they can’t do something based on what will happen in the future.
However, if you are not working in real time, you can easily create systems and filters that are non-causal and have outputs that are created by events in the future. One simple example of this is to record your voice, reverse the track, add some reverb, and then reverse it back again. Now you have reverb that ramps up to a sound before it starts. This is non-causal.
Do I care?
Not yet. But keep the two conditions in mind:
Both the filter and its inverse must be ‘causal’. The output of a minimum phase filter can only be the result of the present or the past, never the future.
Both the filter and its inverse must be stable. We like stable…
In this part, I’m going to deviate just a little from something I said at the beginning of this series. To be honest, if I hadn’t admitted this, you probably wouldn’t notice – but I would prefer to keep things clean… The deviation is that, for this part, I’m making a slight change to how Q is defined. This is not serious enough to get into the details of exactly how the definition is different .
Using the slightly-different definition of Q, let’s make a peaking filter with a centre frequency of 1 kHz, a boost of 12 dB and a Q of 2. This will have the response shown below in Figure 1.
Fig 1. The response of a peaking filter. Fc = 1 kHz, gain = 12 dB, Q = 2
Using the same modified definition of Q, let’s also look at the response of a dip filter with the same parameter values, but a gain of -12 dB instead.
Fig 2. The response of a dip filter. Fc = 1 kHz, gain = -12 dB, Q = 2
If you look at the magnitude responses of these two filters, you’ll see that it looks like they are mirror images of each other. In fact, they are.
If you look at the phase responses of these two filters, you’ll also see that it looks like they are mirror images of each other. In fact, they are.
If you look at their impulse responses, you’ll see that it would be difficult to see that they are related at all… But never mind this.
If I connect the output of the first filter to the input of the second filter, and measure the total throughput of the system, it will look like this:
Fig 3. The response of the combination of the boost and the dip filters from Figures 1 and 2.
Just in case you’re suspicious, I didn’t fake this. I actually connected the boost to the dip and sent an impulse through the whole thing and you’re looking at the result. No tricks! (Note that I could have reversed their order with the same total result.)
What you can see here is that the responses of the dip and the boost negate each other. Whatever one does, the other does exactly the opposite.
Generally speaking, we audio geeks use some special words to describe not-very special cases like this.
Often, you’ll hear us talking about a linear system which is a fancy way of saying ‘the effects of this system can be undone’. In this example, the dip filter can ‘undo’ the effect of the boost (and vice versa) therefore both must be linear filters.
Just as often, you’ll hear us talking about time-invariant systems, which just means that they don’t change over time. Because I implemented those two filters using equations done on my computer, if I run the math again tomorrow, I’ll get exactly the same answer. If I test them using an impulse that is quieter or louder, I also get exactly the same responses. (If I had implemented them using resistors and capacitors and transistors or vacuum tubes, I might not get the same answer tomorrow or with a different signal level because of temperature changes, for example. Although now I’m really splitting hairs, just to make a point.)
The reason I said “just as often” is because, normally we use the two terms together as a package deal. So, we ask whether a system (like something as simple as a filter or as complicated as a reverb unit or an upmixing algorithm) is Linear Time-Invariant or LTI. This is an important question because it packs a lot of information in it.
For example, if a reverb unit is LTI, then I can measure it today with an impulse, and I know that it will behave the same tomorrow with lute music or a snare drum. It does the same thing all day, every day, regardless of the input signal or its level. One measurement, and I can go away and analyse it for the rest of the week.
If it’s not LTI, then its characteristics will change for some reason that I don’t necessarily know. Maybe the internal delays are modulating in time, so its response in 10 seconds will be different than it is now. Maybe it has a compressor or a noise gate built in, so it changes its behaviour according to the level of the signal.
If we get back to our (rather simple) peak / dip filter example. We know they’re LTI (because I said so – and you have to trust me). We also know that the dip filter is the opposite of the boost. The question is “how, exactly, did I make this happen?”
The general answer to this question has already been answered – the magnitude and the phase responses are mirror images of each other. Therefore, for any given frequency, one filter boosts by the same amount that the other cuts, and one filter advances in phase by the same amount that the other delays in phase.
The more geeky answer to this question requires that we look at the Z-Plane, which I’ve talked about throughly in another series of postings starting with this one. I’ll repeat myself a little by saying that a Z-Plane representation shows a different way of looking at the ‘ingredients’ in a filter. It contains ‘poles’ that are placed at frequencies that are infinitely boosted, and ‘zeroes’ that are placed at frequencies that are infinitely cut. By carefully placing poles and zeros relative to each other in the Z-Plane, you can decide how the filter will behave for other frequencies between 0 Hz and the Nyquist frequency.
When you design (or analyse) filters this way, there are a couple of basic rules:
The ‘safe zone’ in the Z-Plane is defined by a circle. If you start placing poles outside it, then the filter can become unstable. If a filter is unstable, this means that its ringing can get louder over time instead of decaying.
If you place a pole in exactly the same place as a zero, they cancel each other out, and the total result is as if neither were there.
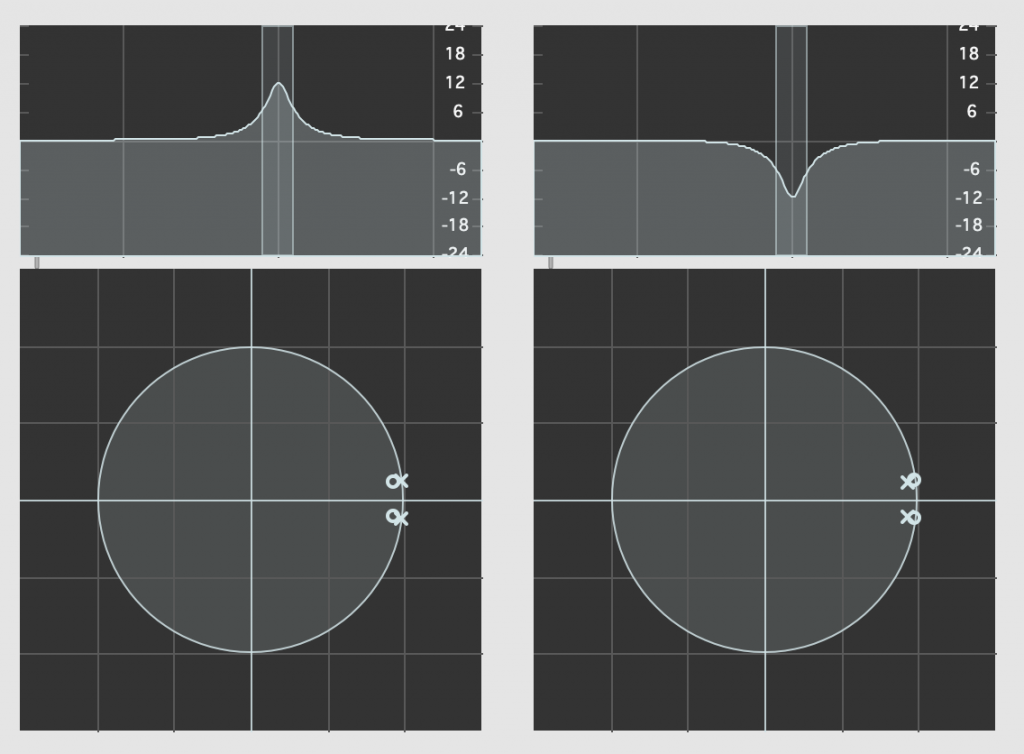
So, let’s look at our two filters above in their Z-Plane representations.
Fig 4. The same two filters, including their Z-Plane representations (for a system running at 48 kHz)
Admittedly, the resolution of the display in the software that I’m using to show this isn’t great, but if you compare the Z-Plane plots on the left and right, you can see that the zeros (marked with ‘o’) and the poles (‘x’) swap places. Just to make things a little clearer, I moved the centre frequency to 10 kHz and kept the gain and Q values the same. These are shown in Figure 5.
Fig 5. The same two filters but with their centre frequencies moved to 10 kHz, including their Z-Plane representations (for a system running at 48 kHz)
What’s the point of showing you this? The Magnitude and Phase response plots (which, combined, comprise the filters’ Frequency Responses) are ‘just’ descriptions of the behaviour of the filter. They tell you what happens to a signal that goes through them.
The Z-Plane representations show you how the filters are actually implemented.
It’s like the difference between reading a description of how a cake tastes and reading the recipe.
What you can see in the Z-Plane is not only that the responses of the filters negate each other: they’re built to ensure that this is the case. The poles and zeros of one filter cancel the zeros and poles of the other, and vice versa.
There’s one other extra piece of information that you already know. The fact that the poles for any of these filters are inside the circle helps to tell us that they’re stable and therefore LTI. It also tells us something else that we’ll talk about in the next part.
Let’s put together a couple of things that were said in the last postings, which should help to support each other:
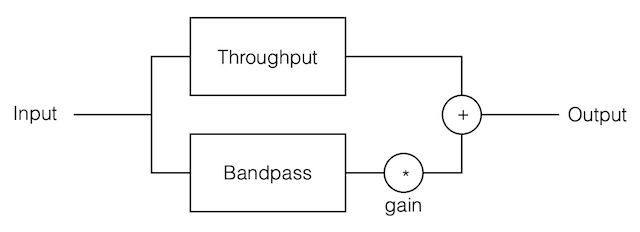
A peak or a dip filter is created by adding a bandpass filter to a throughput, as shown in Figure 1.
Fig 1. The individual building blocks of a peak/dip filter
To change from peak to dip, you switch the polarity of the bandpass portion by making the “gain” negative instead of positive. (In other words, you subtract the bandpass from the throughput instead of adding it). To change the gain of the peak/dip filter, you change the gain of the bandpass portion. To change the Q of the peak/dip, you change the Q of the bandpass.
We also saw at the end of Part 3 that changing the gain does not change the rate of the decay.
This should all come together nicely to make sense for the first of the three points. For example, since the bandpass portion is the part that’s ringing, and since changing the gain of the peak (or dip) is just a matter of changing the gain applied to the bandpass portion, then there is no reason why the decay rate of the ringing should change. It will start at a higher or lower level, but its decay slope will be the same.
Q vs Time
We also saw at the end of Part 3 that changing the Q will change the slope of the decay inversely proportionally, but that changing the frequency will change the slope of the decay proportionally.
There is a nice little rule-of-thumb that’s used by electrical engineers for measuring the Q of a filter. Let’s say that you can’t (or couldn’t be bothered to take the time to) measure the frequency or magnitude response, and you want to figure out the Q based on the time response only, you can calculate this by looking at its impulse response.
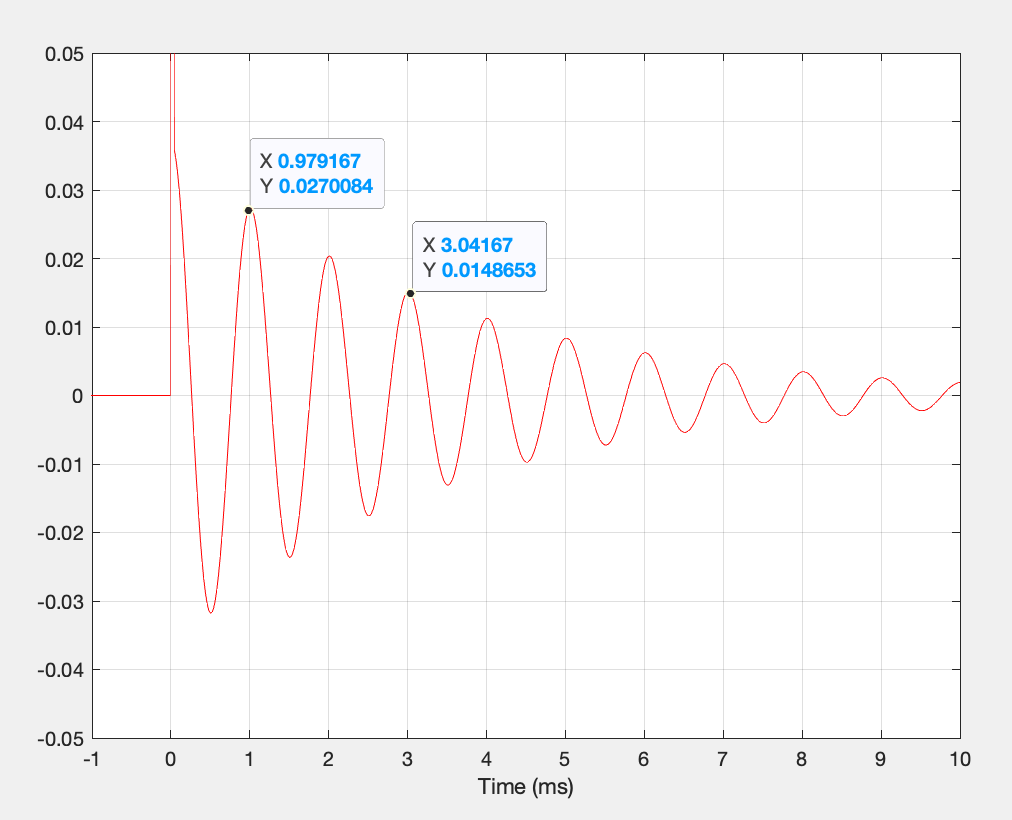
Fig 2. The time response of an unknown peaking filter. (You can tell it’s peaking because the ringing cosine wave starts above the 0 line, just like the initial impulse.)
For example, Figure 2 shows the initial part of the impulse response of an unknown filter. I’ve highlighted two points that are reasonably close to the tops of two of the cosine wave cycles. I picked the first one (on the left) and then noted its Y value (Y = 0.027). Then I found a top of another wave that was as close to half that value as I could find. You can see there that it’s 2 cycles later, where Y = 0.0149.
So, you multiply the number of cycles it takes to drop by 50% (in this example, 2 cycles) and multiply that by 4.53, which results in a value of about 9. This is a good estimate of the Q of the filter (which is actually 10, if I measure it using the -3 dB points in the magnitude response).
If you’d like to read the long version of this, check out this page.
Note that it doesn’t matter which cycle I chose to get the first value, since the rate of decay is the same through the entire time response of the filter. In other words, if I chose the 3rd cycle to do the first measurement, I would have found that the 5th cycle is about 50% lower because it’s also 2 cycles later.
It also doesn’t matter whether we’re talking about peaks or dips, since, as we already know, from a perspective of the individual building blocks of the filter, these are the same thing.
So what?
Of course, most normal people aren’t measuring the time response of filters to calculate the Q. However, this piece of information is good from the opposite perspective: if you know the Q of the filter, you can figure out how fast it’s decaying. For example, a filter with a Q of 2 will take 2 / 4.53 = 0.44 cycles to decay by 50% (or 6 dB). If you know the frequency, then you can then translate that into a decay rate per seconds, because the period in seconds (the total time of one cycle of the wave) = 1 / Fc.
So, if that filter with a Q of 2 has an Fc of 100 Hz, then the period is 1/100 = 0.01 sec, and therefore it will decay by 6 dB (50%) in 0.44 cycles * 0.01 sec/cycle = 0.0044 sec or 4.4 ms.
If the Fc of the filter is 5 kHz, then the the period is 1/5000 = 0.0002 sec, and therefore it will decay by 5 dB in 0.0002 * 0.44 = 0.000088 sec = 88 µsec. (This is roughly equivalent to 2 samples at 48 kHz.)
Another good thing to remember is that Q = Fc / BW where BW is the bandwidth of the response measured between the two -3 dB points. This means, for example, that if Q = 1, then Fc = BW, therefore the bandwidth is about 1 octave. If Q = 2, then the bandwidth is about 1/2 of an octave, if Q = 12 then the bandwidth is about 1 semitone (1/12th of an octave), and so on.
If you you get an audiometry test done, you’ll be shown into a small room, about the size of a public bathroom stall. Someone will put a pair of headphones on you, and pass you a small handle with a button. Your instructions are to press the button if you hear a tone. Then the audiometrist will leave the room, closing the door, and you’ll suddenly realise that if there’s any noise in this room, it’s because you’re making it.
Then you hear a beep in your left ear. You press the button. You hear a quieter beep. Press. Quieter beep. Press…. …. …. Beep, press… …. …. …. Beep, press…. New frequency beep, loud again. Press… and so on.
What’s happening here is that you’re presented with a sine tone at some frequency, probably loud enough for you to hear. You press. The tone gets quieter, and you press again. Eventually, the tone is so quiet that you cannot hear it (this is normal) so you don’t press. So, the tone gets louder, and you press. Then it gets quieter again, until you can’t hear it again.
By crossing over that threshold of “can hear” and “can’t hear” a couple of times, the audiometrist finds out whether or not you got lucky… If you bottom out at the same level a couple of times in a row, then that’s your threshold of hearing at that frequency in that ear.
The frequency changes (usually by 1 octave, but sometimes less), and the whole process is repeated.
If you get a full test done, then this is probably done at 9 frequencies (250, 500, 1k, 1.5k, 2k, 3k, 4k, 6k, and 8kHz) in both ears individually – 18 tests in all.
You’ll then be given a sheet of paper, or at least shown a plot of your hearing threshold. Typically, if you have “normal” hearing (whatever that means) your thresholds will all be sitting on a horizontal line marked 0 dB. If you’re “better than normal” then you get a negative score, if you’re “worse than normal” you get a positive score.
What does this mean?
Let’s start over.
If a lot of people do this test, and we only test at 1 kHz, we’ll find out that, after the results are averaged, the group can hear the 1 kHz sine tone when the change in air pressure at the ear entrance is 20 µPa. We’re not going to talk about what this means other than to say that “sound is a change in air pressure over time, and that pressure is measured in pascals, abbreviated Pa”. Needless to say, 20 µPa is pretty quiet, since it’s the quietest sound a group of people can hear at 1 kHz when you take their average.
If you did that test at a much lower frequency, you would find out that people aren’t as good at hearing quiet sounds. In other words, at 100 Hz, the sine tone has to be louder than 20 µPa for people to hear it.
The same is true if you repeated the test at a much higher frequency – say, 10,000 Hz.
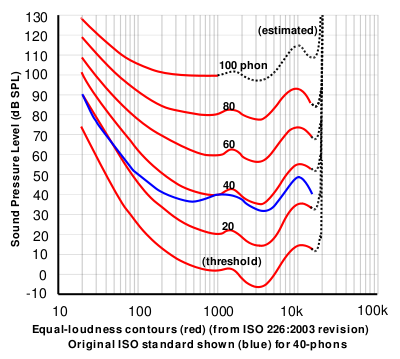
If you did this test at a lot of frequencies, then you’d find out that, on average, the threshold of hearing for a human follows the bottom red line of the plot in Figure 1, borrowed from Wikipedia.
Figure 1: The bottom red curve is the average threshold of hearing for a human being.
That bottom plot shows the threshold of hearing for different frequencies, plotted in dB SPL. Notice that, at 1 kHz, the line is at 0 dB SPL. This is because 0 dB SPL is defined to be the average threshold of hearing of a human at 1 kHz, which is 20 µPa. So, it’s not an accident…
Looking at that plot, you can see that, in order to hear a sine tone at 20 Hz, the tone has got to be more than 70 dB louder (that’s a LOT louder). So, a microphone “sees” a 73 dB SPL, 20 Hz sine tone as being louder than a 0 dB SPL, 1 kHz sine tone – but as far as you’re concerned, they’re both “the quietest sound you can hear” – therefore, they’re the same level.
If we take that threshold of hearing curve, and we play tones at those levels for those frequencies, then you should “just be able to” hear them. So, we’ll call those levels “0 dB” – since it’s the same as what is expected of you.
In other words, the piece of paper you got from the audiometrist tells you how much above or below that red threshold of hearing YOU sit.
Now, let’s back up a bit.
I said that, in your test, you only went up to 8 kHz. This is because, above that (and possibly even before that) the headphones might not be trust-worthy, and even a tiny movement (say a couple of millimetres) in the position of the headphones will have a (relatively) big effect on the level at your eardrum. So, rather than get people worried about losing their hearing at 20,000 Hz (when, in fact, they were actually just wearing the headphones 1 mm too far forward), you won’t get tested.
Notice how variable that threshold of hearing line is. There are big changes in level over the “audible” frequency range.
Remember that the threshold of hearing curve is an AVERAGE of a lot of people. Just like no one has 2.6 children, no one has this exact response. And, if you are some freak of nature and you DO have exactly that response, you don’t for long… we all get old…
Notice how that threshold of hearing curve only goes up to about 16 kHz, and above that it says “estimated”. See point #1.
Now, you should know that your ability to hear a sine tone at some frequency is defined as how your ability compares to an expectation based on an average, within a relatively small frequency band: 250 to 8 kHz.
Then you look at a textbook or you read a website that says “humans can hear from 20 Hz to 20 kHz”, which is not enough information to be either true or false… It’s like saying “humans are usually between 0 and 10 m tall” which is also sort of true, but also adequately vague to be potentially worse-than-useless information.
The truth is, unfortunately, much more complicated… However, it’s fair to say that, in order for you to just hear a sine tone at 20 kHz, it would have to be much, much louder than one at 1 kHz. In fact, if I played a 20 kHz sine tone loud enough for you to hear, measured that level, and then played a 1 kHz sine tone for you at the same level, you’d probably punch me – after you had passed out due to the pain, woken up, hunted me down, and found me… (I’d already have run away by then….)
So what?
We humans like nice, tidy, answers. “It will rain tomorrow” is preferable to “there is a 70 – 80% chance of scattered showers in the afternoon tomorrow”. We even get mad when the information is correct, but we interpret it tidily… For example, we’ll complain about getting rained on in the middle of our hike, when there was only a 10% chance of rain. On the other hand, if there was a 10% chance of winning 1 Million dollars in the lottery, we’d all buy a ticket.
Anyways, once-upon-a-time, when the committee for inventing the compact disc was holding meetings, they said “what should the sampling rate be?” and someone said “at least 40 kHz, because we can hear up to 20 kHz”. (The reason it’s 44100 is related to the fact that the bits were stored as black and white stripes on video tape, and NTSC and PAL come close to meeting each other close to that number, when you look at the numbers of lines per field and frames per second.)
Of course, like any first-generation thing, digital recording equipment wasn’t very good at the start (back around 1980 or so) – so the first DDD recordings that were released on CD sounded… well…. weird. There was quantisation distortion because they hadn’t figured out dither yet, only 12 or 13 of the bit values were working properly on the ADC’s, the anti-aliasing filters were implemented as analogue circuits, so they let some stuff through that aliased, and they rang (“sang along”) with the signal at a high frequency… All of that added up to “weird” – possibly even “bad”. Then, people who had good equipment (high-end turntables or, even better, 1/4″ tape running at 30 ips) listened to this new format, decided it was bad, and that was that.
Some of them asked “why is is bad?” and one answer they came up with was the band limiting… If the system can’t capture or store or play materials above 20 kHz, then it’s useless… Right? Maybe…
Then, instruments were put in front of measurement microphones and spectra were measured – and the proof was in. Trumpets with harmon (wah-wah) mutes, when pointing directly at the microphone, contain harmonics as high as 50 kHz! This must explain why CDs sound bad! Right? Maybe…
Then Rupert Neve did a demo at an AES (Audio Engineering Society) convention where he played people two tones. Both were at 7 kHz, but one was a sine wave and the other was a square wave (at some level). The question was: have a listen and tell me which is which. The results were the same as if everyone was just guessing. (Remember that, in order to make a square wave, you need to add odd harmonics – so the lowest-frequency content difference between a 7 kHz sine wave and a 7 kHz square wave is at 21 kHz.) Proof that we don’t need to go above 20 kHz, right? Maybe…
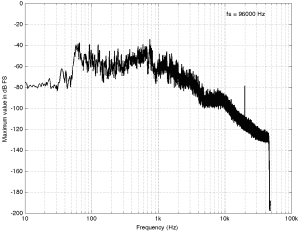
Some years ago, I took some “high resolution” audio files and measured their spectral content. One particularly interesting result is shown in Figures 2, below.
Figure 2: The spectral content of a 96/24 “high resolution” audio file I bought.
Look at that spike in the top end – around 20 kHz. What musical instrument makes that sound? The answer is “no musical instrument makes that sound – at least none of the baroque instruments in that recording make that sound. As I wrote back in 2014:
If you’re wondering what it might be, I asked a bunch of smart friends, and the best explanation we can come up with is that it’s noise from a switched-mode power supply that is somehow bleeding into the recording. HOW it’s bleeding into the recording is a potentially interesting question for recording engineers. One possibility is that one of the musicians was charging up a phone in the room where the microphones were – and the mic’s just picked up the noise. Another possibility is that the power supply noise is bleeding electrically into the recording chain – maybe it’s a computer power supply or the sound card and the manufacturer hasn’t thought about isolating this high frequency noise from the audio path. Or, maybe it’s something else.
Interestingly, this is a conflict of two engineers. The designer of the power supply (assuming that’s what it is…) said “I’ll put the switching frequency above 20 kHz so that no one will hear it” and the recording engineer said “I’ll record this at 96 kHz so that people can get the content they’re missing…” The problem is that the content you’re missing is something you don’t want…
Similarly, if you listen to Eric Clapton’s “Unplugged” album with headphones or loudspeakers that have a low-enough low-frequency range, you’ll hear a loud thump, thump, thump going along with the music. This is the sound of someone tapping their foot on a temporary stage floor, shaking a vocal microphone. In my not-very-humble opinion, that should never have made it out to the public release. However, my guess is that the speakers it was mastered on didn’t go low enough… (OR, it was an artistic decision, and I would have done it differently.) Assuming that I’m right, then this is a second example where a “better” system sounds “worse”.
Of course, through all of this, I have assumed that your loudspeakers or headphones can produce the signals that we’re talking about in the direction that you’re sitting in, and that those signals are not being masked by other sounds in the room (like phone chargers singing…) However, to complicate things with reality would just be too far to go today…
Conclusions?
I don’t have any, but I have some questions and (as usual) some opinions…
Does a harmon mute on a trumpet produce energy at 50 kHz, if you’re sitting right in front of it? Yes.
Do you want to sit right in front of a trumpet with a harmon mute? Debatable.
Can a high-res audio recording include the sound of a phone charger? Yes.
Do you want to have an expensive recording of a baroque ensemble with obligato phone charger? Probably not – the charger is not in Buxtehude’s original score as far as I can see.
Can you hear the difference between a 7 kHz sine and a 7 kHz square wave? Depends on the speaker / headphone, the listening position, the background noise level, and whether or not you were out clubbing last night. Heads or tails?
Will you feel better by knowing that your file contains “audio” content above 20 kHz? Probably. Placebos have been known to work bigger miracles than this. (But don’t forget the stuff I said about sampling rate converters earlier…)
Back in Part 5 of this series, I described an example of a pretty typical / normal signal flow for an audio signal that you’re playing from a streaming service to a “smart-ish” loudspeaker in your house. If you read through that list, you’ll see that I mentioned that the signal might be sampling-rate converted two times (once in your player, and once again in your loudspeaker or headphones).
Let me say something very clearly, before we go any further:
There’s no guarantee that this is happening. For example, many players don’t sampling-rate convert the signal if the device they’re sending the signal is compatible with the sampling rate of the signal. However, many players do sampling-rate convert the signal – and many devices (like DACs, for example) are not compatible with all sampling rates, so the player is forced to do something about it.
Sampling rate conversion is not necessarily a bad thing. There are many good sampling rate converters out there in the world. In fact, you can use a high-quality sampling rate converter to reduce problems with jitter coming in from an “upstream” device or transmission path.
However, sampling rate conversion is not necessarily a good thing either… so the more of them you have in your audio signal path, the better you want them to be. In an optimal case, the artefacts caused by the sampling rate converter will not be the “weakest link” in the audio chain.
However, this last statement is very easy to mis-interpret, as I alluded to in Part 6. The problem is that, if I say “I have a sampling rate converter with a THD+N of -100 dB relative to the signal level” this might look pretty good. However, if the signal and the SRC artefacts are in COMPLETELY different frequency bands, and you’re playing the signal out of a loudspeaker that can’t produce the signal (say, because it’s too low in frequency) then 100 dB might not be nearly good enough. In other words, it’s not a mere numbers-game… you have to know how to interpret the data…
A what?
Maybe we should first back up a little and talk about what a sampling rate converter is. As you saw in Part 1, at its most basic level, LPCM digital audio is just a way of describing a signal by storing a long string of measurements that were made at a regular time interval. Each of those measurements is called a “sample” and the rate at which you measure the samples (per second) is called the “sampling rate”. A CD, for example, uses a standard sampling rate of 44,100 samples per second, or 44.1 kHz. Other systems use other rates.
If you want to listen to a CD on a loudspeaker with built-in digital processing, and the loudspeaker happens to have an internal sampling rate that is NOT 44.1 kHz (let’s say that it’s 48 kHz), then you need to somehow convert the sampling rate from 44.1 kHz to 48 kHz to get things to work properly. (This is a little like having a gearbox in a car – your engine does not turn at the same speed as your wheels – you put gears in-between to convert the rotational speed of the engine to the rotational speed of the wheels.)
One sneaky way to do this is to use an analogue connection – you convert the 44.1 kHz digital signal to an analogue one using a DAC, and then re-sample the analogue signal using an ADC running at 48 kHz. This is simple, and (if you choose your DAC and ADC properly) potentially a really good solution. In the “old days” (up to the 1990s) before digital SRCs became really good, this was the best way to do it (assuming you had access to some decent gear).
There are many ways to make a fully-digital SRC. For example:
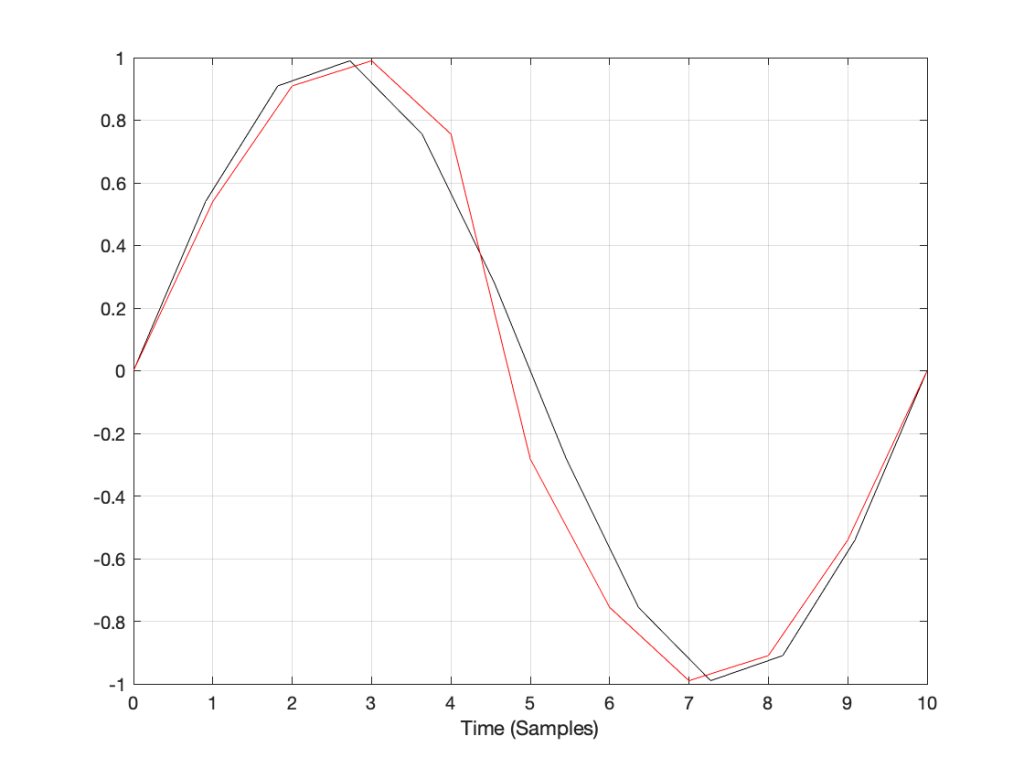
Let’s say that you have an audio signal that’s been sampled at some sampling rate that we’ll call “Fs1” (for “Sampling Frequency 1”) , as is shown in Figure 1.
Figure 1: A signal recorded at some sampling rate.
You then want to have the same signal, represented at a different sampling rate, which we’ll call Fs2. The old signal (in black) and the new sampling rate (the red dots and the gridlines) can be seen in Figure 2.
Figure 2: The original signal at Fs1 and the new samples that we want to create (in red) at Fs2.
How do we do this? One way is to draw straight lines between the original samples, and calculate the values at the point on the line that corresponds with the time of the new samples. This is called “linear interpolation” (because it’s based on drawing straight lines between the original samples), and it’s shown in Figure 3.
Figure 3: An example of linear interpolation for converting to the new sampling rate.
A better way to do this is to use some fancy math to calculate where the signal would be after the reconstruction filter smoothed it back to the original (band-limited) input. There are different ways to do this (in other words, different mathematical strategies) that are outside the scope of this posting, however, I’ve shown an example of a piecewise cubic spline interpolation implementation in Figure 4, below.
Figure 4: An example of piecewise cubic spline interpolation for converting to the new sampling rate.
However, let’s say that:
you’ve been given the job of building a sampling rate converter, but
you think that the examples I gave above are way to complicated…
What do you do? One possibility is to look at the sample value that you want to output, find the closest sample (in time) in the original signal, and use that. This is a technique commonly called “nearest neighbour” for obvious reasons – and it’s one of the worst-performing SRC strategies you can use. An example of this is shown in Figure 5, below. Notice that the new values (the red circles) are identical to the closest original value
Figure 5: An example of “nearest neighbour” interpolation for converting to the new sampling rate. Note that each new values in red is a copy of the closest value in black.
If we look at these two signals without the sample values, we’ll see some pretty nasty distortion in the time domain, as shown in Figure 6.
Figure 6: The same signals shown in Figure 5 without the circles.
So what?
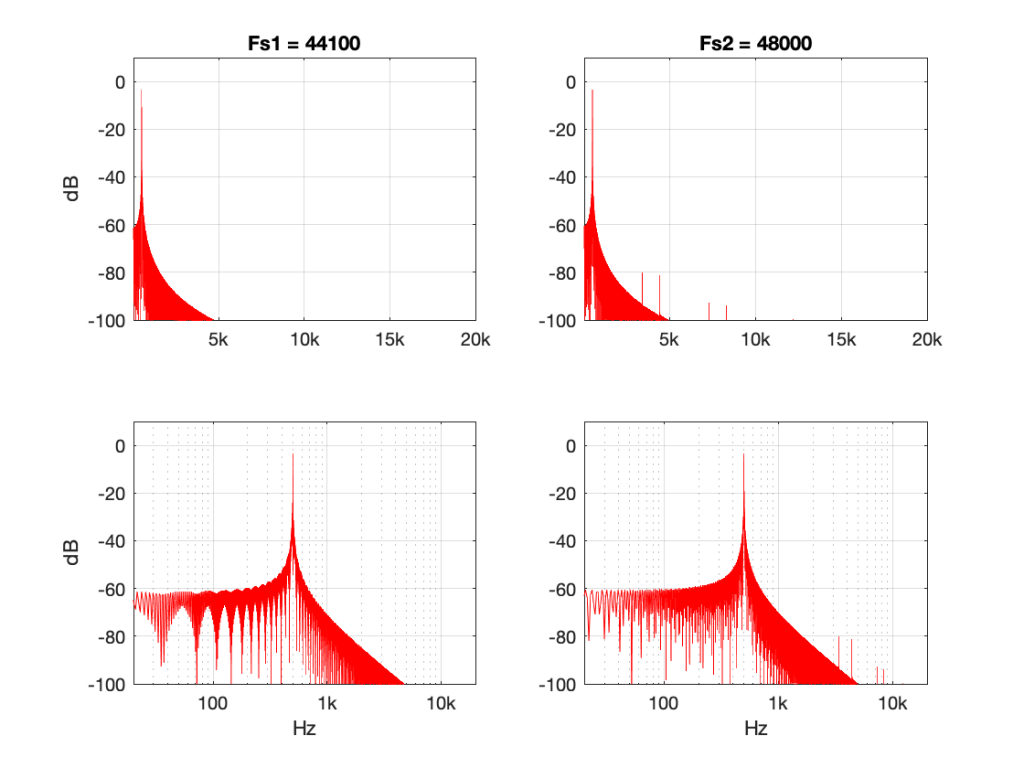
The plots above show the results of good and bad SRCs in the time domain, but what does this look like in the frequency domain? Let’s take a couple of specific examples.
Figure 7: 500 Hz sine tone at 0 dB FS, Linear interpolation from 44.1 kHz to 48 kHz.Figure 8: 500 Hz sine tone at 0 dB FS, Piecewise cubic spline interpolation from 44.1 kHz to 48 kHz.
Figures 7 and 8 look almost identical. There are the windowing artefacts of the frequency analysis that I’m doing are larger than most of the artefacts caused by the interpolation implementations. However, you may notice a couple of spikes sticking up between 1 kHz and 10 kHz in Figure 7. These are the most obvious frequency-domain artefacts of the distortion caused by linear interpolation. Notice however, that those artefacts are about 80 dB down from the signal – so that’s pretty good for a cheap implementation.
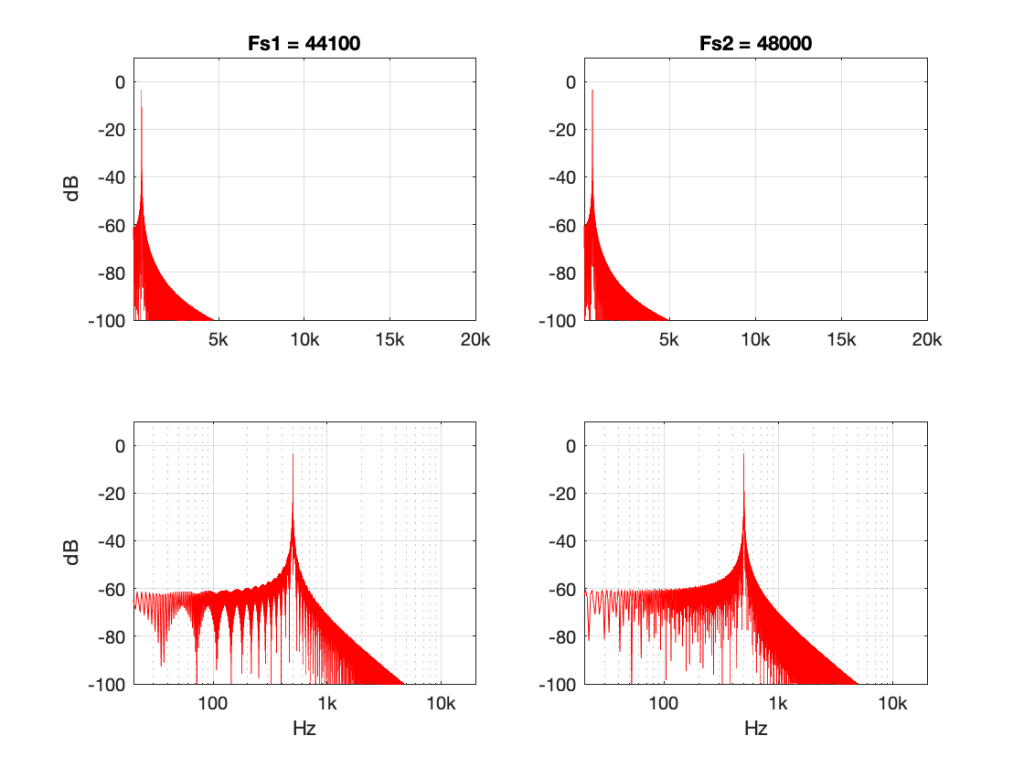
However, let’s look at the same 500 Hz tone converted using the “nearest neighbour” strategy.
Figure 9: 500 Hz sine tone at 0 dB FS, “nearest neighbour” interpolation from 44.1 kHz to 48 kHz.
Now you can see that things have really fallen apart The artefacts are almost up to 40 dB below the signal level, and they’re quite far away in frequency, so they’ll be easy to hear. Also remember that the artefacts that are generated here are inside the audio band, so they will not be eliminated later in the chain by a reconstruction filter in a DAC, for example. They’re there to stay.
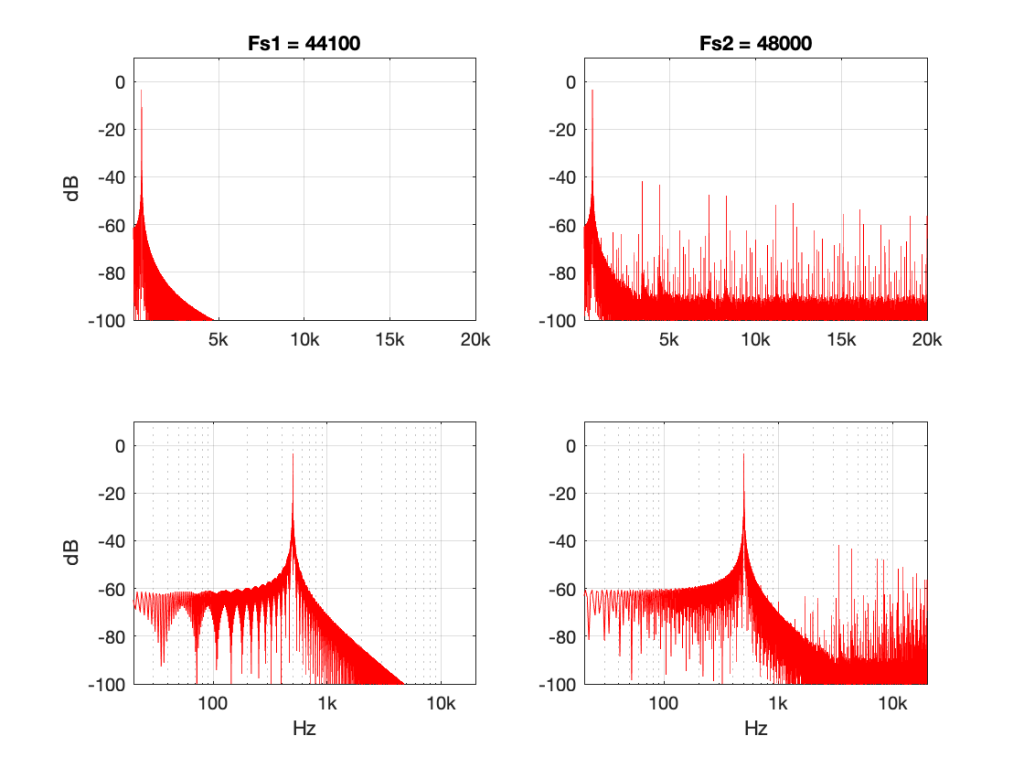
There’s one more interesting thing to consider here. Let’s try the same nearest neighbour algorithm, converting between the same two sampling rates, but I’ll put in signals at different frequencies.
Figure 10: 50 Hz sine tone at 0 dB FS, “nearest neighbour” interpolation from 44.1 kHz to 48 kHz.Figure 11: 5 kHz sine tone at 0 dB FS, “nearest neighbour” interpolation from 44.1 kHz to 48 kHz.
Figure 10 shows the same system, but the input signal is a 50 Hz sine wave (instead of 500 Hz). Notice that the artefacts are now about 60 dB down (instead of 40 dB).
Figure 11 shows the same system again, but the input signal is a 5 kHz sine wave. Notice that the artefacts are now only about 20 dB down.
So, with this poor implementation of an SRC, the distortion-to-signal ratio is not only dependent on the algorithm itself, but the signal’s frequency content. Why is this?
Think back to the way the “nearest neighbour” strategy works. You’re simply copying-and-pasting the value of the nearest sample. However, the lower the frequency, the less change there is in the signal from sample to sample. So, as your signal’s frequency goes down (more accurately, as it gets further away from the sampling rate), the smaller the error that you create with this system. At 0 Hz, there would be no error, because all of the samples would have the same value.
So, (for example) if your job is to build the SRC in the first place, and you measure it with a 50 Hz tone, you’ll see that the artefacts are 60 dB below the signal and you’ll pat yourself on the back and go to lunch. Then, some weeks later, when the customer complaints start coming in about tweeter distortion, you’ll think it must be someone else’s fault… but it isn’t…
Conclusion
What does this have to do with “High Resolution Audio”? Well, the problem is that most audio gear does not run at crazy-high sampling rates (this is not necessarily a bad thing), so if you play a high-res file, you’re probably sampling rate converting (this is not necessarily a bad thing).
play the signal with a different (e.g. not-high-res) sampling rate to find out if it’s better, OR
buy better gear, OR
at least check for a firmware update.
Note that first recommendation of the three: Because the quality of a sampling rate converter is very dependent upon the relationship between the input and the output sampling rates, it can happen that a “normal” resolution audio signal (say, at 44.1 kHz) will sound better on your particular equipment than a “high” resolution audio signal (say, at 192 kHz) because of this. Of course, the opposite could be true (say, because your gear is running at 48 kHz and it’s easier to get to that from 192 kHz (just multiply by 1/4) than it is to get there from 44.1 kHz (just multiply by 480/441…)
This doesn’t mean that “low-res” is better than “high-res” – it just means that your particular equipment deals with it better. (In the same way that purely from the point of view as a fuel, gasoline might have more energy per litre than diesel fuel, but it’s a terrible choice to put in the tank of a car that’s expecting diesel…)
In Part 2 of this series, I talked about the relationship between the noise floor of an LPCM signal and the number of bits used to encode it.
Assuming that the signal is correctly dithered using TPDF dither with a peak-to-peak amplitude of ±1 LSB, then this means that you can easily calculate the dynamic range of your system with a very simple equation:
Dynamic Range in dB = 6.02 * NumberOfBits – 3
(Note that the sampling rate is not part of this equation… That will be useful information later.)
Normally, we’re lazy and we say 6 times the number of bits -3 for the dither – but if you’re really lazy, you leave out the -3 as well.
So, this means that, in a 16-bit system, the noise floor is 93 dB below a sine wave at full scale (6 * 16 -3 = 93) and for a 24-bit system, the noise floor is 141 dB below a sine wave at full scale (you do the math as practice).
Also, we can generalise and say that “adding 1 bit halves the level of the noise floor” (because -6 dB is the same as multiplying by 0.5). However, this is only part of the story.
The noise that’s generated by dither has a “white” characteristic. This means that there is an equal probability of getting some energy per bandwidth (or some say “per Hertz”) over a period of time. This sounds a little complicated, so I’ll explain.
Noise is random. This means that you may or may not get energy at, say 1 kHz, in a given short measurement. However, if you measure white noise for long enough, you’ll eventually see that you got something in every frequency band. Also, you’ll see that, if you look back over the entire length of your measurement of white noise, you got the same amount of energy in the band from 100 Hz to 200 Hz as you did in the band from 1000 Hz to 1200 Hz and the band from 10,000 Hz to 10,200 Hz. (Each of those bandwidths is 200 Hz wide).
There are now two things to discuss:
This distribution of energy is not like the way we hear things. We don’t hear the distance between 100 Hz and 200 Hz as the same distance as going from 1,000 Hz to 1,200 Hz. We hear logarithmically, which means that we hear in multiples of frequency, not additions of bandwidth. So, to use 100 Hz – 200 Hz sounds like the same “distance” as 1,000 Hz to 2,000 Hz. This is why white noise sounds like it is “bright” – or it has emphasis on the high frequencies. If you have a system that has a flat response from 0 to 20,000 Hz, and you play white noise through it, you have the same amount of energy in the top octave (10 kHz to 20 kHz) as you do in all of the octaves below – which is why we hear this as “top-heavy”.
If you had two bands of white noise with equal levels, and let’s say that one ranges from 100 Hz to 200 Hz, and the other is 1000 Hz to 1200 Hz, then the output level of the two of them together will be 3 dB louder than the output level of either of them alone. This is because their powers add together instead of their amplitudes (because the two signals are unrelated to each other).
Let’s put all this (and one or two other things) together:
We know from a previous part in this series that an LPCM digital audio system cannot have signals higher than the Nyquist frequency – 1/2 the sampling rate.
TPDF dither is white noise at a total level that is (6.02 * NumberOfBits – 3) dB below full-scale.
If you add white noise signals with equal levels but different bandwidths, you get a 3 dB increase over the level of just one of them
This means that,
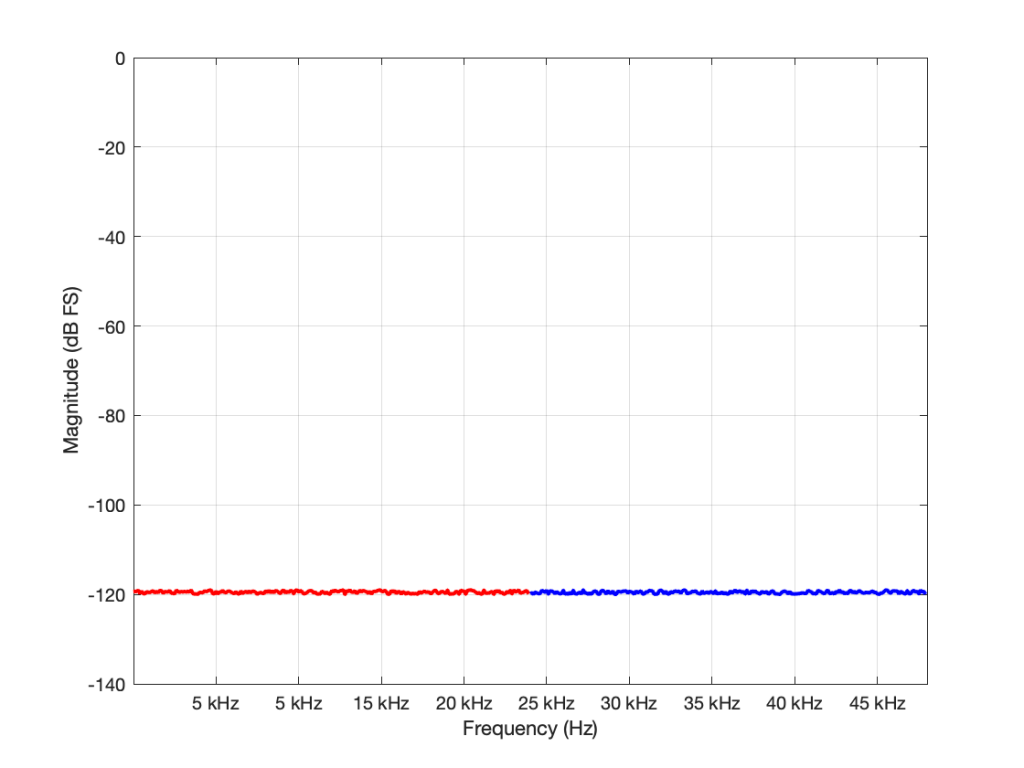
if I have a 16-bit, TPDF dithered LPCM audio signal with a sampling rate of 48 kHz, it has a noise floor that is 93 dB below full scale, and that noise has a white characteristic with a bandwidth of 24 kHz (the Nyquist frequency). There will be no noise above that frequency coming out of the system.
if I have a 16-bit, TPDF dithered LPCM audio signalwith a sampling rate of 192 kHz, it has a noise floor that is 93 dB below full scale, and that noise has a white characteristic with a bandwidth of 96 kHz (the Nyquist frequency). There will be no noise above that frequency coming out of the system.
So, the two systems have the same noise floor level overall, but with very different bandwidths… What does this mean?
Well, let’s start by looking at the level of the noise floor in the 48 kHz system (so the noise “only” extends to 24 kHz).
If I double the sampling rate (to 96 kHz), I double the bandwidth of the noise without changing its level, so this means that the portion of the noise that “lives” in the 0 Hz – 24 kHz region drops by 3 dB (because I’m ignoring the top half of the signal ranging from 24 kHz to 48 kHz in the 96 kHz system.
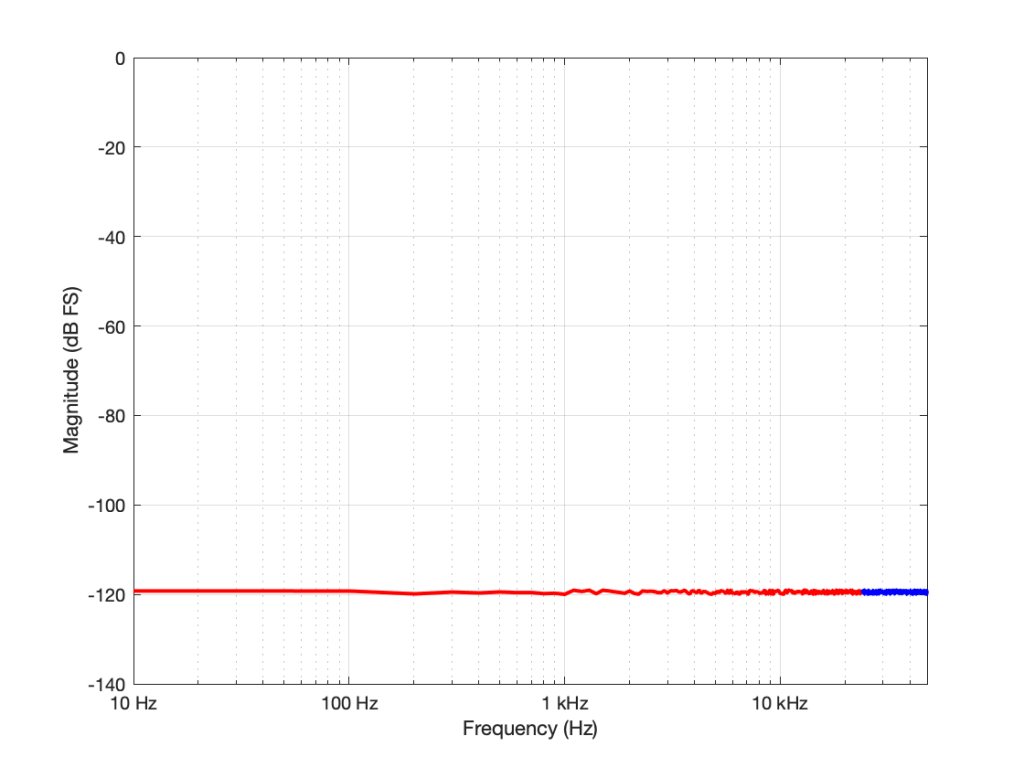
Figure 1: The noise floor caused by TPDF dither in a 16-bit LPCM system with a sampling rate of 96 kHz. The total power of the noise drawn in red is the same as the total power of the noise drawn in blue. But notice that this is plotted on a linear scale for frequency.Figure 1: Re-plotted on a logarithmic scale for the frequency. To us, the top octave is not so important, but to a measurement device, it’s half the signal…
If I had multiplied the original sampling rate by 4 (to 192 kHz) I multiply the bandwidth of the noise by 4 as well (to 96 kHz). This means that the overall level of the noise from 0 to 24 kHz is now 6 dB down from the original version.
In other words: if I multiply the sampling rate by two, but I don’t increase the bandwidth of the noise floor that I’m interested in (say I only care about 20 Hz – 20 kHz), then its level drops by 3 dB.
So what?
Well, you could jump to the conclusion that this proves that higher sampling rates are better. However, that would be a bit (ha hah) premature. Consider that, if you want to drop the (band-limited) noise floor by 6 dB, you have to quadruple the sampling rate – and therefore quadrupling the data rate (and therefore the disc storage, the bandwidth of the transmission system, the error rate, and so on…) A 400% increase in the data is not insignificant.
OR, you could just add one more bit – going from 16 bits to 17 bits will give you the same result with a data increase of only 6.25% – a much smarter decision, no?
The Real World
This little analysis above makes a basic (and possibly incorrect) assumption. The assumption is that, by quadrupling the sampling rate, all other components in the system will remain predictably identical. This may not be true. For example, many DACs (especially older ones) exhibit an increase in their own noise floor when you use them at a higher sampling rate. So, it could be that the benefit you get theoretically is negated by the detriment that you actually get. This is just one example of a flaw in the theory – but it’s a very typical one – especially if you’re building a product instead of just using one.
P.S.
You may have looked at Figures 1 or 2 and are wondering why, if the noise floor is at -93 dB FS in a 16-bit system, I plotted it around -120 dB FS (give or take). The reason is related to the explanation I just gave above. I said in the captions that it’s from a 96 kHz system. This means that the noise extends to the Nyquist frequency at 48 kHz, and that total level is at -93 dB FS. We also know that, if I keep the noise the same, but half the bandwidth that I’m looking at, the level drops by 3 dB. Therefore I can either do math or I can make the following table:
Bandwidth of noise measurement in Hz
Level in dB FS
48,000
-93
24,000
-96
12,000
-99
6,000
-102
3,000
-105
1,500
-108
750
-111
375
-114
187.5
-117
93.75
-120
If you look carefully at the figures, you’ll see that there’s a point every 100 Hz. (It’s most easily visible in the low-frequency range of Figure 2.) So, the level of the noise that I see on a magnitude response plot like this is not only dependent on the noise level itself, but the bandwidths of the divisions that I’ve used to slice it up. In my case, the bandwidth per “slice” is about 100 Hz, so the noise level of each of those little contributors is at about -120 dB FS. If I had used slices only 50 Hz wide, it would show up at -123 instead…